
json类型的字段的内容在mysql中是按text类型存储的。
官方文档地址:

json数据类型: https://dev.mysql.com/doc/refman/8.0/en/json.html
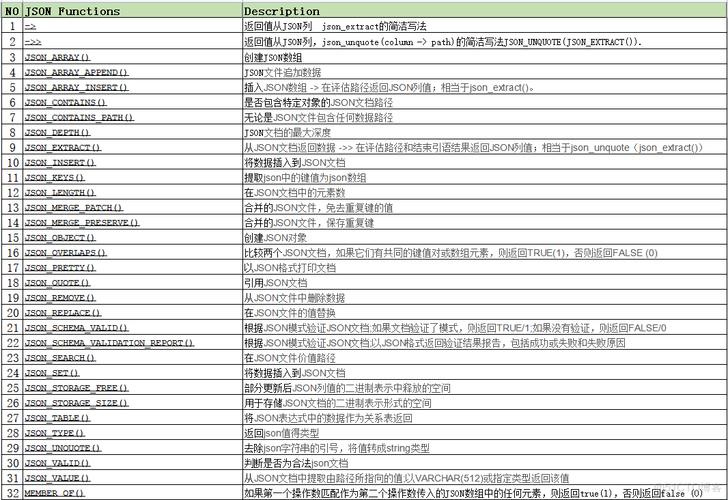
json类型搜索的函数: https://dev.mysql.com/doc/refman/8.0/en/json-search-functions.html
给json类型创建索引: https://dev.mysql.com/doc/refman/8.0/en/create-index.html#create-index-multi-valued
本文内容基于 win10+MySQL8.0.28 + MySQL workbench 环境编写。
mysql的JSON类型支持key-value及json数组格式,本文紧张研究json数组格式,运用处景为信息的单、复选择项记录在筛选页面的过滤。
基本用法
数据转换
-- key-value格式
SELECT CAST('{"deptName": "部门5", "deptId": "5", "deptLeaderId": "5"}' AS json) AS `key_value_format`
-- json数组格式
SELECT CAST( '[1,2,3]' AS json) AS `json_array_format`
key-value格式的查询
CREATE TABLE `dept` (
`id` INT UNSIGNED NOT NULL,
`dept` VARCHAR(255) DEFAULT NULL,
`json_value` JSON DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO `dept`(id, dept, json_value)
VALUES(1,'部门1','{"deptName": "部门1", "deptId": 1, "deptLeaderId": 3}')
,(2,'部门2','{"deptName": "部门2", "deptId": 2, "deptLeaderId": 4}')
,(3,'部门3','{"deptName": "部门3", "deptId": 3, "deptLeaderId": 5}')
,(4,'部门4','{"deptName": "部门4", "deptId": 4, "deptLeaderId": 5}')
,(5,'部门5','{"deptName": "部门5", "deptId": 5, "deptLeaderId": 5}');
-- 查询
SELECT FROM `dept` WHERE json_value->'$.deptLeaderId' IN (5, 3);
json数组格式查询
-- 必须全部包含
SELECT
FROM (
SELECT JSON_ARRAY(1,2,3,4,5,6,7,8) AS ids
) AS a
WHERE JSON_CONTAINS(a.ids, json_array(4,3));
-- 只要包含一个即可
SELECT
FROM (
SELECT JSON_ARRAY(1,2,3,4,5,6,7,8) AS ids
) AS a
WHERE JSON_OVERLAPS(a.ids, json_array(4,13));
索引
-- key-value格式
CREATE TABLE `employees` (
`student_id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`data` JSON,
INDEX `IX_name`((data->>'$.name'))
) ENGINE=InnoDB;
-- json数组格式,要建立多值索引
CREATE TABLE `students` (
`student_id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`class_ids` JSON COMMENT '所有的课程id的数组',
INDEX `IX_classIds`( (CAST(`class_ids` AS UNSIGNED ARRAY)) )
) ENGINE=InnoDB;
更多信息请参考官方文档。
key-value格式下的某一个key仍旧可以利用json数组, 并建立多值索引
业务仿照测试
每一个信息对应一个分类(category_id),每个分类下有多个项目(category_item_id),每个项眼前有多个选项(item_option_id),项目可能是多选也可能是单选,把所选的选项id记录到字段value中。
信息的单、复选择项记录,我们之前利用的是一行一行的记录,但是这个在列表页过滤时,可能会将这个表多次innner join查询以过滤所有选择的项都要涌现。
我们建两个表,一个是原始的一行一行记录格式,一个利用json格式保存所有数据.
-- 原始表: 一行一行记录
CREATE TABLE `info_to_category_item_options3` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`category_id` smallint unsigned NOT NULL DEFAULT '0' COMMENT '分类id',
`info_id` int unsigned NOT NULL COMMENT '信息id',
`category_item_id` smallint unsigned NOT NULL DEFAULT '0' COMMENT '分类的项目id',
`item_option_id` mediumint unsigned NOT NULL DEFAULT '0' COMMENT '选中的选项id',
PRIMARY KEY (`id`,`category_id`)
) ENGINE=InnoDB COMMENT='项目选择结果'
/!50100 PARTITION BY HASH (`category_id`) PARTITIONS 10 /;
-- 新表: json格式
CREATE TABLE `info_to_category_item_options4` (
`id` int unsigned NOT NULL AUTO_INCREMENT,
`category_id` smallint unsigned NOT NULL DEFAULT '0' COMMENT '分类id',
`info_id` int unsigned NOT NULL COMMENT '信息id',
`category_item_id` smallint unsigned NOT NULL DEFAULT '0' COMMENT '分类的项目id',
`item_option_ids` JSON COMMENT '选中的选项id的json数组',
PRIMARY KEY (`id`,`category_id`)
) ENGINE=InnoDB COMMENT='项目选择结果'
/!50100 PARTITION BY HASH (`category_id`) PARTITIONS 10 /;
仿照1000w信息的数据插入到原始表
//分类id在100-200之间
$arrCategoryItemIdAll = range(100, 200);
//保存sql的values字句内容
$arrSqlValues = [];
$batchSize = 100;
//批次插入时用来分批的计数
$k = 0;
for ($i = 1; $i <= 10000000; $i++) {
//信息id
$infoId = $i;
//分类id, 从1-200中随机取一个
$categoryId = rand(1, 200);
//随机1-5个项目
$t = rand(1, 5);
if ($t === 1) {
//把稳: 只有一个时返回的是key
$arrCategoryItemId = [$arrCategoryItemIdAll[array_rand($arrCategoryItemIdAll, 1)]];
} else {
$arrCategoryItemId = array_rand($arrCategoryItemIdAll, $t);
}
$arrCategoryItemIdToItemOptionId = [];
foreach ($arrCategoryItemId as $key => $categoryItemId) {
//每个项目随机1-3个选中的属性
$t2 = rand(1, 3);
for ($j = 1; $j <= $t2; $j++) {
$arrCategoryItemIdToItemOptionId[] = [
'category_item_id' => $categoryItemId,
'item_option_id' => $j 100 + rand(10, 50),
];
}
}
foreach ($arrCategoryItemIdToItemOptionId as $row) {
$categoryItemId = $row['category_item_id'];
$item_option_id = $row['item_option_id'];
$arrSqlValues[] = '(' . $categoryId . ', ' . $infoId . ', ' . $categoryItemId . ', ' . $item_option_id . ')';
}
if ($k === $batchSize) {
//达到100个信息的时候批量写入
$sql = 'INSERT INTO `info_to_category_item_options3`(`category_id`,`info_id`,`category_item_id`,`item_option_id`)VALUES'
. implode(',', $arrSqlValues);
echo $sql . PHP_EOL;
$db->query($sql);//数据库类实行sql
//重置
$arrSqlValues = [];
$k = 0;
} else {
$k++;
}
}
if ($k < $batchSize && count($arrSqlValues) > 0) {
echo '不敷100的' . PHP_EOL;
$sql = 'INSERT INTO `info_to_category_item_options3`(`category_id`,`info_id`,`category_item_id`,`item_option_id`)VALUES'
. implode(',', $arrSqlValues);
echo $sql . PHP_EOL;
$db->query($sql);//数据库类实行sql
}
原始表示履行数6000w旁边, 单分区表600w(文件大小200M旁边)
将原始表数据复制到新表
INSERT INTO `info_to_category_item_options4`
(category_id, info_id, category_item_id, `item_option_ids`)
SELECT category_id, info_id, category_item_id, CONCAT('[', GROUP_CONCAT(`item_option_id`), ']') AS `item_option_ids`
FROM info_to_category_item_options3
GROUP BY category_id, info_id, category_item_id;
添加索引
-- 原始表
ALTER TABLE `info_to_category_item_options3`
ADD INDEX IX_categoryId_categoryItemId_itemOptionId(`category_id`, `category_item_id`, `item_option_id`);
-- 新表
ALTER TABLE `info_to_category_item_options4`
ADD INDEX IX_categoryId_categoryItemId_itemOptionIds(`category_id`, `category_item_id`, (CAST(`item_option_ids` AS UNSIGNED ARRAY)));
查询测试
本地测试数据中, 项目选项ID(item_option_id)为131的单独有6800行旁边, 215的有4400行旁边。
1. 多个值的"部分包含"查询
这里我们查询选项id包含131、215个中之一的数据。
-- 原始表
SELECT SQL_NO_CACHE category_id
FROM info_to_category_item_options3
WHERE category_id=98 AND category_item_id=98 AND `value` IN (131, 215)
LIMIT 0,100000;
-- 新表
SELECT SQL_NO_CACHE category_id
FROM info_to_category_item_options4 WHERE category_id=98 AND category_item_id=98
AND JSON_OVERLAPS(`values`, CAST('[131,215]' AS JSON))
LIMIT 0,100000;
在mysql workbench下实行查询,二者都比较快, 但是前者更快。
而且我还创造两个很奇怪的问题:
我本地workbench的配置是默认LIMIT 100,两个查询的SQL都不加LIMIT时,原表的查询返回100行数据,这是符合预期的;但是新表的查询却返回了所有1万多行数据
上面的SQL中返回的字段category_id是在索引中的,不须要再回表查询;但是如果换成不在索引中的info_id,原表的查询由于须要回表会变慢,这是符合预期的;但是新表的查询却仍旧很快,貌似根本不须要回表。而原表和新表的单个分区表(加索引后)的物理文件大小都在340M旁边。
2. 多个值的必须"全部包含"查询
这里我们查询选项id必须包含131和215的数据。
-- 原始表
SELECT SQL_NO_CACHE a.
FROM info_to_category_item_options3 AS a
, info_to_category_item_options3 AS b
WHERE a.category_id=98 AND a.category_item_id=98 AND a.`item_option_id`=131
AND b.category_id=98 AND b.category_item_id=98 AND b.`item_option_id`=215
AND a.info_id=b.info_id;
-- 新表
SELECT SQL_NO_CACHE
FROM info_to_category_item_options4
WHERE category_id=98 AND category_item_id=98
AND JSON_CONTAINS(`item_option_ids`, CAST('[131,215]' AS JSON));
利用原始表查询,韶光很很很长,以至于不得不终止查询。由于inner join的条件字段info_id不在索引中, 须要回表11000多次,
利用新表查询,除了第一次1秒多,别的基本都在0.05秒旁边。
很奇怪的是,新表的查询中,SQL_NO_CACHE 参数失落效了,不然为什么第一次那么慢后面却那么快呢?
那我们现在修正一下原始表的索引:
ALTER TABLE `info_to_category_item_options3`
DROP INDEX IX_categoryId_categoryItemId_itemOptionId,
ADD INDEX IX_categoryId_categoryItemId_itemOptionId(`category_id`, `category_item_id`, `item_option_id`, `info_id`);
修正后,再次实行上面的查询,其性能已经比新表的json格式的快,而且是快3-4倍。
结论
综合本用例的测试结果来看,json数组在这种场景下性能不如传统办法,不建议利用。
原文链接:https://blog.csdn.net/aben_sky/article/details/125690495















