
牛肉丸裹上麻酱后,狠狠嘬一口,都要入嘴了。
产品经理溘然发来。

"线上有些用户不能注册了"
心想着"关我x事,又不是我做的模块",放下手机。
不对,那老哥上星期刚离职了,想到这里,夹住毛肚的手微微抖动。
对面连续发:"还有些用户不能改名"
"如果用上表情符号的话,问题必现"
可以了,这下问题险些直接定位了。
危,速归。
有履历的兄弟们很随意马虎看出,这肯定是由于字符集的缘故。
一、复现问题
我们来大略复现下这个问题。
如果你有一张数据库表,建表sql就像下面一样。
建表sql语句
接下来如果你插入的数据是
insert成功case
能成功。统统正常。
但如果你插入的是
insert失落败case
就会报错。
Incorrect string value: '\xF0\x9F\x98\x81' for column 'name' at row 1
差异在于后者多了个emoji表情。
明明也是字符串,为什么字符串里含有emoji表情,插入就会报错呢?
我们从字符集编码这个话题开始聊起。
二、编码和字符集的关系
虽然我们平时可以在编辑器上输入各种中文英笔墨母,但这些都是给人读的,不是给打算机读的,实在打算机真正保存和传输数据都因此二进制0101的格式进行的。
那么就须要有一个规则,把中文和英笔墨母转化为二进制,比如"debug",打算机就须要把它转化为下图这样。
debug的编码
个中d对应十六进制下的64,它可以转换为01二进制的格式。
于是字母和数字就这样逐一对应起来了,这便是ASCII编码格式。
它用一个字节,也便是8位来标识字符,根本符号有128个,扩展符号也是128个。
也就只能表示下英笔墨母和数字。
这哪里够用。
塞牙缝都不足。
于是为了标识中文,涌现了GB2312的编码格式。为了标识希腊语,涌现了greek编码格式,为了标识俄语,整了cp866编码格式。
这百花齐放的场面,显然不是一个爱写if else的程序员想看到的。
为了统一它们,于是涌现了Unicode编码格式,它用了2~4个字节来表示字符,这样理论上所有符号都能被收录进去,并且它还完备兼容ASCII的编码,也便是说,同样是字母d,在ASCII用64表示,在Unicode里还是用64来表示。
但不同的地方是ASCII编码用1个字节来表示,而Unicode用则两个字节来表示。
比如下图,同样都是字母d,unicode比ascii多利用了一个字节。
unicode比ascii多利用一个字节
我们可以把稳到,上面的unicode编码,放在前面的都是0,其实用不上,但还占了个字节,有点摧残浪费蹂躏,完备能隐蔽掉。如果我们能做到该隐蔽时隐蔽,这样就能省下不少空间,按这个思路,便是就有了UTF-8编码。
编码格式
来总结下。
按照一定规则把符号和二进制码对应起来,这便是编码。而把n多这种已经编码的字符聚在一起,便是我们常说的字符集。
比如utf-8字符集便是所有utf-8编码格式的字符的合集。
字符和字符集的关系
三、mysql的字符集
想看下mysql支持哪些字符集。可以实行 show charset;
数据库支持哪些字符集
上面这么多字符集,我们只须要关注utf8和utf8mb4就够了。
utf8和utf8mb4的差异
上面提到utf-8是在unicode的根本上做的优化,既然unicode有办法表示所有字符,那utf-8也一样可以表示所有字符,为了避免稠浊,我在后面叫它大utf8。
而从上面mysql支持的字符集的图里,我们看到了utf8和utf8mb4。
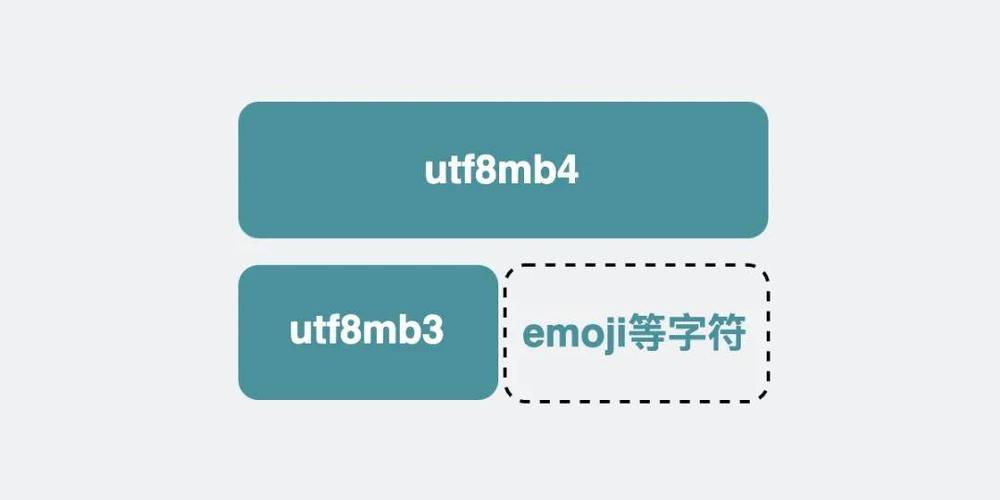
先说utf8mb4编码,mb4便是most bytes 4的意思,从上图最右边的Maxlen可以看到,它最大支持用4个字节来表示字符,它险些可以用来表示目前已知的所有的字符。
再说mysql字符集里的utf8,它是数据库的默认字符集。但把稳,此utf8非彼utf8,我们叫它小utf8字符集。为什么这么说,由于从Maxlen可以看出,它最多支持用3个字节去表示字符,按utf8mb4的命名办法,准确点该当叫它utf8mb3。
不好意思,有被严谨到的兄弟们,评论区扣个"严谨"。
它就像是阉割版的utf8mb4,只支持部分字符。比如emoji表情,它就不支持。
utf8mb3和utf8mb4的关系
而mysql支持的字符集里,第三列,collation,它是指字符集的比较规则。
比如,"debug"和"Debug"是同一个单词,但它们大小写不同,该不该判为同一个单词呢。
这时候就须要用到collation了。
通过SHOW COLLATION WHERE Charset = 'utf8mb4';可以查看到utf8mb4下支持什么比较规则。
utf8mb4字符集比较规则
如果collation = utf8mb4_general_ci,是指利用utf8mb4字符集的条件下,挨个字符进行比较(general),并且不区分大小写(_ci,case insensitice)。
这种情形下,"debug"和"Debug"是同一个单词。
比拟规则-大小写不敏感
如果改成collation=utf8mb4_bin,便是指挨个比较二进制位大小。
于是"debug"和"Debug"就不是同一个单词。
比拟规则-大小写敏感
那utf8mb4比拟utf8mb3有什么劣势吗?
我们知道数据库表里,字段类型如果是char(2)的话,里面的2是指字符个数,也便是说不管这张表用的是什么编码的字符集,都能放上2个字符。
而char又是固定长度,为了能放下2个utf8mb4的字符,char会默认保留24(maxlen=4)= 8个字节的空间。
如果是utf8mb3,则会默认保留 2 3 (maxlen=3) = 6个字节的空间。也便是说,在这种情形下,utf8mb4会比utf8mb3多利用一些空间。
但这真的无关紧要,如果我不用char,用varchar就好了,varchar不是固定长度,也就没有上面这些麻烦事了。
以是我个人认为,utf8mb4比起 utf8mb3 险些没有劣势。
如何查看数据库表的字符集
如果我们不知道自己的表是用的哪种字符集,可以通过下面的办法进行查看。
查看数据库表的字符集
四、再看报错缘故原由
到这里,我们回到文章开头的问题。
由于数据库表在建表的时候利用 DEFAULT CHARSET=utf8, 相称于指定了utf8mb3字符集格式。
而在实行insert数据的时候,又不讲武德,加入了emoji表情这种utf8mb4才能支持的字符,mysql识别到这是utf8mb3不支持的字符,于是忍痛报错。
要修复也很大略,实行下面的sql语句,就可以把数据库表的字符集改成utf8mb4。
ALTER TABLE user CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
答应我,往后建表,我们都无脑选utf8mb4。
选utf8除了在char字段场景下会比utf8mb4轻微省一点空间外,险些没任何好处。
这点空间省下来了能提高你的绩效吗?不能。
但如果因此炸雷了,那你号就没了。
总结
ASCII编码支持数字和字母。大佬们为了支持中文引入了GB2312编码格式,其他国家的大佬们为了支持更多措辞和符号,也引入了相应的编码格式。为了统一这些各种编码格式,大佬们又引入了unicode编码格式,而utf-8则在unicode的根本上做了优化,压缩了空间。
mysql默认的utf8字符集,实在只是utf8mb3,并不完全,当插入emoji表情等分外字符时,会报错,导致插入、更新数据失落败。改成utf8mb4就好了,它能支持更多字符。
mysql建表时如果不知道该选什么字符集,无脑选utf8mb4就行了,你会感谢我的。
末了
原来A同学设计这张表的时候非常大略,也有字符串类型的字段,但字段含义决定了肯定不会有奇奇怪怪的字符,用utf8很合理,还省空间。
后来交卸给了B同学,B同学在这根本上加过非常多的字段,离职前末了一个需求加的这个名称字段,所幸并没炸雷。末了到了我这里。
好一个击鼓传雷。
有点东西哦。
那么问题来了。
这样的一个事件,复盘会一开,会挂P几呢?
作者丨小白
来源丨公众号:网管叨bi叨(ID:kevin_tech)
dbaplus社群欢迎广大技能职员投稿,投稿邮箱:editor@dbaplus.cn















