
电影推举系统
先容电影推举系统自机器学习时期开始以来不断发展,进化到目前的变换器和向量数据库的最新阶段。

从基于支持向量机的传统推举系统开始,我们现在已经进入了变压器的天下。在本文中,我们将磋商如何有效地将数千个视频文件存储在向量数据库中,以实现最佳推举引擎。
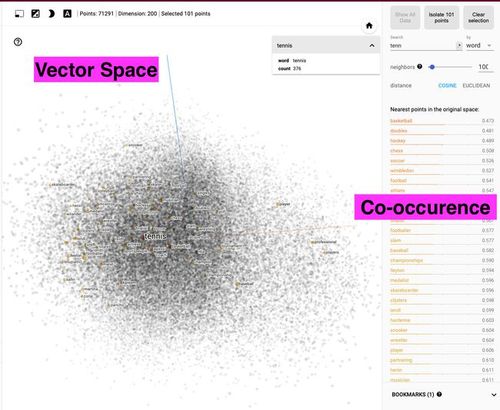
Out of the numerous vector databases available, we will focus on Qdrant DB due to its unique property — the HNSW ANN search algorithm, as discussed in my previous article.
让我们开始吧!
机器学习算法,如支持向量机 (SVM),随着变换器的引入而发展成为传统的电影推举系统。电影推举系统利用机器学习算法来预测用户对电影的偏好和评分。这些系统可以大致分为三种紧张类型:
传统推举系统
各种机器学习技能,例如基于实例的学习中的最近邻算法、用于协同过滤的矩阵分解以及利用神经网络的深度学习,都有助于提升推举系统的质量。这些系统面临诸如冷启动问题和数据稀疏性等寻衅。伦理考虑、可扩展性以及高下文信息的整合进一步增加了设计有效和负任务的推举系统的繁芜性。
向量数据库的入门向量数据库已成为高效相似性搜索的有用工具。在电影推举系统中利用这种相似性搜索特殊有用,其目标是找到与用户已经不雅观看并喜好的电影相似的电影。通过将电影表示为高维空间中的向量,我们可以利用间隔度量 (例如余弦相似度或欧几里得间隔) 来识别彼此 ‘靠近’ 的电影,从而表明相似性。
向量数据库的事情事理
随着电影和用户数量的增加,数据库的规模也在扩大。向量数据库旨在处理大规模数据,同时保持高查询性能。这种可扩展性对付电影推举系统至关主要,尤其是那些被拥有弘大电影库和用户根本的大型流媒体平台利用的系统。
在这种情形下,我们将利用Qdrant数据库,由于它利用快速的近似最近邻搜索,特殊是带有余弦相似度搜索的HNSW算法。
有关 Qdrant DB 的更多详细信息,请访问 网站.
有关HNSW算法和余弦相似度搜索事情事理的更多细节,请参阅此文章。
Qdrant 数据库
推举系统架构在我们利用向量数据库时,让我们理解推举系统在这里是如何事情的。电影的推举是基于模型在一部电影中不雅观察到的情绪。架构分为两个部分:
候选天生候选天生是推举系统运作中最主要的部分。面对数十万的视频,初步步骤涉及根据口音或措辞过滤内容。例如,对付一部西班牙电影,它将在推举中仅显示西班牙电影。这个过滤过程被称为启示式过滤。
候选天生
第二步是根据转录文本将视频转换为文本嵌入。Hugging Face 上有许多可用的模型可以将文本信息转换为向量嵌入。然而,要获取文本信息,我们首先须要提取视频的音频格式。利用像 Whisper 或 SpeechRecognition 的音频转文本模型,我们可以获取文本信息作为转录。
利用嵌入模型,我们将把文本信息转换为向量嵌入。将这些向量存储在安全可靠的数据库中是至关主要的。此外,向量数据库简化了我们的相似性搜索。我们将把嵌入保存到Qdrant数据库中。
在非常短的相应韶光内,我们将根据Qdrant数据库的余弦相似度搜索得到相似的视频。这些相似视频的检索构成了候选天生的末了一步。
重新排序重新排序实质上是在推举系统中进行的,目的是根据文本信息中表达的情绪来排列电影。在大措辞模型的帮助下,我们将能够得到文本信息的见地分数。根据见地分数,电影将被重新排序以进行推举。
重新排序
Qdrant的代码实现在理解推举系统的架构后,现在是时候将理论在代码中实现。我们理解了理论,我们知道如何剖析电影剧本的情绪,但是关键问题是如何将mp4格式的视频文件转换为文本嵌入。
对付这个代码实现,我从YouTube提取了30个电影预报片。我们须要安装将会进一步利用的主要库。
!pip install -q torch !pip install -q openai moviepy !pip install SpeechRecognition !pip install -q transformers !pip install -q datasets !pip install -q qdrant_client
然后我们将导入在代码实现中所需的所有程序包。
import os import moviepy.editor as mp import os import glob import speech_recognition as sr import csv import numpy as np import pandas as pd from qdrant_client import QdrantClient from qdrant_client.http import models from transformers import AutoModel, AutoTokenizer import torch
现在,我们将创建一个目录,在那里我们将保存我们的音频转录。
# 指定你的路径 path = "/content/my_directory" # 创建目录 os.makedirs(path, exist_ok=True)
在创建目录后,我们将利用以下代码将视频转换为文本信息:
# 视频文件所在目录 source_videos_file_path = r"/content/drive/MyDrive/qdrant_videos" # 存储音频文件的目录 destination_audio_files_path = r"/content/my_directory/audios" # 存储转录内容的 CSV 文件 csv_file_path = r"/content/my_directory/transcripts.csv" # 如果目标目录不存在,创建目录 os.makedirs(destination_audio_files_path, exist_ok=True) # 初始化识别器类(用于识别语音) r = sr.Recognizer() # 以写模式打开 CSV 文件 with open(csv_file_path, 'w', newline='') as csvfile: # 创建一个 CSV 编写器 writer = csv.writer(csvfile) # 写入表头行 writer.writerow(["视频文件", "转录内容"]) # 逐帧处理视频 for video_file in glob.glob(os.path.join(source_videos_file_path, '.mp4')): # 将视频转换为音频 video_clip = mp.VideoFileClip(video_file) audio_file_path = os.path.join(destination_audio_files_path, os.path.basename(video_file).replace("'", "").replace(" ", "_") + '.wav') video_clip.audio.write_audiofile(audio_file_path) # 将音频转录为文本 with sr.AudioFile(audio_file_path) as source: # 读取音频文件 audio_text = r.listen(source) # 将语音转换为文本 try: transcript = r.recognize_google(audio_text) except sr.UnknownValueError: print("Google 语音识别无法理解音频") transcript = "缺点:无法理解音频" except sr.RequestError as e: print("无法从 Google 语音识别做事要求结果;{0}".format(e)) transcript = "缺点:无法从 Google 语音识别做事要求结果;{0}".format(e) # 将转录内容写入 CSV 文件 writer.writerow([video_file, transcript])
然后,我们将看到以数据框格式呈现的成绩单。
data = pd.read_csv('/content/my_directory/transcripts.csv') data.head()
有些转录内容是“SpeechRecognition”无法理解的,因此我们将从数据框中删除该行。
data = data[~data['Transcript'].str.startswith('缺点')] data.head()
现在,我们将创建一个 QdrantClient 实例,利用内存数据库。
client = QdrantClient(":memory:")
我们将创建一个凑集,在个中存储我们的向量嵌入,利用余弦相似度搜索来丈量间隔。
my_collection = "text_collection" client.recreate_collection( collection_name=my_collection, vectors_config=models.VectorParams(size=768, distance=models.Distance.COSINE) )
我们将利用一个预演习模型来帮助我们从数据集中提取嵌入层。我们将利用 transformers 库和 GPT-2 模型来实现这一目标。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") tokenizer = AutoTokenizer.from_pretrained('gpt2') model = AutoModel.from_pretrained('gpt2')#.to(device) # 切换到GPU
我们须要提取电影名称并创建一个新列,以便我们知道哪些嵌入属于哪个电影。
def extract_movie_name(file_path): file_name = file_path.split("/")[-1] # 获取路径的末了一部分 movie_name = file_name.replace(".mp4", "").strip() return movie_name # 运用该函数创建新列 data['Movie_Name'] = data['Video File'].apply(extract_movie_name) # 显示数据框 data[['Video File', 'Movie_Name', 'Transcript']]
现在,我们将创建一个赞助函数,通过它获取每个电影预报片的转录文本的嵌入。
def get_embeddings(row): tokenizer = AutoTokenizer.from_pretrained('gpt2') tokenizer.add_special_tokens({'pad_token': '[PAD]'}) inputs = tokenizer(row['Transcript'], padding=True, truncation=True, max_length=128, return_tensors="pt") # 禁用以下操作的梯度打算。 with torch.no_grad(): outputs = model(inputs).last_hidden_state.mean(dim=1).cpu().numpy() # 返回打算得到的嵌入。 return outputs
接下来,我们将把嵌入函数运用到我们的数据集中。之后,我们将保存嵌入,以便不必再次加载它们。
data['embeddings'] = data.apply(get_embeddings, axis=1) np.save("vectors", np.array(data['embeddings']))
插入 'embeddings' 列后的数据
现在,我们将为每个电影剧本创建一个包含元数据的有效载荷。
payload = data[['Transcript', 'Movie_Name', 'embeddings']].to_dict(orient="records")
我们将创建一个赞助函数,用于对标记嵌入进行均值池化。然后,我们将遍历转录列中的每个转录,以创建文本嵌入。
# 设置向量嵌入的期望大小 expected_vector_size = 768 # 定义一个用于令牌嵌入的均值池化函数 def mean_pooling(model_output, attention_mask): # 从模型输出中提取令牌嵌入 token_embeddings = model_output[0] # 扩展把稳力掩码以匹配令牌嵌入的大小 input_mask_expanded = (attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()) # 考虑把稳力掩码打算令牌嵌入的和 sum_embeddings = torch.sum(token_embeddings input_mask_expanded, 1) # 打算把稳力掩码的和(限定以避免除以零) sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9) # 返回均值池化的嵌入 return sum_embeddings / sum_mask # 初始化一个列表来存储文本嵌入 text_embeddings = [] # 遍历'data'变量中'Transcript'列的每个抄本 for transcript in data['Transcript']: # 敌手本进行标记化,确保添补和截断,并返回PyTorch张量 inputs = tokenizer(transcript, padding=True, truncation=True, max_length=128, return_tensors="pt") # 利用模型实行推理,输入为标记化的内容 with torch.no_grad(): embs = model(inputs) # 利用定义的函数打算均值池化嵌入 embedding = mean_pooling(embs, inputs["attention_mask"]) # 通过修剪或添补以确保嵌入的大小精确 embedding = embedding[:, :expected_vector_size] # 将结果嵌入添加到列表中 text_embeddings.append(embedding)
为了在Qdrant数据库凑集中为每个转录本分配一个显式ID,我们将创建一个ID列表,然后插入ID、向量和有效负载的组合。
ids = list(range(len(data))) # 将PyTorch张量转换为浮点数列表 text_embeddings_list = [[float(num) for num in emb.numpy().flatten().tolist()[:expected_vector_size]] for emb in text_embeddings] client.upsert(collection_name=my_collection, points=models.Batch( ids=ids, vectors=text_embeddings_list, payloads=payload ) )
利用情绪剖析模型,您可以天生一个情绪得分,个中情绪极性在 -1 和 1 之间打算。得分为 -1 表示负面情绪,0 表示中脾气感,1 表示正面情绪。
from textblob import TextBlob def calculate_sentiment_score(text): # 创建一个 TextBlob 工具 blob = TextBlob(text) # 获取情绪极性(-1 到 1,个中 -1 为负面,0 为中性,1 为正面) sentiment_score = blob.sentiment.polarity return sentiment_score # 示例用法: text_example = data['Transcript'].iloc[0] sentiment_score_example = calculate_sentiment_score(text_example) print(f"情绪分数: {sentiment_score_example}")
对付这个例子,结果情绪得分将是 0.75。现在,我们将对 ‘data’ 数据框运用打算情绪得分的赞助函数。
data['情绪分数'] = data['逐字稿'].apply(calculate_sentiment_score) data.head()
您可以对每个电影脚本的向量嵌入取均匀值,并将其与情绪分数结合以得到终极见地分数。
data['avg_embeddings'] = data['embeddings'].apply(lambda x: np.mean(x, axis=0)) data['Opinion_Score'] = 0.7 data['avg_embeddings'] + 0.3 data['Sentiment']
在上面的代码中,我为嵌入分配了更大的权重,由于它们捕捉了语义内容和电影转录之间的相似性。内在内容的相似性在确定总体见地分数时更为关键。 “情绪” 列定义了电影转录的情绪基调。我为其分配了较低的权重,由于情绪作为一个成分,在打算总体见地分数时不如语义内容关键。权重是任意的 (就像我们在拆分数据集时为演习和测试集授予权重一样)。
Then create a movie recommender function, where you pass a movie name and get the desired number of recommended movies.
def get_recommendations(movie_name): # 找到与给定电影名称对应的行 query_row = data[data['Movie_Name'] == movie_name] if not query_row.empty: # 将'Opinion_Score'列转换为NumPy数组 opinion_scores_array = np.array(data['Opinion_Score'].tolist()) # 将'Opinion_Score'向量插入到Qdrant凑集中 opinion_scores_ids = list(range(len(data))) # 将'Opinion_Score'数组转换为列表的列表 opinion_scores_list = opinion_scores_array.reshape(-1, 1).tolist() client.upsert( collection_name=my_collection, points=models.Batch( ids=opinion_scores_ids, vectors=opinion_scores_list ) ) # 根据您想要查找相似电影的见地分数定义查询向量 query_opinion_score = np.array([0.8] 768) # 根据须要调度 # 实行相似性搜索 search_results = client.search( collection_name=my_collection, query_vector=query_opinion_score.tolist(), limit=3) # 从搜索结果中提取电影推举 recommended_movie_ids = [result.id for result in search_results] recommended_movies = data.loc[data.index.isin(recommended_movie_ids)] # 显示推举的电影 print("推举的电影:") print(recommended_movies[['Movie_Name', 'Opinion_Score']]) else: print(f"数据集中未找到电影'{movie_name}'。”) # 示例用法: get_recommendations("Star Wars_ The Last Jedi Trailer (Official)")
通过这一点,我们能够利用Qdrant数据库创建一个电影推举系统。
推举电影与见地评分
结论向量数据库有许多利用场景。在这些利用场景中,电影推举系统通过余弦相似度搜索和大型措辞模型显著提高了性能。
It was fun, exciting, and easy to create a movie recommender system using the Qdrant database.
借助Qdrant的最佳近似最近邻搜索及其处理大负荷的能力,您可以创建自己的数据集,并享受基于向量搜索的电影推举系统的实验。















