
Tasks: 80 total, 1 running, 79 sleeping, 0 stopped, 0 zombie%Cpu(s): 0.3 us, 0.7 sy, 0.0 ni, 92.7 id, 6.3 wa, 0.0 hi, 0.0 si, 0.0 stKiB Mem : 2052544 total, 1453600 free, 162408 used, 436536 buff/cacheKiB Swap: 782332 total, 782332 free, 0 used. 1708652 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 179 root 20 0 0 0 0 S 0.3 0.0 0:00.27 [jbd2/dm-0-+ 493 mongodb 20 0 1102144 78548 36688 S 0.3 3.8 0:26.07 /usr/bin/mo+ 636 mysql 20 0 653808 75932 15548 S 0.3 3.7 0:03.55 /usr/sbin/m+
与进程内存干系的两个指标:VIRT Virtual Memory,虚拟内存、RES Resident Memory,常驻内存,常日叫物理内存。虚拟内存,是指全体进程申请的内存,包括程序本身的占内存、new或者malloc分配的内存等等。物理内存,便是这个进程在主板上内存条那里占用了多少内存。那为什么会有虚拟内存这个东西,C++不是可以操作硬件么,为什么不直策应用物理内存?这得大略理解一下操作系统的内存管理。
当代的打算机都会同时运行N个程序,有N多个进程,这些进程都是独立在运行。如果直策应用物理内存,那就会产生一个问题,进程A申请了内存,进程B也要申请一块内存,但进程B并不知道进程A的存在,就没法担保进程B利用的内存进程A没在用。因此linux下利用内核来管理这些资源,所有进程都只是向内核申请,由内核管理物理内存。而一个进程,可能多次申请、开释内存,或者程序直接当掉没有开释内存,内核为理解决这些繁芜的问题,用一个列表掩护了进程分配的内存,这就叫虚拟内存,然后把虚拟内存映射到物理内存,这就完成了全体内存的管理。而且,内核对内存的映射做了优化,用到时才映射,如下面的图中,进程A的new2这块内存分配了往后,一贯没利用,也就不会映射到物理内存。有很多程序,利用了这个特性。例如,在socket收发时,我们可以分配很大的一块内存(比如16M),避免频繁分配缓冲区,但实际这个socket可能收到的数据块最大只有16k,那内核是不会直接映射16M物理内存的,这样既方便了我们写程序,但又没摧残浪费蹂躏物理内存。

下面写个程序来验证这个问题
#include <cstring>#include <iostream>int main(){#define PAUSE(msg) std::cout << msg << std::endl; std::cin >> p char p; size_t size = 1024 1024 100; char l = new char[size]; PAUSE("new"); memset(l, 1, size / 2); PAUSE("using half large"); memset(l, 1, size); PAUSE("using whole large"); delete []l; PAUSE("del"); return 0;}
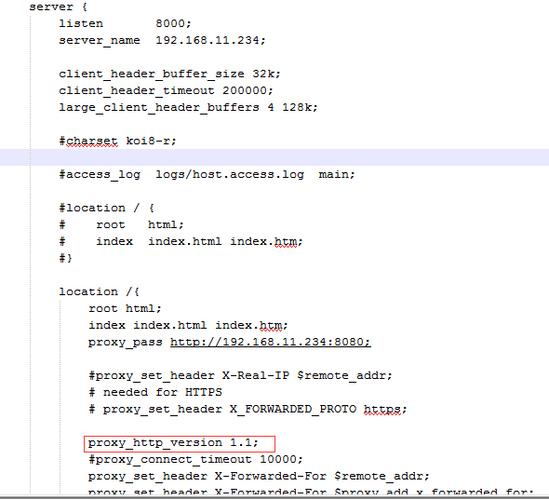
在每次停息时,top的输出结果(RES 1588 54328 105600 3348),解释memset的时候,内核才会映射物理内存。
new 进程号 USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND 25295 root 20 0 108280 1588 1436 S 0.0 0.0 0:00.00 ./a.outusing half large 25295 root 20 0 108280 54328 3096 S 0.0 0.7 0:00.05 ./a.outusing whole large 25295 root 20 0 108280 105600 3156 S 0.0 1.4 0:00.12 ./a.outdel 25295 root 20 0 5876 3348 3156 S 0.0 0.0 0:00.13 ./a.out
以是,通过top查看进程内存时,如果创造VIRT占用很大,解释这个程序用new或者malloc平分派了很多内存,但如果RES不是很大,那就不要慌,可能这只是程序的一个缓存优化(当然也有可能是写这个程序的人用new分配内存时很不合理,分配的值远大于利用值),实际程序运行占用的物理内存并不大。但如果RES也很高,那可能就有点慌了。
2. 内存泄露内存泄露是导致进程内存持续上涨最常见的缘故原由,而这是C++中常见但不好处理的问题,一个掩护多年的大项目,代码不知道由多少个人写的,想找出哪个指针的内存没开释,谈何随意马虎。办理这个问题没有什么通用快捷的办法,只能根据实际业务处理。
第一,从业务上,能不能重现内存泄露。例如我们做游戏的,如果玩家一直地登录,就会导致内存不断上涨,那解释问题就在登录流程,把全体流程拆分,一个个屏蔽测试,终极找出问题。
第二,从支配上,能不能定位内存泄露。例如,最近更新了一个版本,创造内存占用变得很高,那就可以确定,是这个版本的修正出了问题。一个版本的代码量究竟是有限的,查找起来也比较随意马虎。
第三,利用valgrind memcheck。如果能够复现内存泄露,但无法定位是哪个逻辑,那可以用valgrind memcheck。复现内存泄露,这个常日比较难实现,一样平常是线下测试无法复现,线上用户量大,运行久了才会复现,而valgrind会导致程序运行很慢,无法支撑线上测试,因此这个选项常日不太适用于线上。
第四,利用Visual Leak Detector。valgrind是linux下的,如果程序可以跨平台,或者只在win下,那么可以试试这个,这个和valgrind一样,须要复现泄露才能得到堆栈,因此也是用于线下调试比较多。
第五,重载new、delete。像我之前的博客里写的,可以大略地加个计数,用于平时预防泄露,也可更深入一些,记录内存的分配,得到内存漏泄的堆栈,但是这个是否能支撑线上debug,我持疑惑态度。
第六,利用自己的内存分配函数,每一个内存分配,都利用自己的函数,每一个STL的容器,都传入自己的分配器,然后分别记录这些内存分配的大小。这个方法看起来很不现实,但我确实见过在实际的项目中利用,对内存统计、查找有很大的帮助,而且支持在线上debug。查找内存,只须要打印下每个分配器分配的内存大小基本上可以得到结论是哪个分配器出问题。唯一的问题是它增加了开拓难度,而且不能像valgrind那样不须要修正原程序即可利用。
第七,利用valgrind massif。valgrind memcheck须要复现内存泄露,以是不随意马虎找出问题。它会定时记录分配内存的各个堆栈以及分配内存的量,当涌现内存泄露时,根据分配内存的量检讨下各个堆栈,该当是可以找到问题的。massif也会导致程序运行慢,但比memcheck要快,能不能在线上debug,这个依然得看详细情形
第八,利用第三方内存分配器,如jemalloc。并不是说利用第三方内存分配器就办理问题了,而是jemalloc自带了一大堆工具,个中jeprof可以得到内存的大小以及堆栈等信息,对查找内存泄露有很大帮助。不过开启prof后,效率如何,能不能在线上利用,我倒是没测试过。
干系视频推举
90分钟理解Linux内存架构,numa的上风,slab的实现,vmalloc的事理
【C++后端开拓】内存泄露的3个办理方案与事理实现,知道一个可以轻松运用开拓事情
学习地址:C/C++Linux做事器开拓/后台架构师【零声教诲】-学习视频教程-腾讯教室
须要C/C++ Linux做事器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技能,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
3. 内存碎片
如果找不到内存泄露,大概本来就没有内存泄露,这时不妨考虑下内存碎片的问题。这里以linux下的ptmalloc为例(其他的分配器我就不懂了),说下内存分配。如果一个进程,依次分配了内存块m1(1k)、m2(10b)、
m3(1k),然后开释了m2,那全体内存看起来是这样子的:
我们可以看到,m1、m2、m3是按顺序分配的,当m2被开释时,那中间就空了一块了。那空的这一块怎么办,是把它还给系统了吗?这个问题就很繁芜了,涉及到ptmalloc的全体分配机制,这里不打算详细说,建议看华庭(庄明强) - ptmalloc2源代码剖析。大略来讲,便是ptmalloc会暂把开释的内存按大小用链表存起来,比如10b的,放到fast bin那个链表,大一点的,放small bin的第一个链表,再大一点,放small bin的第二个链表,... 放进去的内存,直到第再次用到时取出。
随着程序运行,放进链表的内存可能会越来越多,但是却很少取出(可能是程序开释后没有再申请,也可能是申请的大小和链表里的大小不得当,比如链表里有个10b的,但是程序申请了1k),那这些小内存就会越来越多,进程占用的内存也会越来越多,但实际利用的内存不多。那如何检测这种情形呢?
方法一,利用
malloc_stats。malloc_stats是一个glibc的函数,因此可以在gdb调用
gdb -p 16021call malloc_stats()Arena 0:system bytes = 1359872in use bytes = 954224Arena 1:system bytes = 135168in use bytes = 3488Arena 2:system bytes = 135168in use bytes = 20784Arena 3:system bytes = 139264in use bytes = 120080Total (incl. mmap):system bytes = 1769472in use bytes = 1098576max mmap regions = 0max mmap bytes = 0Arena N表示多个分配域,一样平常一个线程一个system bytes 当前申请的内存总数in use bytes 当前利用的内存总数max mmap regions 利用mmap分配了多少块内存(大内存用mmap分配,大于128K,可由M_MMAP_THRESHOLD选项调节)max mmap bytes 利用mmap分配了多少内存
这里,system bytes减去in use bytes就可以得到当提高程缓存了多少内存。不过malloc_stats是一个很老的接口了,里面的变量都是用的int,如果你的程序占用内存比较大,这里可能会溢出。
方法二,利用利用malloc_info
gdb -p 16021call malloc_info(0, stdout)<malloc version="1"><heap nr="0"><sizes><size from="17" to="32" total="3104" count="97"/><size from="33" to="48" total="11136" count="232"/><size from="49" to="64" total="12288" count="192"/><size from="65" to="80" total="14640" count="183"/><size from="81" to="96" total="4896" count="51"/><size from="97" to="112" total="1232" count="11"/><size from="113" to="128" total="7296" count="57"/><size from="33" to="33" total="13299" count="403"/><size from="97" to="97" total="97" count="1"/><size from="7281" to="7281" total="7281" count="1"/><size from="32833" to="32833" total="32833" count="1"/><unsorted from="145" to="8753" total="166107" count="155"/></sizes><total type="fast" count="823" size="54592"/><total type="rest" count="561" size="219617"/><system type="current" size="1359872"/><system type="max" size="1376256"/><aspace type="total" size="1359872"/><aspace type="mprotect" size="1359872"/></heap><heap nr="1"><sizes><size from="33" to="48" total="48" count="1"/><unsorted from="4673" to="4705" total="9378" count="2"/></sizes><total type="fast" count="1" size="48"/><total type="rest" count="2" size="9378"/><system type="current" size="135168"/><system type="max" size="135168"/><aspace type="total" size="135168"/><aspace type="mprotect" size="135168"/></heap><heap nr="2"><sizes><size from="33" to="48" total="48" count="1"/><size from="113" to="128" total="128" count="1"/><size from="65" to="65" total="65" count="1"/><unsorted from="81" to="3233" total="10054" count="6"/></sizes><total type="fast" count="2" size="176"/><total type="rest" count="7" size="10119"/><system type="current" size="135168"/><system type="max" size="135168"/><aspace type="total" size="135168"/><aspace type="mprotect" size="135168"/></heap><heap nr="3"><sizes><size from="65" to="80" total="80" count="1"/></sizes><total type="fast" count="1" size="80"/><total type="rest" count="0" size="0"/><system type="current" size="139264"/><system type="max" size="139264"/><aspace type="total" size="139264"/><aspace type="mprotect" size="139264"/></heap><total type="fast" count="827" size="54896"/><total type="rest" count="570" size="239114"/><total type="mmap" count="0" size="0"/><system type="current" size="1769472"/><system type="max" size="1785856"/><aspace type="total" size="1769472"/><aspace type="mprotect" size="1769472"/></malloc>
1. nr即arena,常日一个线程一个
2. <size from="17" to="32" total="3104" count="97"/>上面说了,大小在一定范围内的内存,会放到一个链表里,这便是个中一个链表。from是内存下限,to是上限,上面的意思是内存分配在 [17,32]范围内的空闲内存统共有97个,占3104字节内存。在这个区间内的内存申请都会被对齐为32,故total = to count
3. <total type="fast" count="2" size="176"/> 即fastbin这链表当前有2个空闲内存块,大小为176
<total type="rest" count="7" size="10119"/> 除fastbin以外,所有链表空闲的内存数量,以及内存大小。因此fast和rest加起来,该当和当前arena里所有的size同等,如
<heap nr="2"><sizes><size from="33" to="48" total="48" count="1"/><size from="113" to="128" total="128" count="1"/><size from="65" to="65" total="65" count="1"/><unsorted from="81" to="3233" total="10054" count="6"/></sizes><total type="fast" count="2" size="176"/><total type="rest" count="7" size="10119"/>
前两个to大小为48和128为fast bin,数量为2,剩下的都为rest,与下面的fast和reset对应。
5. <total type="mmap" count="0" size="0"/> 利用mmap分配确当前在利用块数(count)和当前在用的内存大小(size)(低版本glibc无此字段,如centos6上的glibc 2.12)
6. <system type="current" size="1769472"/> 当前已经申请的内存大小
7. <system type="max" size="1785856"/> 历史上申请的内存大小(包括已经归还给操作系统的)
8. total和mprotect看源码没看出是什么东西
到这里可以看到,如果一个进程fast和reset里的数量很多,那么解释这个进程实在缓存了很多内存。其余这里都是直接用gdb attach到一个进程直接调用函数,打印到stdout。如果须要查看的程序被关掉了stdout或者重定向了stdout(很多做事器进程都这么做),那可能看不见了,或者信息不是打印到当前终端。
4. 内存利用率如果一个进程占用的内存远高于预期,但没有持续上涨,还须要考虑下是不是内存利用率的问题。当利用new分配一块内存时,系统须要为这次分配记录大小、地址,分配的内存也须要对齐,如果分配的内存很小(比如说1b),那系统终极须要花费的内存是远大于1b的。比如
#include <cstring>#include <iostream>int main(){#define PAUSE(msg) std::cout << msg << std::endl; std::cin >> p char p = NULL; size_t total = 0; while (total < 1024 1024 1024) { size_t size = rand() % 16; total += size; char p = new char[size]; } PAUSE("pause");
这个程序每次分配小于16字节的内存,直到总分配量到1G,然而,在我的系统里(ubuntu 20.04),这个程序跑起来占用的内存就多得多
进程号 USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND 4174 root 20 0 4479488 4.3g 1616 S 0.0 59.0 0:15.97 ./a.out
已经达到了4.3G,显然内存利用率只有1/4不到。你大概会说这种分配小内存的情形不多,但实在不是的。举个例子,做关键字搜索时,会用到二叉搜索树,每一个树的节点对应一个字符,比如"abcd“就须要分配4个节点,但是每个节点实在很小。如果关键字很多(上百万还是很常见的),那这个问题就比较严重。这时候就该当利用valgrind massif来看下,到底是哪个地方分配的内存,然后根据逻辑优化即可。















