
XML(eXtensible Markup Language,可扩展标记措辞)是普遍用于数据交流和数据存储的一种多用场文本文件格式。XML首先是由万维网协会(World Wide Web Consortium,W3C)作为SGML的一个替代品来开拓的。它的语法规则与HTML相似,不过XML是一种用于措辞剖析的措辞,它并没有哀求专门的标记符,属性或者条款。HTML的XML兼容版称为XHTML。
对付比较盛行的SVG(可标量化矢量图形)XML格式,QtSvg模块供应了可用于载入并呈现SVG图像的类。对付利用MathML(数学标记措辞)XML格式的绘制文档,可以利用Qt Solutions中的QtMmLWidget。

对付一样平常的XML数据处理,Qt供应了QtXml模块,这是本文的主题。
二、XML的读取办法
QtXml模块供应了三种截然不同的运用程序编程接口用来读取XML文件:
(1)QXmlStreamReader是一个用于读取格式良好的XML文档的快速解析器。(2)DOM(文档工具模型)把XML文档转换为运用程序可以遍历的树形构造。(3)SAX(XML大略运用程序编程接口)通过虚拟函数直接向运用程序报告“解析事宜”。QXmlStreamReader类最快且最随意马虎利用,它同时还供应了与其他Qt兼容的运用程序编程接口。它很适用于编写单通解析器。DOM的紧张优点是它能以任意顺序遍历XML文档的树形表示,同时可以实现多通解析算法。有一些运用程序乃至利用DOM树作为它们的基本数据构造。SAX则由于一些历史缘故原由而被得以沿用至今,利用QXmlStreamReader常日会有更加大略高效的编码。
利用QXmlStreamReader是在Qt中读取XML文档的最快且最大略的办法。由于解析器的事情能力是逐渐递增的,以是它尤实在用于诸如查找XML文档中一个给定的标记符号涌现的次数、读取内存容纳不了的特大文件、组装定制的数据构造以反响XML文档的内容等。
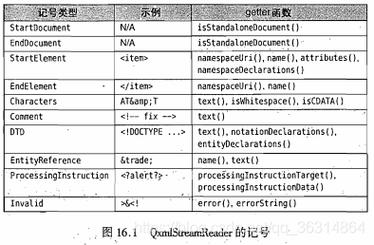
QXmlStreamReader解析器根据下图中所列出的暗号事情。每次只要调用readNext()函数,下一个暗号就会被读取并变成当前的暗号。当前暗号的属性取决于暗号的类型,可以利用表格中列出的getter函数读取当前暗号。
考虑如下的XML文档:
<doc><quote>Einmal ist keinmal</quote></doc>
如果解析这个文档,则readNext()每调用一次都将天生一个新暗号,若利用getter函数还会得到额外的信息;
StartDocumentStartElement (name() == "doc")StartElement (name() == "quote")Characters (text() == " Einmal ist keinmal")EndElement (name() == "quote")EndElement (name() == "doc")EndDocument
每次调用readNext()后,都可以利用isStartElement(),isCharacters()及类似的函数或者仅仅用state()来测试当前暗号的类型。
三、QXmlStreamReader读取XML实例
下面将查看一个实例,它见告我们如何利用QXmlStreamReader解析一个专门的XML文件格式(图1的bookindex.xml)并在QTreeWidget中显示其内容。所解析的是那种具有书刊索引目录且包含索引条款和子条款标文档格式。下图是在QTreeWidget中显示的书刊索引文件。
1、QtXml库
在这个运用程序中利用的QXmlStreamReader类是QtXml库中的一部分。必须在.pro文件中加入如下一行命令:
QT += xml
在代码中添加头文件:
#include <QXmlStreamReader>2、主程序代码
首先查看运用程序中XML阅读器在高下文中是如何利用的。
Widget::Widget(QWidget parent): QWidget(parent), ui(new Ui::Widget){ ui->setupUi(this); ui->treeWidget->setColumnCount(2); QStringList header; header<<"Terms"<<"Pages"; ui->treeWidget->setHeaderLabels(header); XmlStreamReader reader(ui->treeWidget); reader.readFile("bookindex.xml");}
在图中显示的运用程序界面中创建一个QTreeWidget。之后,这个运用程序创建一个XmlStreamReader,并将树形窗口部件值通报给该XmlStreamReader,并哀求它解析所指定的一个文件。
3、XmlStreamReader类的定义然后,我们将查看阅读器的实当代码。
class XmlStreamReader{public: XmlStreamReader(QTreeWidget tree); bool readFile(const QString &fileName);private: void readBookindexElement(); void readEntryElement(QTreeWidgetItem parent); void readPageElement(QTreeWidgetItem parent); void skipUnknownElement(); QTreeWidget treeWidget; QXmlStreamReader reader;};
XmlStreamReader类供应了两个公共函数:布局函数和readFile()函数。这个类利用QXmlStreamReader解析XML文件,并合营QTreeWidget窗口以反响其读入的XML数据。通过利用向下递归的方法来实现这一解析过程。
readBookindexElement()解析一个含有0或0个以上<entry>元素的<bookindex>…</bookindex>元素。readEntryElemen()解析一个含有0或0个以上<page>元素的<entry>…</entry>元素,以及嵌套任意层次的含有0或0个以上<entry>元素。readPageElement()解析一个<page> …</page>元素。skipUnknownElement()跳过不能识别的元素。4、XmlStreamReader类的实现现在看看XmlStreamReader类的实现,由布局函数开始。
XmlStreamReader::XmlStreamReader(QTreeWidget tree){treeWidget=tree;}
布局函数只是用来建立阅读器将利用的那个QTreeWidget。所有的操作都将在readFile()函数中完成(由main()函数调用)。
bool XmlStreamReader::readFile(const QString &fileName){ QFile file(fileName); if(!file.open(QFile::ReadOnly | QFile::Text)){ // (a) std::cerr<<"Error: Cannot read file "<<qPrintable(fileName) <<": "<<qPrintable(file.errorString())<<std::endl; return false; } reader.setDevice(&file); reader.readNext(); // (b) while (!reader.atEnd()) { if(reader.isStartElement()){ if(reader.name()=="bookindex"){ // (c) readBookindexElement(); }else{ reader.raiseError(QObject::tr("Not a bookindex file")); } }else{ reader.readNext(); } } file.close(); if(reader.hasError()){ // (d) std::cerr<<"Error: Failed to parse file" <<qPrintable(fileName)<<": " <<qPrintable(reader.errorString())<<std::endl; return false; }else if(file.error()!=QFile::NoError){ std::cerr<<"Error: Cannot read file "<<qPrintable(fileName) <<": "<<qPrintable(file.errorString())<<std::endl; return false; } return true;}
个中:
(a):readFile()函数首先会考试测验打开文件。如果失落败,则会输出一条出错信息并返回false值;如果成功,则它将被设置为QXmlStreamReader的输人设备。(b):QXmlStreamReader的readNext()函数从输人流中读取下一个暗号。如果成功而且还没有到达XML文件的结尾,函数将进人循环。由于索引文件的构造,我们知道在该循环内部只有三种可能性发生:<bookindex>开始标签恰好被读入;另一个开始标签恰好被读入(在这种情形下,读取的文件不是一个书刊索引);读入的是其他种类的暗号。(c):如果有精确的开始标签,就调用readBookindexElement()连续完成处理。否则,就调用QXmlStreamReader::raiseError()并给出出错信息。下一次(在while循环条件下)调用atEnd()时,它将返还true值。这就确保理解析过程可以在碰着缺点时能尽快停滞。通过对QFile调用error()和errorString(),就可以在稍后查询这些出错信息。当在书刊索引文件中检测到有缺点时,也会立即返回一个类似的出错信息。实在,利用raiseError()常日会更加方便,由于它对低级的XML解析缺点和与运用程序干系的缺点利用了相同的缺点报告机制,而这些低级的XML解析缺点会在QXmlStreamReader运行到无效的XML时就自动涌现。(d):一旦处理完成,就会关闭文件,如果存在解析器缺点或者文件缺点,该函数就输出一个出错信息并返回false值;否则,返回true值并报告解析成功。void XmlStreamReader::readBookindexElement(){ reader.readNext(); while(!reader.atEnd()){ if(reader.isEndElement()){ reader.readNext(); break; } if(reader.isStartElement()){ if(reader.name()=="entry"){ readEntryElement(treeWidget->invisibleRootItem()); }else{ skipUnknownElement(); } }else{ reader.readNext(); } }}
readBookindexElement()的浸染便是读取文件的主体部分。它首先跳过当前的暗号(此处只可能是<bookindex>开始标签),然后遍历读取全体输人文件。
如果读取到了关闭标签,那么它只可能是</bookindex>标签,否则QXmlStreamReader早就已经报告出错。如果是那样的话,就跳过这个标签并跳出循环。否则将该当有一个顶级索引<entry>开始标签。如果情形确实如此,调用readEntryElement()来处理条款数据;不然,就调用skipUnknownElement()。利用skipUnknownElement()而不调用raiseError(),意味着如果要在将来扩展书刊索引格式以包含新的标签的话这个阅读器将连续存效,由于它仅忽略了不能识别的标签。
readEntryElement()具有一个确认父工具条款标QTreeWidgetItem 参数。我们将QTreeWidget::invisibleRootItem()作为父工具项通报,以使新的项以其为根基。在readEntryElement()中,用一个不同的父工具项循环调用readEntryElement()。
void XmlStreamReader::readEntryElement(QTreeWidgetItem parent){ QTreeWidgetItem item = new QTreeWidgetItem(parent); item->setText(0,reader.attributes().value("term").toString()); reader.readNext(); while(!reader.atEnd()) { if (reader.isEndElement()) { reader.readNext(); break; } if (reader.isStartElement()) { if (reader.name() == "entry") { readEntryElement(item); } else if (reader.name() == "page") { readPageElement(item); } else { skipUnknownElement(); } } else { reader.readNext(); } }}
每当碰着一个<entry>开始标签时,就会调用readEntryElement()函数。我们希望为每一个索引条款创建一个树形的窗口部件项,因此创建一个新的QTreeWidgetltem,并将其第一列的文本值设置为条款标项属性文本。
一旦条款被添加到树中,就开始读取下一个暗号。如果这是一个关闭标签,就跳过该标签并跳出循环。如果碰着的是开始标签,那么它可能是<entry>标签(表示一个子条款),<page>标签 (该条款项的页码数),或者是一个未知的标签。如果开始标签是一个子条,就递归调用readEntryElement()。如果该标签是<page>标签,就调用readPageElement()。
void XmlStreamReader::readPageElement(QTreeWidgetItem parent){ QString page = reader.readElementText(); if (reader.isEndElement()) reader.readNext(); QString allPages = parent->text(1); if (! allPages.isEmpty()) allPages += ", "; allPages += page; parent->setText(1, allPages);}
只要读取的是<page>标签,就调用readPageElement()函数。被通报的正是符合页码文本所属条款标树项。我们从读取<page>和</page>标签之间的文本开始。成功读取完往后,readElementText()函数将让解析器勾留在必须跳过的</page>标签上。
这些页被存储在树形窗口部件项的第二列。我们首先提取那里已有的文本。如果文本不为空值,就在其后添加一个逗号,为新页的文本做好淮备。然后,添加新的文本并相应地更新该列的文本。
void XmlStreamReader::skipUnknownElement(){ reader.readNext(); while (!reader.atEnd()) { if (reader.isEndElement()) { reader.readNext(); break; } if (reader.isStartElement()) { skipUnknownElement(); } else { reader.readNext(); } }}
末了,当碰着未知的标签时,将连续读取,直到读取到也将跳过的未知元素的关闭标签为止。这意味着我们将跳过那些具有良好形式但却无法识別的元素,并从XML文件中读取尽可能多的可识別的数据。
——————————————————
对付本文实例完全代码有须要的朋友,可关注并在评论区留言!















