
SegmentFault 是一家综合性技能社区,由于它的内容跟编程技能紧密干系,因此访问量的颠簸也和这一群体的作息韶光深度绑定。常日情形下 web 页面的要求量峰值在 800 QPS 旁边,但我们还做了前后端分离,以是 API 网关的峰值 QPS 是要求量峰值的好几倍。
架构历史SegmentFault 作为一个技能社区的系统架构变革,里面有些东西还是很故意思的。

紧接着,我们碰着了不少寻衅,匆匆使使我们不得不往 K8s 架构上迁移。
首先,虽然我们是一家小公司,但是业务线却非常繁芜,全体公司只有 30 人旁边,技能职员只占个中三分之一旁边,以是承载这么大的业务量包袱还是很重的。而且创业公司的业务线调度非常频繁,临时性事情也比较多,传统的系统架构在应对这种伸缩性哀求比较高的场景是比较吃力的。
其次,繁芜的场景引发了繁芜的配置管理,不同的业务要用到不同的做事,不同的版本,即利用自动化脚本效率也不高。
其余,我们内部职员不敷,以是没有专职运维,现在 OPS 的事情是由后端开拓职员轮值的。但后端开拓职员还有自己本职事情要做,以是对我们最空想的场景是能把运维事情全部自动化。
末了也是最主要的一点便是我们要掌握本钱,这是高情商的说法,低情商便是一个字“穷”(笑)。当然,如果资金充足,以上的问题都不是问题,但是对付创业公司(特殊是像我们这种访问量比较大,但是又不像电商,金融那些挣钱的公司)来说,我们必将处于且长期处于这个阶段。因此能否掌握好本钱,是一个非常主要的问题。
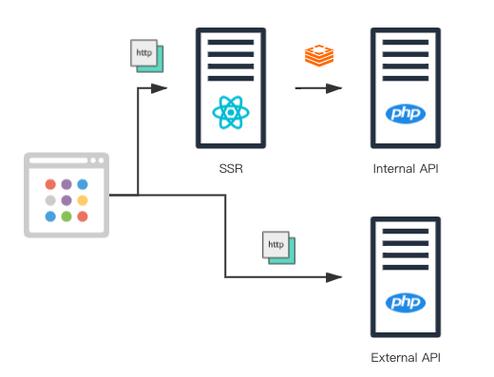
前后端分离2020 年以前,SegmentFault 的网站还是非常传统的后端渲染页面的方法,以是做事真个架构也非常大略。做事端将浏览器的 http 要求转发到后真个 php 做事,php 做事渲染好页面后再返回给浏览器。这种架构用原有的支配方法还能支撑,也便是在各个实例上支配 php 做事,再加一层负载均衡就基本知足需求了。
然而随着业务的持续发展,后端渲染的办法已经不适宜我们的项目规模了,因此我们在 2020 年做了架构调度,准备将前后端分离。前后端分离的技能特点我在这里就不赘述了,这里紧张讲它给我们带来了哪些系统架构上的寻衅。一个是入口增多,由于前后端分离不仅涉及到客户端渲染(CSR),还涉及到做事端渲染(SSR),以是相应要求的做事就从单一的做事变成了两类做事,一类是基于 node.js 的 react server 做事(用来做做事端渲染),另一类是 基于 php 写的 API 做事(用来给客户端渲染供应数据)。而做事端渲染本身还要调用 API,而我们为了优化做事端渲染的连接和要求相应速率,还专门启用明晰利用专有通讯协议的内部 API 做事。
以是实际上我们的 WEB SERVER 有三类做事,每种做事的环境各不相同,所需的资源不同,协议不同,各自之间可能还有相互连接的关系,还须要负载均衡来保障高可用。在快速迭代的开拓节奏下,利用传统的系统架构很难再去适应这样的构造。
我们急迫须要一种能够快速运用的,方便支配各种异构做事的成熟办理方案。
Kubernetes 带来了什么?开箱即用首先是开箱即用,理论上来说这该当是 KubeSphere 的优点,我们直接点一点鼠标就可以打造一个高可用的 K8s 集群。这一点对我们这种没有专职运维的中小团队来说很主要。根据我的亲自经历,要从零开始搭建一个高可用的 K8s 集群还是有点门槛的,没有打仗过这方面的运维职员,一时半会是搞不定的,个中的坑也非常多。
如果云厂商能供应这种做事是最好的,我们不用在做事搭建与系统优化上花费太多韶光,可以把更多的精力放到业务上去。之前我们还自己搭建数据库,缓存,搜索集群,后来全部都利用云做事了。这也让我们的不雅观念有了转变,云时期的根本做事,该当把它视为根本举动步伐的一部分加以利用。
用代码管理支配如果能把运维事情全部用代码来管理,那就再空想不过了。而目前 K8s 确实给我们供应了这样一个能力,现在我们每个项目都有一个 Docker 目录,里面放置了不同环境下的 Dockerfile,K8s 配置文件等等。不同的项目,不同的环境,不同的支配,统统都可以在代码中描述出来加以管理。
比如我们之条件到的同样的 API 做事,利用两种协议,变成了两个做事。在这现在的架构下,就可以实现后端代码一次书写,分开支配。实在这些文件就代替了很多支配操作,我们须要做的只是定义好往后实行命令把它们推送到集群。
而一旦将这些运维事情代码化往后,我们就可以利用现有的代码管理工具,像写代码一样来调度线上做事。更关键的一点是,代码化之后无形中又增加了版本管理功能,这离我们空想中的全自动化运维又更近了一步。
持续集成,快速迭代持续集成标准化了代码发布流程,如果能将持续集成和 K8s 的支配能力结合起来,无疑能大大加快项目迭代速率。而在利用 K8s 之前我们就一贯用 GitLab 作为版本管理工具,它的持续集成功能对我们来说也比较适用。在做了一些脚本改造之后,我们创造它也能很好地做事于现有的 K8s 架构,以是也没有利用 K8s 上诸如 Jenkins 这样的做事来做持续集成。
步骤实在也很大略,做好安全配置就没什么问题。我们本地跑完单元测试之后,会自动上线到本地的测试环境。在代码合并到上线分支后,由管理员点击确认进行上线步骤。然后在本地 build 一个镜像推送到镜像做事器,关照 K8s 集群去拉取这个镜像实行上线,末了实行一个脚本来检讨上线结果。全体流程都是可视化可追踪的,而且在代码管理界面就可以完成,方便开拓者查看上线进度。
总结履历管理好根本镜像目前我们用一个专门的仓库来管理这些根本镜像,这可以使开拓职员拥有与线上同等的开拓环境,而且后续的版本升级也可以在根本镜像中统一完成。
除了将 Dockerfile 文件统一管理以外,我们还将镜像 build 做事与持续集成结合起来。每个 Dockerfile 文件都有一个所属的 VERSION 文件,每次修正里面的版本号并提交,系统都会自动 build 一个相应的镜像并推送到仓库。根本镜像的管理事情完备自动化了,大大减少了人为操作带来的缺点与混乱。
KubeSphere 利用别把日志做事放到集群里。这一点在 KubeSphere 文档中就有提及。详细到日志做事,紧张便是一个 Elastic 搜索做事,自建一个Elastic 集群即可。由于日志做事本身负载比较大,而且对硬盘的持续性需求高,如果你会创造日志做事本身就霸占了集群里相称大的资源,就得不偿失落了。如果生产环境要担保高可用,还是要支配 3 个或以上的节点。从我们利用的履历来看,主节点偶尔会涌现问题。特殊是碰着节点机器要掩护或者升级的时候,多个主节点可以担保业务的正常运行。如果你本身不是专门供应数据库或缓存的做事商,这类高可用做事就不要上K8s,由于要担保这类做事高可用本身就要耗费你大量的精力。我建议还是只管即便用云厂商的做事。副本的规模和集群的规模要匹配。如果你的容器只有几个节点,但一个做事里面扩展了上百个副本,系统的调度会过于频繁从而把资源耗尽。以是这两者要相匹配,在系统设计的时候就要考虑到。末了是一点感想:当做完容器化后,会创造运用在集群里运行的时候并不须要占用那么多台做事器。这是由于降落了资源的粒度,以是可以做更多的风雅化方案,因此利用效率也提高了。
本文由博客一文多发平台 OpenWrite 发布!














