
mysql过滤复制
两种思路:

主库的binlog上实现(不推举,只管即便担保主库binlog完全)
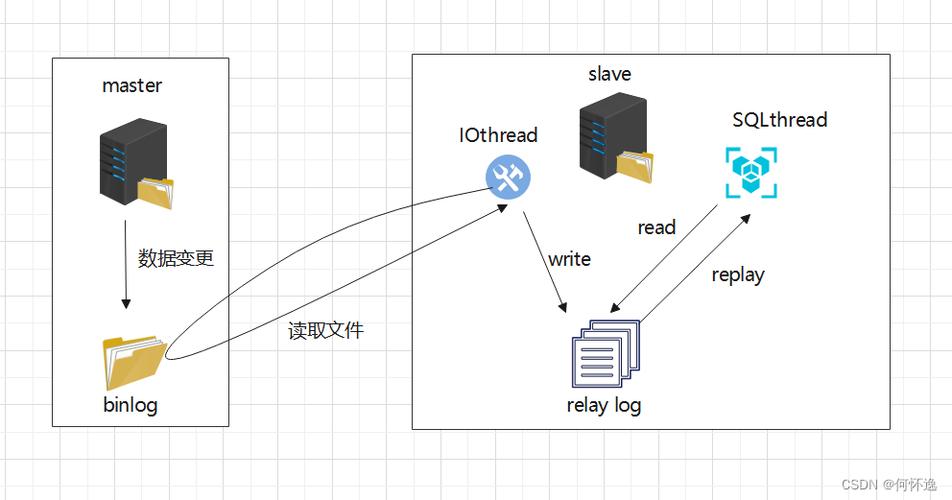
从库的sql线程上实现
以是主从过滤复制只管即便不用,要用的也仅仅在从库上利用,由于要尽可能担保binlog的完全性
主库上实现
在Master 端为担保二进制日志的完全, 不该用二进制日志过滤。
主库配置参数:
#配置文件中添加 binlog-do-db=db_name #定义白名单,仅将制订数据库的干系操作记入二进制日志。如果主数据库崩溃,那么仅仅之规复指天命据库的内容,不建议在主理事器端利用,这样导致日志不完全。binlog-ignore-db=db_name #定义黑名单, 定义ignore 的库上发生的写操作将不会记录到二进制日志中
从库上实现
可以下载配置文件中
REPLICATE_DO_DB = (db_list) #过滤复制哪些库REPLICATE_IGNORE_DB = (db_list) #不复制哪些库REPLICATE_DO_TABLE = (tbl_list) #过滤表REPLICATE_IGNORE_TABLE = (tbl_list) #忽略过滤表REPLICATE_WILD_DO_TABLE = (wild_tbl_list) #根据正则匹配过滤表REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) #根据正则匹配忽略过滤这些表REPLICATE_REWRITE_DB = (db_pair_list)#将源数据库的db1发生的语句重写到从库的db2CHANGE REPLICATION FILTER REPLICATE_REWRITE_DB = ((db1, db2));
语法:
官网语法参考:https://dev.mysql.com/doc/refman/5.7/en/change-replication-filter.html
CHANGE REPLICATION FILTER filter[, filter][, ...] filter: { REPLICATE_DO_DB = (db_list) | REPLICATE_IGNORE_DB = (db_list) | REPLICATE_DO_TABLE = (tbl_list) | REPLICATE_IGNORE_TABLE = (tbl_list) | REPLICATE_WILD_DO_TABLE = (wild_tbl_list) | REPLICATE_WILD_IGNORE_TABLE = (wild_tbl_list) | REPLICATE_REWRITE_DB = (db_pair_list)}
#从库实现过滤复制 stop slave sql_thread; change replication filter replicate_do_db=(db); start slave sql_thread; #取消过滤复制 stop slave sql_thread; change replication filter replicate_do_db=(); start slave sql_thread;
一些问题
主库删除某个表,从库没有这个表,导致从库sql线程关闭
或者主从正常,从库欠妥心删除某个表,主库随后再删除这个表,从库又会去删除这个不存在的表,报错,导致sql线程退出
办理方法:跳过这一步操作
办理方案:从库sql线程跳过误操作的步骤 stop slave sql_thread; #找到Executed_Gtid_Set实行到19set gtid_next='94fc1fbe-b7a0-11eb-b0a0-000c2969aba1:20'; 将gtid分配给下一个事务 begin;commit;set gtid_next=automatic; 系统自动分配gtidstart slave sql_thread;
到此这篇关于mysql过滤复制思路详解的文章就先容到这了
mysql过滤复制的实现 | 《Linux就该这么学》 (linuxprobe.com)















