
上帝视角拆解 Tomcat 架构设计,在理解全体组件设计思路之后。我们须要下凡深入理解每个组件的细节实现。从远到近,架构给人以宏不雅观思维,细节展现饱满的美。关注「码哥字节」获取更多硬核,你,准备好了么?
在上文《追新求快的时期,别让 Java Web 开拓必备工具 Tomcat 变成“熟习的陌生人”!
》中,我们站在上帝视角给大家拆解了 Tomcat 架构设计,剖析 Tomcat 如何实现启动、停滞,通过设计连接池与容器两大组件完成了一个要求的接管与相应。连接器卖力对外交流,处理 socket 连接,容器对内卖力,加载 Servlet 以及处理详细 Request 要求与相应。

高并发拆解核心准备
这回,再次拆解,专注 Tomcat 高并发设计之道与性能调优,让大家对全体架构有更高层次的理解与感悟。个中设计的每个组件思路都是将 Java 面向工具、面向接口、如何封装变与不变,如何根据实际需求抽象不同组件分工互助,如何设计类实现单一职责,怎么做到将相似功能高内聚低耦合,设计模式利用到极致的学习借鉴。
这次紧张涉及到的是 I/O 模型,以及线程池的根本内容。
希望大家重视如下几个知识点,在节制以下知识点再来拆解 Tomcat,就会事半功倍,否则很随意马虎迷失落方向不得其法。
一起来看 Tomcat 如何实现并发连接处理以及任务处理,性能的优化是每一个组件都起到对应的浸染,如何利用最少的内存,最快的速率实行是我们的目标。
设计模式
👉模板方法模式:抽象算法流程在抽象类中,封装流程中的变革与不变点。将变革点延迟到子类实现,达到代码复用,开闭原则。
👉不雅观察者模式:针对事宜不同组件有不同相应机制的需求场景,达到解耦灵巧关照下贱。
👉任务链模式:将工具连接成一条链,将沿着这条链通报要求。在 Tomcat 中的 Valve 便是该设计模式的利用。
I/O 模型
Tomcat 实现高并发吸收连接,一定涉及到 I/O 模型的利用,理解同步壅塞、异步壅塞、I/O 多路复用,异步非壅塞干系观点以及 Java NIO 包的利用很有必要。本文也会带大家着重解释 I/O 是如何在 Tomcat 利用实现高并发连接。大家通过本文我相信对 I/O 模型也会有一个深刻认识。
Java 并发编程
实现高并发,除了整体每个组件的优雅设计、设计模式的合理、I/O 的利用,还须要线程模型,如何高效的并发编程技巧。在高并发过程中,不可避免的会涌现多个线程对共享变量的访问,须要加锁实现,如何高效的降落锁冲突。因此作为程序员,要故意识的只管即便避免锁的利用,比如可以利用原子类 CAS 或者并发凑集来代替。如果万不得已须要用到锁,也要只管即便缩小锁的范围和锁的强度。
对付并发干系的根本知识,如果读者感兴趣「码哥字节」后面也给大家安排上,目前也写了部分并发专辑,大家可移步到历史文章或者专辑翻阅,紧张讲解了并发实现的事理、什么是内存可见性,JMM 内存模模型、读写锁等并发知识点。
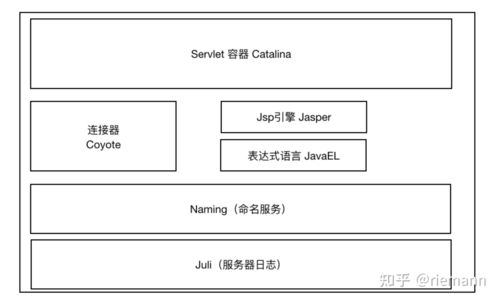
Tomcat 总体架构
再次回顾下 Tomcat 整体架构设计,紧张设计了 connector 连接器处理 TCP/IP 连接,container 容器作为 Servlet 容器,处理详细的业务要求。对外对内分别抽象两个组件实现拓展。
一个 Tomcat 实例默认会有一个 Service,而一个 Service 可以包含多个连接器。连接器紧张有 ProtocalHandler 和 Adapter 两个组件共同完成连接器核心功能。
ProtocolHandler 紧张由 Acceptor 以及 SocketProcessor 构成,实现了 TCP/IP 层 的 Socket 读取并转换成 TomcatRequest 和 TomcatResponse,末了根据 http 或者 ajp 协议获取得当的 Processor 解析为运用层协议,并通过 Adapter 将 TomcatRequest、TomcatResponse 转化成 标准的 ServletRequest、ServletResponse。通过 getAdapter.service(request, response);将要求通报到 Container 容器。
adapter.service实现将要求转发到容器 org.apache.catalina.connector.CoyoteAdapter
// Calling the containerconnector.getService.getContainer.getPipeline.getFirst.invoke( request, response);
这个调用会触发 getPipeline 构成的任务链模式将要求一步步走入容器内部,每个容器都有一条 Pipeline,通过 First 开始到 Basic 结束并进入容器内部持有的子类容器,末了到 Servlet,这里便是任务链模式的经典利用。详细的源码组件是 Pipeline 构成一条要求链,每一个链点由 Valve 组成。如下图所示,全体 Tomcat 的架构设计主要组件清晰可见,希望大家将这个全局架构图深深印在脑海里,节制全局思路才能更好地剖析细节之美。
Tomcat 架构
启动流程:startup.sh 脚本到底发生了什么
Tomcat 启动流程
Tomcat 本生便是一个 Java 程序,以是 startup.sh 脚本便是启动一个 JVM 来运行 Tomcat 的启动类 Bootstrap。
Bootstrap 紧张便是实例化 Catalina 和初始化 Tomcat 自定义的类加载器。热加载与热支配便是靠他实现。
Catalina: 解析 server.xml 创建 Server 组件,并且调用 Server.start 方法。
Server:管理 Service 组件,调用 Server 的 start 方法。
Service:紧张职责便是管理连接器和顶层容器 Engine,分别调用 Connector 和 Engine 的 start 方法。
Engine 容器紧张便是组合模式将各个容器根据父子关系关联,并且 Container 容器继续了 Lifecycle 实现各个容器的初始化与启动。Lifecycle 定义了 init、start、stop 掌握全体容器组件的生命周期实现一键启停。
这里便是一个面向接口、单一职责的设计思想 ,Container 利用组合模式管理容器,LifecycleBase 抽象类继续 Lifecycle 将各大容器生命周期统一管理这里便是,而实现初始化与启动的过程又 LifecycleBase 利用了👉模板方法设计模式抽象出组件变革与不变的点,将不同组件的初始化延迟到详细子类实现。并且利用不雅观察者模式发布启动事宜解耦。
详细的 init 与 start 流程如下泳道图所示:这是我在阅读源码 debug 所做的条记,读者朋友们不要怕条记花费韶光长,自己随着 debug 逐步记录,相信会有更深的感悟。
init 流程
Tomcat Init
start 流程
Tomcat start
读者朋友根据我的两篇内容,捉住主线组件去 debug,然后随着该泳道图阅读源码,我相信都会有所收成,并且事半功倍。在读源码的过程中,切勿进入某个细节,一定要先把各个组件抽象出来,理解每个组件的职责即可。末了在理解每个组件的职责与设计哲学之后再深入理解每个组件的实现细节,千万不要一开始就想着深入理解详细一篇叶子。
每个核心类我在架构设计图以及泳道图都标识出来了,「码哥字节」给大家分享下如何高效阅读源码,以及保持学习兴趣的心得体会。
如何精确阅读源码
切勿陷入细节,不看全局:我还没弄清楚森林长啥样,就盯着叶子看 ,看不到全貌和整体设计思路。以是阅读源码学习的时候不要一开始就进入细节,而是宏不雅观看待整体架构设计思想,模块之间的关系。
1.阅读源码之前,须要有一定的技能储备
比如常用的设计模式,这个必须节制,尤其是:模板方法、策略模式、单例、工厂、不雅观察者、动态代理、适配器、任务链、装饰器。大家可以看 「码哥字节」关于设计模式的历史文章,打造好的根本。
2.必须会利用这个框架/类库,精通各种变通用法
妖怪都在细节中,如果有些用法根本不知道,可能你能看明白代码是什么意思,但是不知道它为什么这些写。
3.先去找书,找资料,理解这个软件的整体设计。
从全局的视角去看待,上帝视角理出紧张核心架构设计,先森林后树叶。都有哪些模块?模块之间是怎么关联的?怎么关联的?
可能一下子理解不了,但是要建立一个整体的观点,就像一个舆图,防止你迷航。
在读源码的时候可以时时时看看自己在什么地方。就像「码哥字节」给大家梳理好了 Tomcat 干系架构设计,然后自己再考试测验随着 debug,这样的效率为虎傅翼。
4. 搭建系统,把源代码跑起来!
Debug 是非常非常主要的手段, 你想通过只看而不运行就把系统搞清楚,那是根本不可能的!
合理利用调用栈(不雅观察调用过程高下文)。
5.条记
一个非常主要的事情便是记条记(又是写作!
),画出系统的类图(不要依赖 IDE 给你天生的), 记录下紧张的函数调用, 方便后续查看。
文档事情极为主要,由于代码太繁芜,人的大脑容量也有限,记不住所有的细节。文档可以帮助你记住关键点, 到时候可以回忆起来,迅速地接着往下看。
要不然,你本日看的,可能到来日诰日就忘个差不多了。以是朋友们记得收藏后多翻来看看,考试测验把源码下载下来反复调试。
缺点办法
陷入细节,不看全局:我还没弄清楚森林长啥样,就盯着叶子看 ,看不到全貌和整体设计思路。以是阅读源码学习的时候不要一开始就进入细节,而是宏不雅观看待整体架构设计思想,模块之间的关系。
还没学会用就研究如何设计:首先基本上框架都利用了设计模式,我们最最少也要理解常用的设计模式,纵然是“背”,也得了然于胸。在学习一门技能,我推举先看官方文档,看看有哪些模块、整体设计思想。然后下载示例跑一遍,末了才是看源码。
看源码穷究细节:到了看详细某个模块源码的时候也要下意识的不要去深入细节,主要的是学习设计思路,而不是详细一个方法实现逻辑。除非自己要基于源码做二次开拓,而且二次开拓也是基于在理解全体架构的情形下才能深入细节。
组件设计-落实单一职责、面向接口思想
当我们接到一个功能需求的时候,最主要的便是抽象设计,将功能拆解紧张核心组件,然后找到需求的变革与不变点,将相似功能内聚,功能之间若耦合,同时对外支持可拓展,对内关闭修正。努力做到一个需求下来的时候我们须要合理的抽象能力抽象出不同组件,而不是一锅端将所有功能糅合在一个类乃至一个方法之中,这样的代码牵一发而动全身,无法拓展,难以掩护和阅读。
看看 Tomcat 如何实现将 Tomcat 启动,并且又是如何接管要求,将要求转发到我们的 Servlet 中。
Catalina
紧张任务便是创建 Server,并不是大略创建,而是解析 server.xml 文件把文件配置的各个组件意义创建出来,接着调用 Server 的 init 和 start 方法,启动之旅从这里开始…,同时还要兼顾非常,比如关闭 Tomcat 还须要做到优雅关闭启动过程创建的资源须要开释,Tomcat 则是在 JVM 注册一个「关闭钩子」,源码我都加了注释,省略了部分无关代码。同时通过 await 监听停滞指令关闭 Tomcat。
/ Start a new server instance. / public void start { // 若 server 为空,则解析 server.xml 创建 if (getServer == ) { load; } // 创建失落败则报错并退出启动 if (getServer == ) { log.fatal(\"大众Cannot start server. Server instance is not configured.\"大众); return; } // 开始启动 server try { getServer.start; } catch (LifecycleException e) { log.fatal(sm.getString(\"大众catalina.serverStartFail\"大众), e); try { // 非常则实行 destroy 销毁资源 getServer.destroy; } catch (LifecycleException e1) { log.debug(\"大众destroy failed for failed Server \"大众, e1); } return; } // 创建并注册 JVM 关闭钩子 if (useShutdownHook) { if (shutdownHook == ) { shutdownHook = new CatalinaShutdownHook; } Runtime.getRuntime.addShutdownHook(shutdownHook); } // 通过 await 方法监听停滞要求 if (await) { await; stop; } }
通过「关闭钩子」,便是当 JVM 关闭的时候做一些清理事情,比如说开释线程池,清理一些零时文件,刷新内存数据到磁盘中…...
「关闭钩子」实质便是一个线程,JVM 在停滞之前会考试测验实行这个线程。我们
来看下 CatalinaShutdownHook 这个钩子到底做了什么。
/ Shutdown hook which will perform a clean shutdown of Catalina if needed. / protected class CatalinaShutdownHook extends Thread { @Override public void run { try { if (getServer != ) { Catalina.this.stop; } } catch (Throwable ex) { ... } } / 关闭已经创建的 Server 实例 / public void stop { try { // Remove the ShutdownHook first so that server.stop // doesn't get invoked twice if (useShutdownHook) { Runtime.getRuntime.removeShutdownHook(shutdownHook); } } catch (Throwable t) { ...... } // 关闭 Server try { Server s = getServer; LifecycleState state = s.getState; // 判断是否已经关闭,若是在关闭中,则不实行任何操作 if (LifecycleState.STOPPING_PREP.compareTo(state) <= 0 && LifecycleState.DESTROYED.compareTo(state) >= 0) { // Nothing to do. stop was already called } else { s.stop; s.destroy; } } catch (LifecycleException e) { log.error(\"大众Catalina.stop\"大众, e); } }
实际上便是实行了 Server 的 stop 方法,Server 的 stop 方法会开释和清理所有的资源。
Server 组件
来体会下面向接口设计美,看 Tomcat 如何设计组件与接口,抽象 Server 组件,Server 组件须要生命周期管理,以是继续 Lifecycle 实现一键启停。
它的详细实现类是 StandardServer,如下图所示,我们知道 Lifecycle 紧张的方法是组件的 初始化、启动、停滞、销毁,和 监听器的管理掩护,实在便是不雅观察者模式的设计,当触发不同事宜的时候发布事宜给监听器实行不同业务处理,这里便是如何解耦的设计哲学表示。
而 Server 自生则是卖力管理 Service 组件。
接着,我们再看 Server 组件的详细实现类是 StandardServer 有哪些功能,又跟哪些类关联?
StandardServer
在阅读源码的过程中,我们一定要多关注接口与抽象类,接口是组件全局设计的抽象;而抽象类基本上是模板方法模式的利用,紧张目的便是抽象全体算法流程,将变革点交给子类,将不变点实当代码复用。
StandardServer 继续了 LifeCycleBase,它的生命周期被统一管理,并且它的子组件是 Service,因此它还须要管理 Service 的生命周期,也便是说在启动时调用 Service 组件的启动方法,在停滞时调用它们的停滞方法。Server 在内部掩护了多少 Service 组件,它因此数组来保存的,那 Server 是如何添加一个 Service 到数组中的呢?
/ 添加 Service 到定义的数组中 @param service The Service to be added / @Override public void addService(Service service) { service.setServer(this); synchronized (servicesLock) { // 创建一个 services.length + 1 长度的 results 数组 Service results = new Service[services.length + 1]; // 将老的数据复制到 results 数组 System.arraycopy(services, 0, results, 0, services.length); results[services.length] = service; services = results; // 启动 Service 组件 if (getState.isAvailable) { try { service.start; } catch (LifecycleException e) { // Ignore } } // 不雅观察者模式利用,触发监听事宜 support.firePropertyChange(\"大众service\公众, , service); } }
从上面的代码可以知道,并不是一开始就分配一个很长的数组,而是在新促进程中动态拓展长度,这里便是为了节省空间,对付我们平时开拓是不是也要紧张空间繁芜度带来的内存损耗,追求的便是极致的美。
除此之外,还有一个主要功能,上面 Caralina 的启动方法的末了一行代码便是调用了 Server 的 await 方法。
这个方法紧张便是监听停滞端口,在 await 方法里会创建一个 Socket 监听 8005 端口,并在一个去世循环里吸收 Socket 上的连接要求,如果有新的连接到来就建立连接,然后从 Socket 中读取数据;如果读到的数据是停滞命令“SHUTDOWN”,就退出循环,进入 stop 流程。
Service
同样是面向接口设计,Service 组件的详细实现类是 StandardService,Service 组件依然是继续 Lifecycle 管理生命周期,这里不再累赘展示图片关系图。我们先来看看 Service 接口紧张定义的方法以及成员变量。通过接口我们才能知道核心功能,在阅读源码的时候一定要多关注每个接口之间的关系,不要急着进入实现类。
public interface Service extends Lifecycle { // ----------紧张成员变量 //Service 组件包含的顶层容器 Engine public Engine getContainer; // 设置 Service 的 Engine 容器 public void setContainer(Engine engine); // 该 Service 所属的 Server 组件 public Server getServer; // --------------------------------------------------------- Public Methods // 添加 Service 关联的连接器 public void addConnector(Connector connector); public Connector findConnectors; // 自定义线程池 public void addExecutor(Executor ex); // 紧张浸染便是根据 url 定位到 Service,Mapper 的紧张浸染便是用于定位一个要求所在的组件处理 Mapper getMapper;}
接着再来细看 Service 的实现类:
public class StandardService extends LifecycleBase implements Service { // 名字 private String name = ; //Server 实例 private Server server = ; // 连接器数组 protected Connector connectors = new Connector[0]; private final Object connectorsLock = new Object; // 对应的 Engine 容器 private Engine engine = ; // 映射器及其监听器,又是不雅观察者模式的利用 protected final Mapper mapper = new Mapper; protected final MapperListener mapperListener = new MapperListener(this);}
StandardService 继续了 LifecycleBase 抽象类,抽象类定义了 三个 final 模板方法定义生命周期,每个方法将变革点定义抽象方法让不同组件实现自己的流程。这里也是我们学习的地方,利用模板方法抽象变与不变。
此外 StandardService 中还有一些我们熟习的组件,比如 Server、Connector、Engine 和 Mapper。
那为什么还有一个 MapperListener?这是由于 Tomcat 支持热支配,当 Web 运用的支配发生变革时,Mapper 中的映射信息也要随着变革,MapperListener 便是一个监听器,它监听容器的变革,并把信息更新到 Mapper 中,这是范例的不雅观察者模式。下贱做事根据多上游做事的动作做出不同处理,这便是👉不雅观察者模式的利用场景,实现一个事宜多个监听器触发,事宜发布者不用调用所有下贱,而是通过不雅观察者模式触发达到解耦。
Service 管理了 连接器以及 Engine 顶层容器,以是连续进入它的 startInternal 方法,实在便是 LifecycleBase 模板定义的 抽象方法。看看他是怎么启动每个组件顺序。
protected void startInternal throws LifecycleException { //1. 触发启动监听器 setState(LifecycleState.STARTING); //2. 先启动 Engine,Engine 会启动它子容器,由于利用了组合模式,以是每一层容器在会先启动自己的子容器。 if (engine != ) { synchronized (engine) { engine.start; } } //3. 再启动 Mapper 监听器 mapperListener.start; //4. 末了启动连接器,连接器会启动它子组件,比如 Endpoint synchronized (connectorsLock) { for (Connector connector: connectors) { if (connector.getState != LifecycleState.FAILED) { connector.start; } } }}
Service 先启动了 Engine 组件,再启动 Mapper 监听器,末了才是启动连接器。这很好理解,由于内层组件启动好了才能对外供应做事,才能启动外层的连接器组件。而 Mapper 也依赖容器组件,容器组件启动好了才能监听它们的变革,因此 Mapper 和 MapperListener 在容器组件之后启动。组件停滞的顺序跟启动顺序恰好相反的,也是基于它们的依赖关系。
Engine
作为 Container 的顶层组件,以是 Engine 实质便是一个容器,继续了 ContainerBase ,看到抽象类再次利用了模板方法设计模式。ContainerBase 利用一个 HashMap<String, Container> children = new HashMap<>; 成员变量保存每个组件的子容器。同时利用 protected final Pipeline pipeline = new StandardPipeline(this); Pipeline 组成一个管道用于处理连接器传过来的要求,任务链模式构建管道。
public class StandardEngine extends ContainerBase implements Engine { }
Engine 的子容器是 Host,以是 children 保存的便是 Host。
我们来看看 ContainerBase 做了什么...
initInternal 定义了容器初始化,同时创建了专门用于启动停滞容器的线程池。
startInternal:容器启动默认实现,通过组合模式构建容器父子关系,首先获取自己的子容器,利用 startStopExecutor 启动子容器。
public abstract class ContainerBase extends LifecycleMBeanBase implements Container { // 供应了默认初始化逻辑 @Override protected void initInternal throws LifecycleException { BlockingQueue<Runnable> startStopQueue = new LinkedBlockingQueue<>; // 创建线程池用于启动或者停滞容器 startStopExecutor = new ThreadPoolExecutor( getStartStopThreadsInternal, getStartStopThreadsInternal, 10, TimeUnit.SECONDS, startStopQueue, new StartStopThreadFactory(getName + \"大众-startStop-\"大众)); startStopExecutor.allowCoreThreadTimeOut(true); super.initInternal; } // 容器启动 @Override protected synchronized void startInternal throws LifecycleException { // 获取子容器并提交到线程池启动 Container children = findChildren; List<Future<Void>> results = new ArrayList<>; for (Container child : children) { results.add(startStopExecutor.submit(new StartChild(child))); } MultiThrowable multiThrowable = ; // 获取启动结果 for (Future<Void> result : results) { try { result.get; } catch (Throwable e) { log.error(sm.getString(\"大众containerBase.threadedStartFailed\"大众), e); if (multiThrowable == ) { multiThrowable = new MultiThrowable; } multiThrowable.add(e); } } ...... // 启动 pipeline 管道,用于处理连接器通报过来的要求 if (pipeline instanceof Lifecycle) { ((Lifecycle) pipeline).start; } // 发布启动事宜 setState(LifecycleState.STARTING); // Start our thread threadStart; }}
继续了 LifecycleMBeanBase 也便是还实现了生命周期的管理,供应了子容器默认的启动办法,同时供应了对子容器的 CRUD 功能。
Engine 在启动 Host 容器便是 利用了 ContainerBase 的 startInternal 方法。Engine 自己还做了什么呢?
我们看下 布局方法,pipeline 设置了 setBasic,创建了 StandardEngineValve。
/ Create a new StandardEngine component with the default basic Valve. / public StandardEngine { super; pipeline.setBasic(new StandardEngineValve); ..... }
容器紧张的功能便是处理要求,把要求转发给某一个 Host 子容器来处理,详细是通过 Valve 来实现的。每个容器组件都有一个 Pipeline 用于组成一个任务链通报要求。而 Pipeline 中有一个根本阀(Basic Valve),而 Engine 容器的根本阀定义如下:
final class StandardEngineValve extends ValveBase { @Override public final void invoke(Request request, Response response) throws IOException, ServletException { // 选择一个得当的 Host 处理要求,通过 Mapper 组件获取到得当的 Host Host host = request.getHost; if (host == ) { response.sendError (HttpServletResponse.SC_BAD_REQUEST, sm.getString(\公众standardEngine.noHost\公众, request.getServerName)); return; } if (request.isAsyncSupported) { request.setAsyncSupported(host.getPipeline.isAsyncSupported); } // 获取 Host 容器的 Pipeline first Valve ,将要求转发到 Host host.getPipeline.getFirst.invoke(request, response);}
这个根本阀实现非常大略,便是把要求转发到 Host 容器。处理要求的 Host 容器工具是从要求中拿到的,要求工具中怎么会有 Host 容器呢?这是由于要求到达 Engine 容器中之前,Mapper 组件已经对要求进行了路由处理,Mapper 组件通过要求的 URL 定位了相应的容器,并且把容器工具保存到了要求工具中。
组件设计总结
大家有没有创造,Tomcat 的设计险些都是面向接口设计,也便是通过接口隔离功能设计实在便是单一职责的表示,每个接口抽象工具不同的组件,通过抽象类定义组件的共同实行流程。单一职责四个字的含义实在便是在这里表示出来了。在剖析过程中,我们看到了不雅观察者模式、模板方法模式、组合模式、任务链模式以及如何抽象组件面向接口设计的设计哲学。
连接器之 I/O 模型与线程池设计
连接器紧张功能便是接管 TCP/IP 连接,限定连接数然后读取数据,末了将要求转发到 Container 容器。以是这里一定涉及到 I/O 编程,本日带大家一起剖析 Tomcat 如何利用 I/O 模型实现高并发的,一起进入 I/O 的天下。
I/O 模型紧张有 5 种:同步壅塞、同步非壅塞、I/O 多路复用、旗子暗记驱动、异步 I/O。是不是很熟习但是又傻傻分不清他们有何差异?
所谓的I/O 便是打算机内存与外部设备之间拷贝数据的过程。
CPU 是先把外部设备的数据读到内存里,然后再进行处理。请考虑一下这个场景,当程序通过 CPU 向外部设备发出一个读指令时,数据从外部设备拷贝到内存每每须要一段韶光,这个时候 CPU 没事干了,程序是主动把 CPU 让给别人?还是让 CPU 一直地查:数据到了吗,数据到了吗……
这便是 I/O 模型要办理的问题。本日我会先说说各种 I/O 模型的差异,然后重点剖析 Tomcat 的 NioEndpoint 组件是如何实现非壅塞 I/O 模型的。
I/O 模型
一个网络 I/O 通信过程,比如网络数据读取,会涉及到两个工具,分别是调用这个 I/O 操作的用户线程和操作系统内核。一个进程的地址空间分为用户空间和内核空间,用户线程不能直接访问内核空间。
网络读取紧张有两个步骤:
用户线程等待内核将数据从网卡复制到内核空间。
内核将数据从内核空间复制到用户空间。
同理,将数据发送到网络也是一样的流程,将数据从用户线程复制到内核空间,内核空间将数据复制到网卡发送。
不同 I/O 模型的差异:实现这两个步骤的办法不一样。
对付同步,则指的运用程序调用一个方法是否立马返回,而不须要等待。
对付壅塞与非壅塞:紧张便是数据从内核复制到用户空间的读写操作是否是壅塞等待的。
同步壅塞 I/O
用户线程发起read调用的时候,线程就壅塞了,只能让出 CPU,而内核则等待网卡数据到来,并把数据从网卡拷贝到内核空间,当内核把数据拷贝到用户空间,再把刚刚壅塞的读取用户线程唤醒,两个步骤的线程都是壅塞的。
同步壅塞 I/O
同步非壅塞
用户线程一贯一直的调用read方法,如果数据还没有复制到内核空间则返回失落败,直到数据到达内核空间。用户线程在等待数据从内核空间复制到用户空间的韶光里一贯是壅塞的,等数据到达用户空间才被唤醒。循环调用read方法的时候不壅塞。
I/O 多路复用
用户线程的读取操作被划分为两步:
用户线程先发起 select 调用,紧张便是讯问内核数据准备好了没?当内核把数据准备好了就实行第二步。
用户线程再发起 read 调用,在等待内核把数据从内核空间复制到用户空间的韶光里,发起 read 线程是壅塞的。
为何叫 I/O 多路复用,核心紧张便是:一次 select 调用可以向内核查询多个数据通道(Channel)的状态,因此叫多路复用。
I/O 多路复用
异步 I/O
用户线程实行 read 调用的时候会注册一个回调函数, read 调用立即返回,不会壅塞线程,在等待内核将数据准备好往后,再调用刚刚注册的回调函数处理数据,在全体过程中用户线程一贯没有壅塞。
异步 I/O
Tomcat NioEndpoint
Tomcat 的 NioEndpoit 组件实际上便是实现了 I/O 多路复用模型,正是由于这个并发能力才足够精良。让我们一起窥伺下 Tomcat NioEndpoint 的设计事理。
对付 Java 的多路复用器的利用,无非是两步:
创建一个 Seletor,在它身上注册各种感兴趣的事宜,然后调用 select 方法,等待感兴趣的事情发生。
感兴趣的事情发生了,比如可以读了,这时便创建一个新的线程从 Channel 中读数据。
Tomcat 的 NioEndpoint 组件虽然实现比较繁芜,但基本事理便是上面两步。我们先来看看它有哪些组件,它一共包含 LimitLatch、Acceptor、Poller、SocketProcessor 和 Executor 共 5 个组件,它们的事情过程如下图所示:
NioEndPoint
正是由于利用了 I/O 多路复用,Poller 内部实质便是持有 Java Selector 检测 channel 的 I/O 韶光,当数据可读写的时候创建 SocketProcessor 任务丢到线程池实行,也便是少量线程监听读写事宜,接着专属的线程池实行读写,提高性能。
自定义线程池模型
为了提高处理能力和并发度, Web 容器常日会把处理要求的事情放在线程池来处理, Tomcat 拓展了 Java 原生的线程池来提升并发需求,在进入 Tomcat 线程池事理之前,我们先回顾下 Java 线程池事理。
Java 线程池
大略的说,Java 线程池里内部掩护一个线程数组和一个任务行列步队,当任务处理不过来的时,就把任务放到行列步队里逐步处理。
ThreadPoolExecutor
来窥伺线程池核心类的布局函数,我们须要理解每一个参数的浸染,才能理解线程池的事情事理。
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { ...... }
corePoolSize:保留在池中的线程数,纵然它们空闲,除非设置了 allowCoreThreadTimeOut,不然不会关闭。
maximumPoolSize:行列步队满后池中许可的最大线程数。
keepAliveTime、TimeUnit:如果线程数大于核心数,多余的空闲线程的保持的最永劫光会被销毁。unit 是 keepAliveTime 参数的韶光单位。当设置 allowCoreThreadTimeOut(true) 时,线程池中 corePoolSize 范围内的线程空闲韶光达到 keepAliveTime 也将回收。
workQueue:当线程数达到 corePoolSize 后,新增的任务就放到事情行列步队 workQueue 里,而线程池中的线程则努力地从 workQueue 里拉活来干,也便是调用 poll 方法来获取任务。
ThreadFactory:创建线程的工厂,比如设置是否是后台线程、线程名等。
RejectedExecutionHandler:谢绝策略,处理程序由于达到了线程界线和行列步队容量实行谢绝策略。也可以自定义谢绝策略,只要实现 RejectedExecutionHandler 即可。默认的谢绝策略:AbortPolicy 谢绝任务并抛出 RejectedExecutionException 非常;CallerRunsPolicy 提交该任务的线程实行;``
来剖析下每个参数之间的关系:
提交新任务的时候,如果线程池数 < corePoolSize,则创建新的线程池实行任务,当线程数 = corePoolSize 时,新的任务就会被放到事情行列步队 workQueue 中,线程池中的线程只管即便从行列步队里取任务来实行。
如果任务很多,workQueue 满了,且 当前哨程数 < maximumPoolSize 时则临时创建线程实行任务,如果总线程数量超过 maximumPoolSize,则不再创建线程,而是实行谢绝策略。DiscardPolicy 什么都不做直接丢弃任务;DiscardOldestPolicy 丢弃最旧的未处理程序;
详细实行流程如下图所示:
线程池实行流程
Tomcat 线程池
定制版的 ThreadPoolExecutor,继续了 java.util.concurrent.ThreadPoolExecutor。对付线程池有两个很关键的参数:
线程个数。
行列步队长度。
Tomcat 一定须要限定想着两个参数不然在高并发场景下可能导致 CPU 和内存有资源耗尽的风险。继续了 与 java.util.concurrent.ThreadPoolExecutor 相同,但实现的效率更高。
其布局方法如下,跟 Java 官方的一模一样
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) { super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler); prestartAllCoreThreads; }
在 Tomcat 中掌握线程池的组件是 StandardThreadExecutor , 也是实现了生命周期接口,下面是启动线程池的代码
@Override protected void startInternal throws LifecycleException { // 自定义任务行列步队 taskqueue = new TaskQueue(maxQueueSize); // 自定义线程工厂 TaskThreadFactory tf = new TaskThreadFactory(namePrefix,daemon,getThreadPriority); // 创建定制版线程池 executor = new ThreadPoolExecutor(getMinSpareThreads, getMaxThreads, maxIdleTime, TimeUnit.MILLISECONDS,taskqueue, tf); executor.setThreadRenewalDelay(threadRenewalDelay); if (prestartminSpareThreads) { executor.prestartAllCoreThreads; } taskqueue.setParent(executor); // 不雅观察者模式,发布启动事宜 setState(LifecycleState.STARTING); }
个中的关键点在于:
Tomcat 有自己的定制版任务行列步队和线程工厂,并且可以限定任务行列步队的长度,它的最大长度是 maxQueueSize。
Tomcat 对线程数也有限定,设置了核心线程数(minSpareThreads)和最大线程池数(maxThreads)。
除此之外, Tomcat 在官方原有根本上重新定义了自己的线程池处理流程,原生的处理流程上文已经说过。
前 corePoolSize 个任务时,来一个任务就创建一个新线程。
还有任务提交,直接放到行列步队,行列步队满了,但是没有达到最大线程池数则创建临时线程救火。
线程总线数达到 maximumPoolSize ,直接实行谢绝策略。
Tomcat 线程池扩展了原生的 ThreadPoolExecutor,通过重写 execute 方法实现了自己的任务处理逻辑:
前 corePoolSize 个任务时,来一个任务就创建一个新线程。
还有任务提交,直接放到行列步队,行列步队满了,但是没有达到最大线程池数则创建临时线程救火。
线程总线数达到 maximumPoolSize ,连续考试测验把任务放到行列步队中。如果行列步队也满了,插入任务失落败,才实行谢绝策略。
最大的差别在于 Tomcat 在线程总数达到最大数时,不是立即实行谢绝策略,而是再考试测验向任务行列步队添加任务,添加失落败后再实行谢绝策略。
代码如下所示:
public void execute(Runnable command, long timeout, TimeUnit unit) { // 记录提交任务数 +1 submittedCount.incrementAndGet; try { // 调用 java 原生线程池来实行任务,当原生抛出谢绝策略 super.execute(command); } catch (RejectedExecutionException rx) { //总线程数达到 maximumPoolSize,Java 原生会实行谢绝策略 if (super.getQueue instanceof TaskQueue) { final TaskQueue queue = (TaskQueue)super.getQueue; try { // 考试测验把任务放入行列步队中 if (!queue.force(command, timeout, unit)) { submittedCount.decrementAndGet; // 行列步队还是满的,插入失落败则实行谢绝策略 throw new RejectedExecutionException(\"大众Queue capacity is full.\公众); } } catch (InterruptedException x) { submittedCount.decrementAndGet; throw new RejectedExecutionException(x); } } else { // 提交任务书 -1 submittedCount.decrementAndGet; throw rx; } } }
Tomcat 线程池是用 submittedCount 来掩护已经提交到了线程池,这跟 Tomcat 的定制版的任务行列步队有关。Tomcat 的任务行列步队 TaskQueue 扩展了 Java 中的 LinkedBlockingQueue,我们知道 LinkedBlockingQueue 默认情形下长度是没有限定的,除非给它一个 capacity。因此 Tomcat 给了它一个 capacity,TaskQueue 的布局函数中有个整型的参数 capacity,TaskQueue 将 capacity 传给父类 LinkedBlockingQueue 的布局函数,防止无限添加任务导致内存溢出。而且默认是无限制,就会导致当前哨程数达到核心线程数之后,再来任务的话线程池会把任务添加到任务行列步队,并且总是会成功,这样永久不会有机会创建新线程了。
为理解决这个问题,TaskQueue 重写了 LinkedBlockingQueue 的 offer 方法,在得当的机遇返回 false,返回 false 表示任务添加失落败,这时线程池会创建新的线程。
public class TaskQueue extends LinkedBlockingQueue<Runnable> { ... @Override // 线程池调用任务行列步队的方法时,当前哨程数肯定已经大于核心线程数了 public boolean offer(Runnable o) { // 如果线程数已经到了最大值,不能创建新线程了,只能把任务添加到任务行列步队。 if (parent.getPoolSize == parent.getMaximumPoolSize) return super.offer(o); // 实行到这里,表明当前哨程数大于核心线程数,并且小于最大线程数。 // 表明是可以创建新线程的,那到底要不要创建呢?分两种情形: //1. 如果已提交的任务数小于当前哨程数,表示还有空闲线程,无需创建新线程 if (parent.getSubmittedCount<=(parent.getPoolSize)) return super.offer(o); //2. 如果已提交的任务数大于当前哨程数,线程不足用了,返回 false 去创建新线程 if (parent.getPoolSize<parent.getMaximumPoolSize) return false; // 默认情形下总是把任务添加到任务行列步队 return super.offer(o); }}
只有当前哨程数大于核心线程数、小于最大线程数,并且已提交的任务个数大于当前哨程数时,也便是说线程不足用了,但是线程数又没达到极限,才会去创建新的线程。这便是为什么 Tomcat 须要掩护已提交任务数这个变量,它的目的便是在任务行列步队的长度无限制的情形下,让线程池有机会创建新的线程。可以通过设置 maxQueueSize 参数来限定任务行列步队的长度。
性能优化
线程池调优跟 I/O 模型紧密干系的是线程池,线程池的调优便是设置合理的线程池参数。我们先来看看 Tomcat 线程池中有哪些关键参数:
这里面最核心的便是如何确定 maxThreads 的值,如果这个参数设置小了,Tomcat 会发生线程饥饿,并且要求的处理会在行列步队中排队等待,导致相应韶光变长;如果 maxThreads 参数值过大,同样也会有问题,由于做事器的 CPU 的核数有限,线程数太多会导致线程在 CPU 上来回切换,耗费大量的切换开销。
线程 I/O 韶光与 CPU 韶光
至此我们又得到一个线程池个数的打算公式,假设做事器是单核的:
线程池大小 = (线程 I/O 壅塞韶光 + 线程 CPU 韶光 )/ 线程 CPU 韶光
个中:线程 I/O 壅塞韶光 + 线程 CPU 韶光 = 均匀要求处理韶光。
Tomcat 内存溢出的缘故原由剖析及调优
JVM 在抛出 java.lang.OutOfMemoryError 时,除了会打印出一行描述信息,还会打印堆栈跟踪,因此我们可以通过这些信息来找到导致非常的缘故原由。在探求缘故原由前,我们先来看看有哪些成分会导致 OutOfMemoryError,个中内存泄露是导致 OutOfMemoryError 的一个比较常见的缘故原由。
实在调优很多时候都是在找系统瓶颈,假如有个状况:系统相应比较慢,但 CPU 的用率不高,内存有所增加,通过剖析 Heap Dump 创造大量要求堆积在线程池的行列步队中,叨教这种情形下该当怎么办呢?可能是要求处理韶光太长,去排查是不是访问数据库或者外部运用碰着了延迟。
java.lang.OutOfMemoryError: Java heap space
当 JVM 无法在堆等分配工具的会抛出此非常,一样平常有以下缘故原由:
内存泄露:本该回收的工具呗程序一贯持有引用导致工具无法被回收,比如在线程池中利用 ThreadLocal、工具池、内存池。为了找到内存泄露点,我们通过 jmap 工具天生 Heap Dump,再利用 MAT 剖析找到内存泄露点。jmap -dump:live,format=b,file=filename.bin pid
内存不敷:我们设置的堆大小对付运用程序来说不足,修正 JVM 参数调度堆大小,比如 -Xms256m -Xmx2048m。
finalize 方法的过度利用。如果我们想在 Java 类实例被 GC 之前实行一些逻辑,比如清理工具持有的资源,可以在 Java 类中定义 finalize 方法,这样 JVM GC 不会立即回收这些工具实例,而是将工具实例添加到一个叫“java.lang.ref.Finalizer.ReferenceQueue”的行列步队中,实行工具的 finalize 方法,之后才会回收这些工具。Finalizer 线程会和主线程竞争 CPU 资源,但由于优先级低,以是处理速率跟不上主线程创建工具的速率,因此 ReferenceQueue 行列步队中的工具就越来越多,终极会抛出 OutOfMemoryError。办理办法是只管即便不要给 Java 类定义 finalize 方法。
java.lang.OutOfMemoryError: GC overhead limit exceeded
垃圾网络器持续运行,但是效率很低险些没有回收内存。比如 Java 进程花费超过 96%的 CPU 韶光来进行一次 GC,但是回收的内存少于 3%的 JVM 堆,并且连续 5 次 GC 都是这种情形,就会抛出 OutOfMemoryError。
这个问题 IDE 办理方法便是查看 GC 日志或者天生 Heap Dump,先确认是否是内存溢出,不是的话可以考试测验增加堆大小。可以通过如下 JVM 启动参数打印 GC 日志:
-verbose:gc //在掌握台输出GC情形-XX:+PrintGCDetails //在掌握台输出详细的GC情形-Xloggc: filepath //将GC日志输出到指定文件中
比如 可以利用 java -verbose:gc -Xloggc:gc.log -XX:+PrintGCDetails -jar xxx.jar 记录 GC 日志,通过 GCViewer 工具查看 GC 日志,用 GCViewer 打开产生的 gc.log 剖析垃圾回收情形。
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
抛出这种非常的缘故原由是“要求的数组大小超过 JVM 限定”,运用程序考试测验分配一个超大的数组。比如程序考试测验分配 128M 的数组,但是堆最大 100M,一样平常这个也是配置问题,有可能 JVM 堆设置太小,也有可能是程序的 bug,是不是创建了超大数组。
java.lang.OutOfMemoryError: MetaSpace
JVM 元空间的内存在本地内存等分配,但是它的大小受参数 MaxMetaSpaceSize 的限定。当元空间大小超过 MaxMetaSpaceSize 时,JVM 将抛出带有 MetaSpace 字样的 OutOfMemoryError。办理办法是加大 MaxMetaSpaceSize 参数的值。
java.lang.OutOfMemoryError: Request size bytes for reason. Out of swap space
当本地堆内存分配失落败或者本地内存快要耗尽时,Java HotSpot VM 代码会抛出这个非常,VM 会触发“致命缺点处理机制”,它会天生“致命缺点”日志文件,个中包含崩溃时线程、进程和操作系统的有用信息。如果碰到此类型的 OutOfMemoryError,你须要根据 JVM 抛出的缺点信息来进行诊断;或者利用操作系统供应的 DTrace 工具来跟踪系统调用,看看是什么样的程序代码在不断地分配本地内存。
java.lang.OutOfMemoryError: Unable to create native threads
Java 程序向 JVM 要求创建一个新的 Java 线程。
JVM 本地代码(Native Code)代理该要求,通过调用操作系统 API 去创建一个操作系统级别的线程 Native Thread。
操作系统考试测验创建一个新的 Native Thread,须要同时分配一些内存给该线程,每一个 Native Thread 都有一个线程栈,线程栈的大小由 JVM 参数-Xss决定。
由于各种缘故原由,操作系统创建新的线程可能会失落败,下面会详细谈到。
JVM 抛出“java.lang.OutOfMemoryError: Unable to create new native thread”缺点。
这里只是概述场景,对付生产在线排查后续会陆续推出,受限于篇幅不再展开。
点分享















