
文章目录
[+]
本节为大家先容一个request要求的cookies利用方法,本人以为还是蛮详细的。
首先导入必备的库

import requestsfrom bs4 import BeautifulSoup
学习从来不是一个人的事情,要有个相互监督的伙伴,事情须要学习python或者有兴趣学习python的伙伴可以私信回答
获取网页cookies(看图)
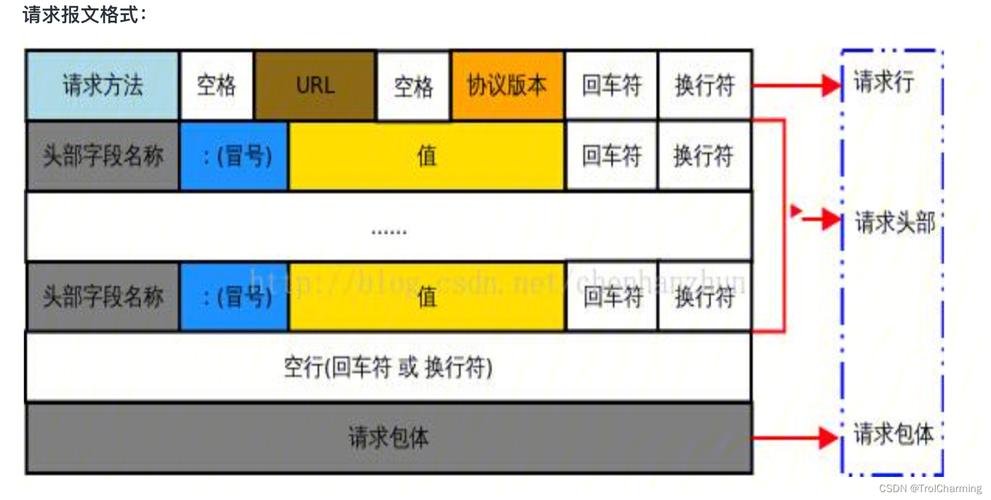
(图片来自网络侵删)
url = ‘网页’coo = ‘如下图 ’
主体代码
cookies = {}for content in coo.split(';'): name, value = coo.split('=', 1) cookies[name] = valueheaders = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}r = requests.get(url, headers=headers, cookies=cookies)html = r.textsoup = BeautifulSoup(html, 'html.parser')
觉得如何呢?有问题可以指出来哟,希望大家一起学习,一起进步















