
GitHub 地址:https://github.com/asap-report/lstm-visualisation
数据集地址https://archive.ics.uci.edu/ml/datasets/Australian+Sign+Language+signs

对付长序列建模而言,是非期影象(LSTM)网络是当前最前辈的工具。然而,理解 LSTM 所学到的知识并研究它们犯某些特定缺点的缘故原由是有些困难的。在卷积神经网络领域中有许多这方面的文章和论文,但是对付 LSTM 我们却没有足够的工具可以对它们进行可视化和调试。
在这篇文章中,我们试图部分补充这个空缺。我们从澳大利亚手语(Auslan)符号分类模型中对 LSTM 网络的激活行为进行可视化,通过在 LSTM 层的激活单元上演习一个降噪自编码器来实现。通过利用密集的自编码器,我们将 LSTM 激活值的 100 维向量投影到 2 维和 3 维。多亏了这一点,我们在一定程度上能够可视化地探索激活空间。我们对这个低维空间进行剖析,并试图探索这种降维操作如何有助于找到数据集中样本之间的关系。
Auslan 符号分类器
本文是 Miroslav Bartold 工程论文(Bartołd,2017)的扩展。该论文中利用的数据集来自(Kadous,2002)。该数据集由 95 个 Auslan 手语符号组成,是利用带高质量位置追踪器的手套捕获而来的。然而,由于个中一个符号的数据文件存在问题,剩下 94 个类可用。每个符号由当地手语利用者重复 27 次,且每个韶光步利用 22 个数字(每只手 11 个数字)进行编码。在数据集中,最长序列的长度为 137,但由于长序列数量很少,因此我们将长度保留 90 位,并在较小引列的前端添补零序列。
Miroslav 的论文测试了几种分类器,它们全都基于 LSTM 架构,分类的准确率在 96%旁边。
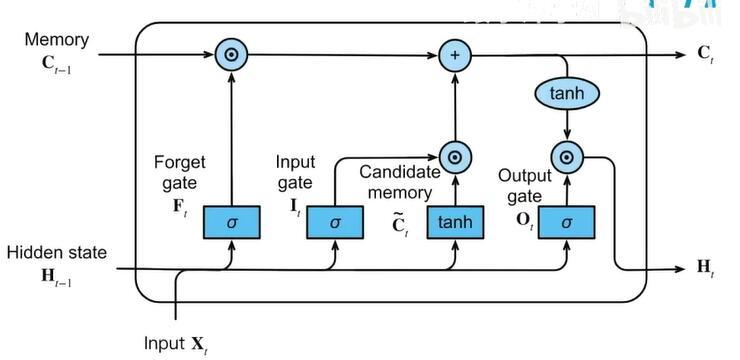
如果你对 LSTM 不甚熟习,你可以看看 Christopher Olah 的博客,上面有关于 LSTM 网络非常好的阐明:http://colah.github.io/posts/2015-08-Understanding-LSTMs/。或者机器之心的文章:在调用 API 之前,你须要理解的 LSTM 事情事理。
在这项研究中,我们将重点关注一种具有 100 个 LSTM 单元单隐层的架构。该架构末了的分类层有 94 个神经元。其输入是具有 90 个韶光步的 22 维序列。我们利用了 Keras 函数式 API,其网络架构如图 1 所示。
图 1:模型架构
图 1 所示的 Lambda 元素从完全的激活序列中提取了末了一层激活(由于我们将 return_sequences=True 传给了 LSTM)。对付实现过程中的细节,我们希望大家查看我们的 repo。
首次考试测验理解 LSTM 网络的内部构造
受到《Visualizing and Understanding Recurrent Networks》(Karpathy, 2015) 的启示,我们试图将一些对应易识别子手势的神经元局域化(并在不同的符号之间共享),例如握紧拳头或用手画圈。但是,这种想法失落败了,这紧张有下列五个缘故原由:
来自定位追踪器的旗子暗记不敷以完备重修手部的运动。
手势在追踪器和真实空间中的表征差异明显。
我们只有来自 http://www.auslan.org.au 的手势视频,却没有数据集中符号的实际实行的视频。
数据集以及视频中的语汇来自不同的方言,以是可能会涌现同义词。
100 个神经元和 94 个符号对付人类理解而言是非常大的空间。
因此,我们只关注可视化技能,希望这能帮助我们揭开关于 LSTM 单元和数据集的一些奥秘。
去噪自编码器
为了将所有手势的 LSTM 输出激活序列可视化,我们将考试测验在每一个韶光步利用去噪自编码器将表征激活值的 100 维向量降为 2-3 维的向量。我们的自编码器由 5 个全连接层组成,个中第三层是具有线性激活函数的瓶颈层。
如果你对上面说的主题不甚熟习,你可以在这里学习更多有关自编码器的知识:http://ufldl.stanford.edu/tutorial/unsupervised/Autoencoders/。
为了使得图像清晰易读,线性激活函数被证明是最佳的激活函数。对付所有被测试的激活函数,所有样本路径(example path,该术语将会不才一部分中阐明)都从图的(0,0)点附近开始。对付非奇对称函数 (ReLU 和 sigmoid) 而言,所有样本路径都在坐标系的第一象限。而对付奇函数而言(例如 tanh 和线性函数),所有路径在所有象限都大致是均匀分布的。但是,tanh 函数将路径压缩到 -1 和 1 附近(这使得图像太过失落真),而线性函数没有这个问题。如果你对其他类型激活函数的可视化感兴趣,你可以在 repo 找到代码实现。
在图 2 中,我们展示了 2D 自编码器的架构。3D 自编码器与之险些完备相同,不过它在第三个 Dense 层中有 3 个神经元。
在每个手势实现的所有单个韶光步中,自编码器利用 LSTM 单元的输出激活向量进行演习。然后这些激活向量被打乱,个中一些冗余激活向量会被去除。冗余激活向量指的是从每个手势开始和结束中得到的矢量,其激活基本保持不变。
图 2 自编码器架构
自编码器中的噪声服从均值为 0 标准差为 0.1 的正态分布,这些噪声被添加到输入向量当中。网络利用 Adam 优化器进行演习,来最小化均方偏差。
可视化
通过向自编码器输入对应于单个手势的 LSTM 单元激活的序列,我们可以得到瓶颈层上的激活。我们将这个低维瓶颈层激活序列作为一个样本路径。
在一些样本的末了一步附近,我们给出了它所代表的手势符号名称。在图 3 中,我们给出了演习集样本路径的可视化结果。
图 3 LSTM 激活韶光蜕变的可视化
可视化图中的每个点都代表一个韶光步、一个样本的自编码器 2D 激活值。图中点的颜色代表每个符号实行的韶光步长(从 0 到 90),黑线连接单一样本路径的点。在可视化之前,每个点都由函数 lambda x: numpy.sign(x) numpy.log1p(numpy.abs(x)) 进行转换。这种转换能够让我们更加仔细地不雅观察每条路径的起始位置。
在图 4 中,我们展示了每个演习样本末了一步的激活。这是输入点到分类层的二维投影情形。
图 4 LSTM 末了一层的激活
令人惊异的是所有路径看起来都非常平滑并且在空间上能很好地分离,由于实际上在演习自编码器前,每个韶光步和样本的所有激活操作都被打乱了。图 4 中的空间构造阐明了为什么我们的末了一个分类层在如此小的演习集上(靠近 2000 个样本)能达到很高的准确率。
对付那些有兴趣研究这个 2D 空间的读者而言,我们已经在以下地址供应了图 2 的大型版本:https://image.ibb.co/fK867c/lstm2d_BIG.png。
在图 5 中,我们展示了三维 LSTM 激活的可视化结果。为了清晰起见,我们只标明了一部分点。出于数据剖析的目的,我们在本文第二部分只关注 2D 可视化。
图 5 LSTM 激活的 3D 可视化版本
剖析
可视化看起来效果非常好,但是个中有没有更故意义的东西呢?如果一些路径间隔很近,是否解释这些手势符号更相似?
让我们在考虑右手和双手符号划分(我们并未看到仅用左手的符号)的情形下看看这个空间吧。这种划分是基于手持跟踪器的旗子暗记可变性统计而来的,更详细的信息拜会 repo。
为了清晰起见,我们在图 6 中绘制了不含点的路径。右手手势符号用青色表示,双手手势符号用洋赤色表示。我们可以清楚地看到,这两种符号都占用了空间的互补部分,并且很少彼此稠浊。
图 6 按照手的利用对激活路径进行分类
现在让我们先来看看 drink-danger 对。这两者都是「青色」的手势,却霸占了图 6 中间偏右侧大部分洋赤色的部分。在我们的数据中,这两个手势都是单手的,但来自 Auslan signbank 的视频阐明表明 danger 手势显然是双手的。
这可能是由标签缺点引起的。请把稳,dangerous 肯定是单手的,而且 drink 也类似(至少在手势的第一部分)。因此,我们认为标签 danger 实际上便是 dangerous。我们在图 7 中绘制了这两个手势。
图 7 标签 drink 和 danger 的 LSTM 激活值
在图 8 中,Who 和 soon 手势的情形很类似。手套中只有一个波折追踪器,且手指波折丈量不是很精确。这也便是这两种手势在图 8 中看起来比视频中更类似的缘故原由。
图 8 who 和 soon 标签的 LSTM 激活值
Crazy 和 think 符号的样本路径霸占了图 9 中的相同空间区域。然而,think 看起来像是稍长的 crazy 手势的一个紧张部分。当我们查看 Auslan signbank 中的视频时,我们创造这种关系是精确的,而且 crazy 符号看起来就像是 think 符号再加上手掌打开的过程。
图 9 think 和 crazy 的 LSTM 激活值
在图 10 中,虽然当我们看 you 这个符号时我们创造这个符号与 crazy、think、sorry(以及其他在这里没有展示出来的手势)相互垂直,但我们在 signbank 中比较它们的视频时,我们并不能创造这些符号和 you 之间的任何相似之处。
图 10 think/crazy/sorry/you 的 LSTM 激活值
我们该当记住,每一个 LSTM 单元的状态会记住它自己之前的状态,它在每一个韶光步都由相应的输入序列馈送进来,并且在路径霸占相同空间时可能会存在韶光蜕变上的不同。因此,除了我们在剖析中考虑的成分,实际上有更多变量会决定路径的形状。这可能阐明了为什么在我们无法不雅观察到符号间视觉相似性时,却能创造部分样本路径之间有交叉关系。
从可视化结果得到的部分紧密联系被证明有误。一些联系在自编码器再演习的间隔中(或 LSTM 单元再演习之后)会发生变革;有些联系则不会变革,可能代表真正的相似之处。举例而言,God 和 Science 有时在 2D 空间中共享相似的路径,有的时候又会彼此阔别。
缺点分类的样本
末了,让我们来看看缺点分类的样本。在图 11、12 和 13 中,我们分别对在演习集、验证集和测试集中缺点分类的样本进行了可视化。缺点分类样本上面的蓝色标签是它们真实的种别。在其下方是模型选择的标签,用赤色标记。
对付演习样本,只有三个样本被缺点标记了,而且个中的两个(hurt-all 和 thank-hot)在二维空间中非常靠近。Thank-hot 在视频中也很靠近,但 Hurt-all 并非如此。
图 11 演习集中缺点分类的样本
正如我们所料,验证集和测试集中都有更多分类缺点的样本,但是这些缺点在投影空间更靠近的手势当中更常发生。
图 12 验证集中缺点分类的样本
图 13 测试集中缺点分类的样本
小结
我们将激活值的 100 维向量投影到低维空间。这种投影看上去很故意思,它彷佛保留了很多(但并非全部)符号之间的关系。这些关系彷佛与我们在不雅观察现实生活中手势所感知到的关系相类似,但是在没有实际匹配手势视频来剖析的情形下,我们无法确定这一点。
这些工具可以在一定程度上用于不雅观察 LSTM 表征的构造。并且,比较与利用原始输入,它可以作为查找样本关系的更好工具。















