
作为插件开拓职员,则须要关注两个问题:
数据源本身的读写数据精确性。如何与框架沟通、合理精确地利用框架。
插件开拓者不用关心太多,基本只须要关注特定系统读和写,以及自己的代码在逻辑上是若何被实行的,哪一个方法是在什么时候被调用的。在此之前,须要明确以下观点:
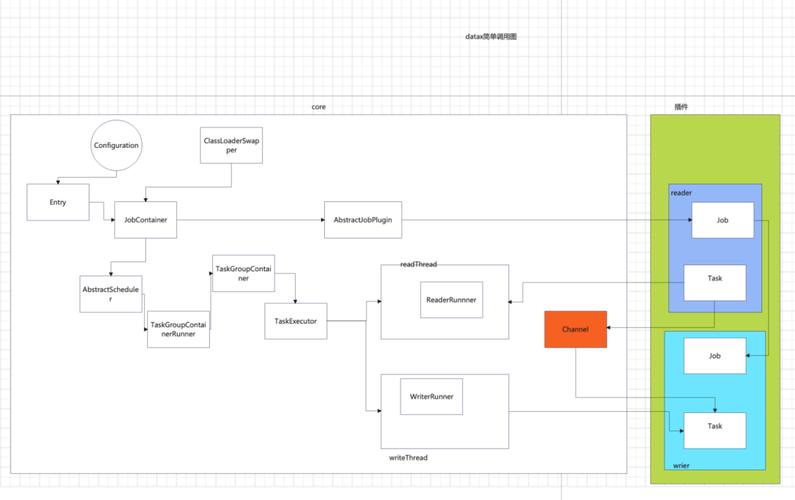
简而言之, Job拆分成Task,在分别在框架供应的容器中实行,插件只须要实现Job和Task两部分逻辑。
物理实行模型框架为插件供应物理上的实行能力(线程)。DataX框架有三种运行模式:
Standalone: 单进程运行,没有外部依赖。Local: 单进程运行,统计信息、缺点信息申报请示到集中存储。Distrubuted: 分布式多进程运行,依赖DataX Service做事。当然,上述三种模式对插件的编写而言没有什么差异,你只须要避开一些小缺点,插件就能够在单机/分布式之间无缝切换了。 当JobContainer和TaskGroupContainer运行在同一个进程内时,便是单机模式(Standalone和Local);当它们分布在不同的进程中实行时,便是分布式(Distributed)模式。
编程接口那么,Job和Task的逻辑应是怎么对应到详细的代码中的?
首先,插件的入口类必须扩展Reader或Writer抽象类,并且实现分别实现Job和Task两个内部抽象类,Job和Task的实现必须是 内部类 的形式。以Reader为例:
public class TestReader extends Reader { public static class Job extends Reader.Job { @Overridepublic void init() { } @Overridepublic void prepare() { } @Overridepublic List<Configuration> split(int adviceNumber) { return null; } @Overridepublic void post() { } @Overridepublic void destroy() { } } public static class Task extends Reader.Task { @Overridepublic void init() { } @Overridepublic void prepare() { } @Overridepublic void startRead(RecordSender recordSender) { } @Overridepublic void post() { } @Overridepublic void destroy() { } }}
Job接口功能如下:
init: Job工具初始化事情,此时可以通过super.getPluginJobConf()获取与本插件干系的配置。读插件得到配置中reader部分,写插件得到writer部分。prepare: 全局准备事情,比如odpswriter清空目标表。split: 拆分Task。参数adviceNumber框架建议的拆分数,一样平常是运行时所配置的并发度。值返回的是Task的配置列表。post: 全局的后置事情,比如mysqlwriter同步完影子表后的rename操作。destroy: Job工具自身的销毁事情。Task接口功能如下:
init:Task工具的初始化。此时可以通过super.getPluginJobConf()获取与本Task干系的配置。这里的配置是Job的split方法返回的配置列表中的个中一个。prepare:局部的准备事情。startRead: 从数据源读数据,写入到RecordSender中。RecordSender会把数据写入连接Reader和Writer的缓存行列步队。startWrite:从RecordReceiver中读取数据,写入目标数据源。RecordReceiver中的数据来自Reader和Writer之间的缓存行列步队。post: 局部的后置事情。destroy: Task象自身的销毁事情。须要把稳的是:
Job和Task之间一定不能有共享变量,由于分布式运行时不能担保共享变量会被精确初始化。两者之间只能通过配置文件进行依赖。prepare和post在Job和Task中都存在,插件须要根据实际情形确定在什么地方实行操作。框架按照如下的顺序实行Job和Task的接口:
上图中,黄色表示Job部分的实行阶段,蓝色表示Task部分的实行阶段,绿色表示框架实行阶段。
插件定义代码写好了,有没有想过框架是怎么找到插件的入口类的?框架是如何加载插件的呢?
在每个插件的项目中,都有一个plugin.json文件,这个文件定义了插件的干系信息,包括入口类。例如:
{ "name": "mysqlwriter", "class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter", "description": "Use Jdbc connect to database, execute insert sql.", "developer": "alibaba" }
name: 插件名称,大小写敏感。框架根据用户在配置文件中指定的名称来征采插件。 十分主要 。class: 入口类的全限定名称,框架通过反射插件入口类的实例。十分主要 。description: 描述信息。developer: 开拓职员。三、实操:datax新增开拓solrreader插件github高下载datax的源代码,导入idea或eclipse网址: https://github.com/alibaba/DataX
然后在dataX下新增solrreader子项目(可以复制mongodbreader,参考其构造)
编写插件代码,然后用maven打包
solrreader/pom.xml添加依赖
<!-- solr 依赖 --><dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-solrj</artifactId> <version>4.10.4</version> <exclusions> <exclusion> <artifactId>slf4j-api</artifactId> <groupId>org.slf4j</groupId> </exclusion> </exclusions></dependency>
修正solrreader/target/datax/plugin/reader/solrreader/plugin.json
{ "name": "solrreader", "class": "com.alibaba.datax.plugin.reader.solrreader.SolrReader", "description": "useScene: prod. mechanism: via solrServer connect solr reader data concurrent.", "developer": "liu"}
修正solrreader/target/datax/plugin/reader/solrreader/plugin_job_template.json
{ "name": "solrreader", "parameter": { "url": "http://{你的solr_ip:端口}/solr/OnlineProductInformation", "fq": ["lastUpdateTime:[ 2015-01-01 TO 2023-01-01 ]"], "fl": "id,lastUpdateTime" }}
详细SolrReader.java代码实现:
package com.alibaba.datax.plugin.reader.solrreader;import java.util.ArrayList;import java.util.Date;import java.util.HashMap;import java.util.List;import java.util.Map;import org.apache.solr.client.solrj.SolrRequest.METHOD;import org.apache.commons.collections.CollectionUtils;import org.apache.commons.lang.StringUtils;import org.apache.solr.client.solrj.SolrServer;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.impl.HttpSolrServer;import org.apache.solr.client.solrj.response.QueryResponse;import org.apache.solr.common.SolrDocument;import org.apache.solr.common.SolrDocumentList;import org.apache.solr.common.params.ModifiableSolrParams;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import com.alibaba.datax.common.element.BoolColumn;import com.alibaba.datax.common.element.DateColumn;import com.alibaba.datax.common.element.DoubleColumn;import com.alibaba.datax.common.element.LongColumn;import com.alibaba.datax.common.element.Record;import com.alibaba.datax.common.element.StringColumn;import com.alibaba.datax.common.exception.DataXException;import com.alibaba.datax.common.plugin.RecordSender;import com.alibaba.datax.common.spi.Reader;import com.alibaba.datax.common.util.Configuration;import com.alibaba.datax.plugin.reader.solrreader.util.CollectionSplitUtil;import com.alibaba.datax.plugin.reader.solrreader.util.CommonDaoHelper;import com.alibaba.datax.plugin.reader.solrreader.util.SolrUtil;/ Created on 2023-04-19 @author Administrator /public class SolrReader extends Reader { public static class Job extends Reader.Job { private Configuration originalConfig = null; private SolrServer solrServer; @Override public List<Configuration> split(int adviceNumber) { return CollectionSplitUtil.doSplit(originalConfig,adviceNumber,solrServer); } @Override public void init() { this.originalConfig = super.getPluginJobConf(); this.solrServer = SolrUtil.initSolrServer(originalConfig); } @Override public void destroy() { } } public static class Task extends Reader.Task { private Configuration readerSliceConfig; private static final Logger LOG = LoggerFactory.getLogger(Task.class); private SolrServer solrServer; private List<String> fq; private String fl; //指定返回那些字段内容,用逗号或空格分隔多个。 表示所有field private Object lowerBound = null; private Object upperBound = null; @Override public void startRead(RecordSender recordSender) { if(lowerBound== null || upperBound == null || solrServer == null) { throw DataXException.asDataXException(ReaderErrorCode.ILLEGAL_VALUE, "lowerBound== null || upperBound == null ||solrServer == null"); } ModifiableSolrParams params = new ModifiableSolrParams(); String q = ":"; if ((!lowerBound.equals("min")) && (!upperBound.equals("max"))) { q = "id:[ " + lowerBound + " TO " + upperBound + " ]"; } params.set("q", new String[] { q }); //查询字符串,这个是必须的。如果查询所有:,根据指定字段查询(name:张三 AND address:北京) params.set("wt", "json"); //指定输出格式,可以有 xml, json, php, phps params.set("sort", new String[] { "id asc" }); //排序。示例:(score desc, price asc)表示先 “score” 降序, 再 “price” 升序,默认是干系性降序。 //指定返回那些字段内容,用逗号或空格分隔多个。 表示所有field params.set("fl", new String[] { fl }); LOG.info("params:" + params); String[] columnNames = fl.split(","); int page = 0; int pageSize = KeyConstant.ROWS; long numFound = 0; while (true) { int start = page pageSize; page++; params.set("start", start); //返回第一条记录在完全找到结果中的偏移位置,0开始,一样平常分页用 params.set("rows", pageSize); //指定返回结果最多有多少条记录,合营start来实现分页。 if(CollectionUtils.isNotEmpty(fq)){ params.set("fq", fq.toArray(new String[fq.size()])); //过虑查询,浸染:在q查询符合结果中同时是fq查询符合的 } int size = 0; try { QueryResponse queryResponse = solrServer.query(params, METHOD.POST); SolrDocumentList solrDocumentList = queryResponse.getResults(); size = solrDocumentList.size(); numFound = solrDocumentList.getNumFound(); LOG.info("numFound:" + numFound); for (SolrDocument solrDocument : solrDocumentList) { Record record = recordSender.createRecord(); for (String columnName : columnNames) { Object tempCol = solrDocument.get(columnName); if (tempCol == null) { //continue; 这个不能直接continue会导致record到目的端错位 record.addColumn(new StringColumn(null)); }else if (tempCol instanceof Double) { //TODO deal with Double.isNaN() record.addColumn(new DoubleColumn((Double) tempCol)); } else if (tempCol instanceof Boolean) { record.addColumn(new BoolColumn((Boolean) tempCol)); } else if (tempCol instanceof Date) { record.addColumn(new DateColumn((Date) tempCol)); } else if (tempCol instanceof Integer) { record.addColumn(new LongColumn((Integer) tempCol)); }else if (tempCol instanceof Long) { record.addColumn(new LongColumn((Long) tempCol)); } else { record.addColumn(new StringColumn(tempCol.toString())); } } recordSender.sendToWriter(record); } } catch (Exception e) { e.printStackTrace(); throw DataXException.asDataXException(ReaderErrorCode.UNEXCEPT_EXCEPTION, "查询失落败:" + e.getMessage()); } if(size < pageSize){ break; } } LOG.info("startRead end, numFound:" + numFound); } @Override public void init() { this.readerSliceConfig = super.getPluginJobConf(); this.solrServer = SolrUtil.initSolrServer(readerSliceConfig); this.fq = readerSliceConfig.getList(KeyConstant.FQ, String.class); this.fl = readerSliceConfig.get(KeyConstant.FL, String.class); this.lowerBound = readerSliceConfig.get(KeyConstant.LOWER_BOUND); this.upperBound = readerSliceConfig.get(KeyConstant.UPPER_BOUND); if(StringUtils.isBlank(fl)){ throw DataXException.asDataXException(ReaderErrorCode.ILLEGAL_VALUE, "fl不能为空"); } } @Override public void destroy() { } }}
利用本地的maven进行编译datax源代码,打包命令如下:
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
等待打包完成…即天生target目录:
利用核心类,Core模块下的Engine进行本地测试:
修正Engine.java代码,由于这里是datax的入口。
首先设置系统变量,也便是datax的目录路径:
System.setProperty("datax.home","D:\\pgerp\\DataX\\target\\datax\\datax");
其次设置job路径和一些参数。
String jobPath = "D:\\数仓\\datax2022-09\\job\\"; //datax的job目录路径
String jobFileName = "solr-2-stream.json";
String[] datxArgs = {"-job", jobPath + jobFileName, "-mode", "standalone", "-jobid", "-1"};
Engine.entry(datxArgs);
进行本地测试的时候,修正对应的json文件即可。
测试: 直接点击main方法运行。
末了附上运行的solr-2-stream.json:
{ "core": { "transport": { "channel": { "speed": { "byte": 104857600 } } } }, "job": { "setting": { "speed": { "channel": 1 } }, "content":[ { "reader": { "name": "solrreader", "parameter": { "url": "http://你的solr_ip:8983/solr/OnlineProductInformation", "fq": ["lastUpdateTime:[ 2015-01-01 TO 2023-01-01 ]"], "fl": "id,lastUpdateTime,price,sku" } }, "writer": { "name": "streamwriter", "parameter": { "print": true, "encoding": "UTF-8" } } } ] }}















