
贺春旸,dbaplus社群金牌专家,凡普金科和爱钱进DBA团队卖力人,《MySQL管理之道:性能调优、高可用与监控》第一&二版、《MySQL运维进阶指南》作者,曾任职于中国移动飞信、安卓机锋网。五次荣获dbaplus年度MVP,致力于MariaDB、MongoDB等开源技能的研究,紧张卖力数据库性能调优、监控和架构设计。
MariaDB ColumnStore利用分布式列式存储和大规模并行处理(MPP)共享无架构扩展了MariaDB企业做事器,将其转变为独立或分布式数据仓库,用于繁芜SQL查询和高等剖析,而无需创建任何索引。

以下是 MariaDB ColumnStore 的一些关键特性和上风:
列式存储:MariaDB ColumnStore 利用列式存储办法,将数据按列存储在磁盘上。这种存储办法在处理大规模数据时具有出色的压缩比和查询性能,尤其适宜剖析型查询。分布式架构:MariaDB ColumnStore 支持水平扩展,可以在多个节点上分布数据和查询事情负载。通过添加更多的节点,可以实现更高的处理能力和吞吐量。并行查询处理:MariaDB ColumnStore 可以并行实行查询操作,充分利用多核处理器和分布式环境的打算资源。这样可以加快查询速率,并供应更快的相应韶光。数据压缩:MariaDB ColumnStore 利用高效的数据压缩算法,可以显著减少存储需求,并提高查询性能。压缩后的数据可以更快地加载到内存中,并节省磁盘空间。支持标准SQL:MariaDB ColumnStore 是基于 MariaDB 数据库构建的,因此它保留了 MariaDB/MySQL 的兼容性和广泛的 SQL 支持。这使得开拓职员可以利用熟习的 SQL 查询措辞进行数据剖析和查询操作。
总之,MariaDB ColumnStore 是一个功能强大的列式存储引擎,适用于大规模数据剖析和数据仓库事情负载。它供应高性能、可扩展性和丰富的 SQL 功能,帮助用户快速处理和剖析海量数据。
以下是MySQL领域的数仓办理方案:
MySQL HeatWave(收费)MariaDB Columnstore(开源)MariaDB Enterprise Columnstore(收费)Percona ClickHouse(开源)
行式存储和列式存储的差异:
在MariaDB 10.6版本中,ColumnStore迎来了一系列显著的改进:
MariaDB ColumnStore 10.6支持一键支配,简化了安装过程,利用户能够更轻松地搭建环境。实现了MySQL InnoDB到ColumnStore的同步复制(可以利用 "CHANGE MASTER TO" 命令与业务库中的 InnoDB 引擎建立同步复制),无需借助任何ETL工具,实现了增量数据的实时同步。这一创新性的改进使数据同步变得更加高效和便捷。
这些升级和改进为用户供应了更加强大和灵巧的数据仓库办理方案,使其能够更方便地进行繁芜查询和高等剖析,为企业的数据处理供应了更高的效率和实时性。
安装与支配
采取海内镜像阿里云YUM源:
shell> vim /etc/yum.repos.d/mariadb.repo# MariaDB 10.6 CentOS repository list - created 2023-12-29 01:20 UTC# https://mariadb.org/download/[mariadb]name = MariaDB# rpm.mariadb.org is a dynamic mirror if your preferred mirror goes offline. See https://mariadb.org/mirrorbits/ for details.# baseurl = https://rpm.mariadb.org/10.6/centos/$releasever/$basearchbaseurl = https://mirrors.aliyun.com/mariadb/yum/10.6/centos/$releasever/$basearchmodule_hotfixes = 1# gpgkey = https://rpm.mariadb.org/RPM-GPG-KEY-MariaDBgpgkey = https://mirrors.aliyun.com/mariadb/yum/RPM-GPG-KEY-MariaDBgpgcheck = 1
1.打算层安装支配:
shell> yum install epel-releaseshell> yum install jemallocshell> yum install MariaDB-server MariaDB-backup MariaDB-shared MariaDB-client MariaDB-columnstore-engine
注:yum完会自动启动UM模块和PM模块做事
2.数据存储引擎层安装:
shell> vim /etc/my.cnf# MariaDB Columnstore OLAP#[client-server]port = 3306socket = /tmp/mysql_mariadb.sock[mysqld]server-id = 133061port = 3306user = mysqlbasedir = /usrdatadir = /data/mysql/columnstore/datatmpdir = /data/mysql/columnstore/tmplog-error = /data/mysql/columnstore/log/error.logsocket = /tmp/mysql_mariadb.sockskip-slave-startskip-external-lockingskip-name-resolvesql_mode = ''plugin-load-add = ha_columnstore.sodefault-storage-engine = Columnstorecharacter-set-server = utf8mb4collation-server = utf8mb4_general_ciinit_connect = 'set global character_set_database = "utf8mb4"'slow_query_log = 1slow_query_log_file = /data/mysql/columnstore/log/mysql-slow.loglog-slow-verbosity = query_plan,explainlong_query_time = 5columnstore_replication_slave = 1 #启动与innodb同步复制max_allowed_packet = 256M
初始化mysql目录
shell> mysql_install --defaults-file=/etc/my.cnf --user=mysql
启动mysqld进程
shell> mysqld_safe --defaults-file=/etc/my.cnf --user=mysql &
注:
mysqld做事启动后,sql语法利用起来跟InnoDB无差异,你可以用Navicat/Sqlyog等MySQL客户端工具连接,Java/php/python的driver驱动无需变更(兼容MySQL)。Columnstore数据目录在/var/lib/columnstore/Columnstore配置文件在/etc/columnstore/Columnstore.xml一、MariaDB Columnstore引擎利用把稳事变
字段属性限定
1、varchar最大8000(如果是utf8,即8000/3;如果是utf8mb4,即8000/4)
2、不支持bit类型
3、不支持Reserved keywords保留关键字user、comment、match、key、update、status作为表名、字段名或用户定义的变量、函数或存储过程的名称。
4、不支持zerofill
5、不支持enum列举类型
6、comment不能携带''引号
create table t1(id int comment '主键''ID')engine=Columnstore;
7、不支持主键自增
SQL语句限定
1、查询的字段不在group by里,就不能分组统计
缺点写法:
MariaDB [test]> select id from t1 group by name; ERROR 1815 (HY000): Internal error: MCS-2021: '`test`.`t1`.`id`' is not in GROUP BY clause. All non-aggregate columns in the SELECT and ORDER BY clause must be included in the GROUP BY clause.
MariaDB [test]> select id,name from t1 group by name; ERROR 1815 (HY000): Internal error: MCS-2021: '`test`.`t1`.`id`' is not in GROUP BY clause. All non-aggregate columns in the SELECT and ORDER BY clause must be included in the GROUP BY clause.
精确写法:
MariaDB [test]> select name from t1 group by name;
2、alter不支持多列操作和不支持after
MariaDB [test]> alter table t1 add age tinyint,add address varchar(100);ERROR 1178 (42000): The storage engine for the table doesn't support Multiple actions in alter table statement is currently not supported by Columnstore.
3、字段类型不同 join 关联查询报错,比如表1的id字段为int,表2的字段id为varchar,进行关联查询join就会报错
MariaDB [test]> select t1.id from t1 join t2 on t1.id=t2.cid;ERROR 1815 (HY000): Internal error: IDB-1002: 't1' and 't2' have incompatible column type specified for join condition.
4、alter不支持change/modify变动字段属性
MariaDB [test]> alter table t1 change id id bigint;ERROR 1815 (HY000): Internal error: CAL0001: Alter table Failed: Changing the datatype of a column is not supported
建表范例
CREATE TABLE `sbtest` ( `id` int(10) unsigned NOT NULL, `k` int(10) unsigned NOT NULL DEFAULT '0', `c` char(120) DEFAULT '', `pad` char(60) NOT NULL DEFAULT '') ENGINE=Columnstore DEFAULT CHARSET=utf8;
二、将InnoDB全量同等性快照导入到
MariaDB Columnstore引擎
第一步:只导出表构造
shell>/usr/local/mysql-5.7.42/bin/mysqldump -S /tmp/mysql_mysql57_1.sock test sbtest1 --compact -d -q --set-gtid-purged=OFF > ./sbtest.sql
第二步:变动表构造字段属性,改为Columnstore
shell> ./convert.sh sbtest.sql sbtest_new.sqlsed -e 's/InnoDB/Columnstore/;s/NOT NULL//g;/.KEY./d;s/AUTO_INCREMENT=[0-9]//g;s/AUTO_INCREMENT//g;s/\<timestamp\>.TIMESTAMP\|\<timestamp\>/datetime /g;s/\<COLLATE.utf8_bin\>//g;s/\<CHARACTER.SET.[utf8|utf8mb4]\>//g;s/decimal([0-9]/decimal(18/g;s/ROW_FORMAT=COMPACT//g;s/bit/int/g;s/COLLATE. utf8mb4_unicode_ci//g;s/DEFAULT CURRENT_TIMESTAMP//g;s/\<text\>/varchar(2000)/g;s/\<longtext\>/varchar(2000)/g;s/\<mediumtext\>/varchar(2000)/g;s/COLLATE utf8mb4_bin//g;s/ON UPDATE CURRENT_TIMESTAMP//g' /data/bak/$1 | sed '/,/{:loop; N; /,\s)/! bloop; s/,\s)/\n)/}' > /data/bak/$2
第三步:用mydumper多线程导出数据(CSV格式)
shell>yum install https://github.com/mydumper/mydumper/releases/download/v0.15.1-3/mydumper-0.15.1-3.el7.x86_64.rpmshell>/usr/bin/mydumper -S /tmp/mysql_mysql57_1.sock --regex 'test.sbtest1' -t 16 --csv -v 3 --rows 10000000 --no-schemas -o ./
第四步:规复到MariaDB Columnstore列式存储里
shell>/usr/bin/myloader -S /tmp/mysql_mariadb.sock -t 1 -v 3 -B test -d ./
注:这里须要用1个线程导入,多个线程导入会引发锁争用,数据不全。
三、将InnoDB binlog增量数据实时同步到MariaDB Columnstore引擎
架构图示意:
下面就来先容MariaDB 10.6多源复制的搭建方法。
1)创建通道,命令如下:
mysql > SET @@default_master_connection = ${connect_name};注:${connect_name}为自定义连接的名字。
2)建立同步复制,命令如下:
mysql > CHANGE MASTER ${connect_name} TO MASTER_HOST='192.168.1.10',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_PORT=3306,MASTER_LOG_FILE='mysql-bin.000001',MASTER_LOG_POS=4,MASTER_CONNECT_RETRY=10;
注:要利用基于binlog和position位置点建立同步复制,由于MySQL GTID不兼容MariaDB。
3)启动多源复制,命令如下:
mysql > START SLAVE ${connect_name};mysql > START ALL SLAVES;
4)停滞多源复制,命令如下:
mysql > STOP SLAVE ${connect_name};mysql > STOP ALL SLAVES;
5)查看状态,命令如下:
mysql > SHOW SLAVE ${connect_name} STATUS;mysql > SHOW ALL SLAVES STATUS;
6)清空同步信息和日志,命令如下:
mysql > RESET SLAVE ${connect_name} ALL;
7)刷新中继日志,命令如下:
mysql > FLUSH RELAY LOGS ${connect_name};
注:
MySQL 从库的binlog格式必须设置为binlog_format =STATEMENT(ROW行格式会触发Columnstore的bug),会导致mysqld进程crash,这里特殊把稳!如碰着Columnstore从库的列类型不一致导致的复制非常问题(例如InnoDB里有text类型,Columnstore不支持,转换位varchar(8000/3) ->utf8),须要设置set global slave_type_conversions = ALL_LOSSY,ALL_NON_LOSSY;
即:所有许可的数据类型转换都会实行,而不管数据是否被截取。
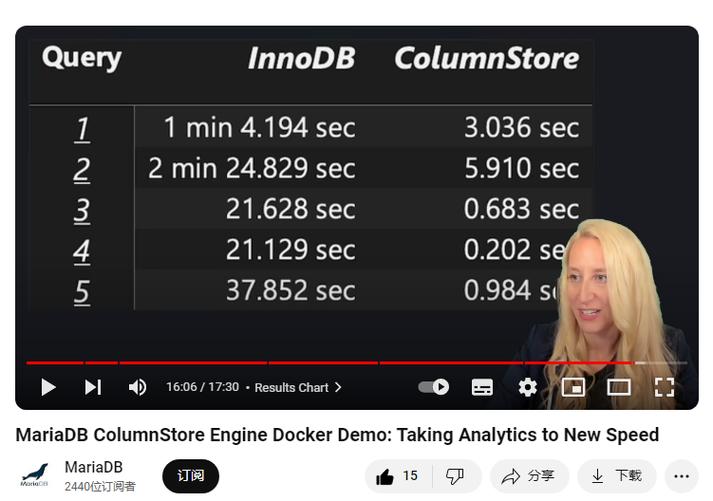
四、InnoDB VS Columnstore 繁芜SQL官方性能测试
样本测试用例:
https://github.com/mariadb-corporation/mariadb-columnstore-sample-data
结论
在性能方面,这两种存储引擎在不同的领域表现出色。InnoDB被优化用于事务性事情负载,个中数据常常被更新或插入。它采取了预写式日志机制,以确保在系统故障的情形下数据始终保持同等和可规复。
相反,ColumnStore被优化用于剖析事情负载,个中数据以读为主,查询常日涉及聚合和过滤操作。由于其列式设计和矢量化处理,ColumnStore可以更快地实行这些查询。
此外,ColumnStore还供应了额外的好处,如高速批量加载器和更小的磁盘占用空间。与InnoDB不同,ColumnStore不该用传统的索引,这有助于减小其磁盘占用空间。此外,ColumnStore的列式设计许可更高的数据压缩比,减少存储数据所需的磁盘空间。这些上风使得ColumnStore成为那些希望优化其数据存储和处理以适应剖析事情负载的组织的一个引人瞩目的选择。
参考:MariaDB ColumnStore Engine Docker Demo: Taking Analytics to New Speed
https://www.youtube.com/watch?v=RrGo3cJdq0M
五、Columnstore高可用与数据扩容
MariaDB Columnstore企业版支持高可用功能,它是基于挂载AWS S3工具存储或者SAN光纤共享存储加以实现,实现事理类似甲骨文Oracle RAC集群架构,参考下面的架构示意图,这里不重点先容。
本文紧张先容的是MariaDB Columnstore社区版(GPL开源)如何实现高可用的。答:DBA可以多支配几台MariaDB Columnstore(相称于多个slave节点),把数据导入进去且与InnoDB同步复制,Columnstore用keepalived或者Haproxy实现高可用故障转移。
那Columnstore的数据如何动态扩容呢?
答:官方推举用GFS(Gluster File System)分支配文件系统办理动态数据扩容,只须要把Columnstore的数据目录/var/lib/columnstore/data1目录mount挂载到GFS分支配文件系统上即可。
六、MariaDB Columnstore数仓(列式存储)在企业里的上风
对dba友好,会装MySQL,会搭建主从复制,会备份规复即可玩转大数据,并且无需变动业务的sql,不须要创建任何索引。无需借助hadoop等生态ETL工具抽数据+同步增量实时数据,MariaDB利用自身的主从复制即可完成数据流的转换,零本钱,不须要学习额外的技能栈。对java研发和业务方友好,他们可以连续欢畅地利用Navicat等客户端工具连接查询,jdbc driver驱动无需变更,sql语句高度兼容MySQL,不须要学习额外的sql技能栈。可以为企业节省人力本钱,大数据架构根本培植交给dba团队履行与管理,让数据剖析职员可以专心地编写业务sql。非常适宜中小企业落地利用。
如在安装支配过程中碰着问题,也可以参考搭建视频:
大数据 MariaDB Columnstore 数仓OLAP 安装与支配https://www.bilibili.com/video/BV1qg4y1k7ZK如何将InnoDB数据迁移至MariaDB Columnstore 数仓OLAP系统里https://www.bilibili.com/video/BV1xc411r7kY将MySQL InnoDB 增量数据实时同步到 MariaDB Columnstore 数仓OLAP系统里https://www.bilibili.com/video/BV18c411k7paMariaDB Columnstore 数仓OLAP 繁芜SQL性能测试https://www.bilibili.com/video/BV1Fe411D7BR














