
Cloud Storage
Cloud Storage is a storage system that should be fully integrated with cloud systems and can provide lower TCO without any compromise to reliability and scalability. The cloud systems are software defined and are built on top of commodity hardware; similarly, it needs a storage system that follows the same methodology, that is, being software defined on top of commodity hardware,

Unified Storage
A storage system that supports blocks, files, and object storage from a single system.
1.2 Disk我们最好将Disk翻译成“硬盘”,当前来说紧张包括磁盘和固态硬盘(SSD),前者紧张因此磁分子的两个磁极来存储数据,后者紧张以电荷来存储数据。
1.2.1 块式与流式所谓块式存储,即数据以一块一块的办法存储在介质上,数据存储位置的定位因此“块”为单位;流式存储,即数据以bit办法连续的存储在介质上,数据存储位置的定位因此“比特位”为单位。最根本的差异还是在数据存储位置的定位办法上,实际上数据在介质上还不因此一个bit一个bit的存储的吗?!
比如MP3播放器存储歌曲只能从歌曲的开头播放,而磁带机则可以从任何位置开始播放。
1.2.2 磁盘【磁盘物理构造】
【数据存储】
· 磁盘一样平常存在多个盘片,每个盘片有两个盘面,每个盘面会有一个磁头,划分为多个同心磁道,每个磁道划分为多个等长的扇区
· 扇区是磁盘存储的最小单元,在扇区内的数据存储是流式的,但是对付磁盘来说,存储是按照以扇区为最小单元来存储的,即所谓的“块”存储
· CHS=柱面cylinder+磁头Header+扇区Sector,扇区的地址由这三个唯一确定
· LBA:Logical Block Address,顺序编址,这个实在是物理编址CHS的逻辑编址,即为了硬盘掌握器能够识别的地址,LBA定义了逻辑地址与物理地址的映射关系
· 每个扇区即一段弧线,以是一个扇区的长度即弧线的长度,一个扇区的宽度是多少?把稳比较随意马虎误解的认为是两个磁道之间的间隔,实际是磁分子的宽度,也即磁头的大小
· 磁极N为1,S极为0,以是每个磁道上的磁分子非常密集,才能存储大量数据
· 磁盘的读写是先0号柱面,0号磁头(盘面),0号磁道开始,当0号磁道写满或读完后,1号盘面0号柱面,0号磁道进行。当0号柱面都写满或读完后,再开始从1号柱面开始,即换磁道
· 硬盘的性能紧张由磁道切换的速率来决定的,磁道切换由磁头来进行,速率比较慢,盘面切换由电机来掌握
· 硬盘的电路部分实际是一个小型系统,有MCU、DSP、数字电路、BIOS,特殊是软件掌握系统存放在BIOS里面,比如磁盘的低级格式化等程序等,同时还可以存储一些动态的信息,比如磁头位置
【磁盘性能】
磁盘性能指标紧张有两个:读写IOPS和读写吞吐量。
影响磁盘性能的成分紧张有四个:
· 转速,磁盘吞吐量的最大影响成分
· 寻道速率,磁盘随机IOPS的最大影响成分
· 容量
· 接口
1.2.3 固态硬盘
SSD:Solid Storage Disk,固态存储硬盘,把稳这时候就不能称之为磁盘了,由于它不再因此磁粉子的N和S极来存储数据,而因此每个电子是否充电或电势来存储数据。
SSD有两种,一种是用DRAM芯片来存储数据,又称之为RAM-disk,当外部电源断开后,须要利用电池来坚持DRAM的数据;一种是基于Flash介质的SSD。
固态存储的上风:没有寻道的开销、任何地址的访问开销是相等的,以是随机IO性能很好,而且险些没有差别。
RAM:Random-Access-Memory,随机访问存储器,有DRAM、SRAM、SDRAM,DRAM须要靠不断的刷新来存储数据,SRAM则不须要刷新,但是比较昂贵,一样平常用于CPU的cache、CMOS芯片;SDRAM,即Synchronous DRAM,靠时钟相同频率去刷新。
ROM:Read-Only-Memory,只读存储器;PROM,Programmable ROM;EPROM,Erasable Programmable ROM;EEPROM,Electrically Erasable Programmable ROM;FLASH ROM则属于真正的单电压芯片,在利用上很类似EPROM,但是与PROM有些不同,PROM在删除时以Byte为最小单元,而Flash Rom以Block为最小单元。
但是无论是哪种ROM,都因此“浮动门场效应晶体管”来存储数据的,每个晶体管叫一个最小单元Cell,有两种Cell,一种SLC(Single Level Cell),可以保持1B数据,一种MLC(Multi Level Cell),可以保持2B数据。
【SSD硬盘逻辑构造】
【数据存储与读写】
Cell串,即上图3-34纵向的每列,每列同一韶光只能有一个Cell被充电;在同一水平线上的cell构成了所谓的page。
从逻辑上讲,内部的组织构造则是page是Flash的最小IO单元,一定数量的page构成一个block,多个block构成plane,多个plane构成设备。
Flash读数据过程:
通过改变同一page的cell的电势,并加码成1或0,同时存储在RAM Buffer中,即完成一次读的过程,以是Flash读的最小单元是page;
Flash写数据过程:
先将一个block里面的所有cell放电,状态全部变为1,然后再写数据,如果本身是1的,则不作什么操作,如果要写0,则须要将cell充电。
那么Flash写为什么要先Erase,再写呢?为什么一定要擦出一个block,而不是一个page呢?先擦再写紧张是为理解决同一page内的不同cell之间的滋扰。要擦一个block紧张出于效率的考虑。
【SSD硬盘的顽疾】
顽疾一:先擦再写,会带来比较大的开销,形成较大的写惩罚,以是常日须要较大的缓存;
顽疾二:反复充放电,二氧化硅绝缘能力会受到损耗,终极导致没有足够电荷而宣告硬盘失落效,即所谓的wear off。
为理解决SSD硬盘的顽疾,常用方法如下:
药方1:尽可能用FreeSpace,然后集中回收已经被标记为garbage的page;
药方2:通过外部工具定期清理,比如Wiper;
药方3:TRIM,即文件在删除后,由文件系统关照SSD回收;
药方4:IO优化,比如Delay Write,即如果涌现连续的对同一IO地址的write操作,则合并为一次;
药方5:预留一部分空间给SSD掌握器自己利用,防止空间被完备写满。
1.3 块存储指令与协议1.3.1 硬盘物理接口
硬盘的指令体系紧张有ATA和SCSI。
对应ATA指令体系的物理接口有IDE和SATA,IDE是并行ATA接口,SATA是串行ATA接口;
对应SCSI指令体系的物理接口有
· 并行SCSI接口
· 串行SCSI接口(SAS)
· IBM专用串行SCSI接口(SSA)
· 采取SCSI指令体系并承载于FC协议的串行FC接口(FCP)
1.3.2 SCSI指令体系SCSI接口包括物理接口、指令体系、协议。
SCSI:Small Computer System Interface,不仅仅是硬盘采取此接口,还有扫描仪、光驱、打印机也大多采取此接口。
采取SCSI接口的硬盘必须哀求在主机侧有一个SCSI掌握器,而这个SCSI掌握器有自己的CPU,这是与ATA掌握器的一个主要差异,也正是这个缘故原由,导致SCSI硬盘比较昂贵,多用于商业系统。
SCSI协议的物理层即前面先容的SCSI物理接口。
SCSI协议的链路层卖力将数据帧成功传送到“线路”的对端,把稳这里仅仅是线路(链路)的对端,如果通信两端中间经由多跳,则要将数据帧成功传输到对端,则是传输层的职责。
SCSI协议网络层,紧张是“编址”与“寻址”。
SCSI总线编址采取SCSI ID,SCSI掌握器会占用一个7号 ID,优先级最高,其余还可以有15个ID供SCSI设备利用。
SCSI寻址采取“掌握器-通道-SCSI ID-LUN ID”,一台主机上可以通过PCI接口接多个SCSI掌握器,每个SCSI掌握器可以有多个通道(多条SCSI总线),每个通道上可以挂最多15个SCSI硬盘(或阵列),对付磁盘阵列还可以从逻辑上划分为多个LUN。
SCSI总线通信采取仲裁机制。
1.3.3 块存储指令通信协议
通信协议一遍都遵照OSI模型。
协议领悟模式一样平常有三种:利用关系、MAP关系、Tunnel关系。利用关系是指本身没有这个功能,利用别的协议来使得自己知足,比如TCP协议没有IP的寻址功能,以是TCP和IP常常是一起利用的;MAP关系即协议翻译,除了payload外,其他7层内容都从一种协议翻译为其余一种协议,iFCP便是将FC协议和以太网+TCP/IP之间做翻译;Tunnel关系即隧道封装,比如FCIP便是将FC的数据包完全的封装在以太网数据包之中。
网络通信协议一样平常有四个层次,一个寻址层,一个交互逻辑层,也便是说吸收到对方的信息后如何处理;一个是信息表示层,有点像信封即信封上的地址信息;一个是payload。
1.4 RaidRaid是为了防止硬盘破坏时规复数据的一种技能。
1.4.1 基本术语• Disk、Stripe、Segment、Block、Sector;
• Stripe从上向下,从0开始编号;
• Segment从左向右从0开始编号;
• Block在同一个Stripe里面是从上向下,从左向右;
• Block是针对Raid全局编号。
1.4.2 6种Raid模式1.4.3 Raid卡构造1.4.4 Raid与LVMRaid和LVM都是通过软件(Raid卡本色也是软件)将多张“磁盘”虚拟成一个逻辑磁盘,Raid虚拟出来的逻辑磁盘常日称之为LUN,LVM虚拟出来的逻辑磁盘常日叫LV(Logic Volume)。
SCSI协议定义出三级单元:target IDàSCSI IDàLUN ID。
• LUN是Raid卡虚拟的逻辑磁盘,PV是逻辑卷管理软件将LUN换了一个叫法PV(Physical Volume)
• VG, Volume Group卷组,由多个PV组成
• PP,Physical Partition,物理区块,每个PP由连续的多个扇区组成,VG被分成多个PP
• LP,Logical Partition,逻辑区块,由多个PP组成,这多个PP之间可以按照类似Raid 0,1等模式来构成LP
• LV,Logical Volume,逻辑卷,这是卷管理软件能够识别的最小单元
1.4.5 Raid的缺陷· RAID rebuilds are painful
· RAID spare(备份) disks increases TCO
· RAID requires a set of identical disk drivers in a single RAID group
· RAID-based systems often require expensive hardware components, such as RAID controllers, which significantly increases the system cost
· After a point, you cannot grow your RAID-based system
· RAID cannot ensure data reliability after a two-disk failure. This is one of the biggest drawbacks with RAID systems
2 存储架构2.1 传统存储架构从IO路径的角度看传统存储架构:
传统存储体系构造大致有DAS、NAS、SAN三种。
【DAS】
Direct Attached Storage,即存储介质只能供一台主机做事器利用。比如主机内部的磁盘或只有一个SCSI接口的JBOD盘阵都属于DAS。
【NAS】
Network Attached Storage,即文件操作指令通过以太网络传送到远端做事器上去实行干系操作。
【SAN】
Storage Area Network,存储区域网络,本来SAN指的是一个涉及存储各个组件的网络,其交流的协议可以是FC协议、SCSI协议、NAS协议(CIFS、NFS)等。
从上图可以看出,SAN与NAS的差异:
1)文件系统与磁盘是否在一起,前者文件系统与磁盘不属于同一个别系(设备),后者则属于同一个别系(设备)
2)通过网络传输的指令类型不同,前者是磁盘操作指令通过网络传输,后者是文件操作指令通过网络传输
3)网络传输协议类型不同,前者可能为FC、SCSI、FCoE、iSCSI,后者为CIFS、NFS等
SAN根据后端磁盘操作指令网络传输介质的不同,分为FC SAN和IP SAN两大阵营。
2.2 存储架组成长进程【第一阶段】DAS阶段1:磁盘与文件系统都在一台做事器里面
【第二阶段】DAS阶段2:磁盘JBOD外置在做事器表面
【第三阶段】SAN的低级阶段:独立的磁盘阵列
【第四阶段】SAN阶段2:网络化独立磁盘阵列
【第五阶段】NAS阶段1:廋做事端,独立NAS端
【第六阶段】NAS阶段2:独立NAS网关
【第七阶段】SAN与NAS领悟:多协议磁盘阵列、SAN磁盘阵列、NAS设备、NAS网关
【第八阶段】分布式存储阶段1:独立分布式的磁盘阵列
之前的磁盘阵列的scale out扩展能力受限于磁盘阵列的“机头”,也便是磁盘阵列掌握器的处理能力,随着云打算的发展与推动,则哀求存储系统能够实现横向无限扩展,则使得磁盘阵列的体系构造发生了变革,必须采取分布式的存储体系构造来实现。
【第九阶段】分布式存储阶段2:软件定义存储SDS
软件定义存储的基本需求:
1) 存储更加靠近打算,打算与存储领悟在一起
2) 供应存储的系统能够运行在普通的x86做事器上面,不依赖于专用硬件
3) 支持scale out无限扩展
【第十阶段】统一存储:同时支持工具、块、文件存储
比如ceph便是统一存储理念的开源实现者。
个中第八、九、十阶段是目前云打算时期的一定发展,第八和第九阶段交错存在,第十阶段是存储界的空想,但是当前来说不是必须要这样。
2.3 分布式存储架构从前面的存储架组成长进程中可以看到,分布式存储有独立和非独立的两种形态。实在这不是关键,分布式存储架构体系当前来说有两个,其差异紧张在于是否有集中的和明显的元数据做事(器)。
2.3.1 分布式存储系统通用逻辑构造分布式存储系统的通用逻辑构造如下:
对付一份数据来说,常日会有四个属性:数据在打算机系统里面的表达(或者叫存储办法)、数据所有者、数据访问者、数据存放位置。
对付一个范例的分布式存储系统至少要设计六个功能模块:
(1)数据表示
任何事物在打算机系统里面的表达办法都是用数据构造(面向工具编程里面的工具实质上也是数据构造),比如数据的副本数、数据的所有者、数据本身、数据存放位置等等。
(2)数据所有者管理
数据所有者的属性常日有账号、角色、层级等。比如某数据属于某企业的研发部门的支撑组的小李,以是小李的账户可能为xiaoli,角色是系统管理员,4级员工:某企业-研发部-支撑组。
(3)数据存放管理
对付分布式存储系统来说,数据存放管理常日会涉及:
a. 一份数据常日须要多个副本以确保数据丢失后可以规复;
b. 原始数据如何均衡的存放在集群中的多个存储节点;
c. 副本数据如何存放在集群中的多个节点以确保原始数据丢失或破坏后可以从副本规复;
d. 存放位置的逻辑表达,比如分成zone、node、partition等逻辑级别等;
e. 原始数据与存放位置的映射关系,副本数据与存放位置的映射关系,原始数据与副本的映射关系;
(4)数据存放位置均衡
由于分布式存储系统的存储节点数量是在变革的,比如某个存储节点故障,新的存储节点加入等,此时就须要重新调度数据的存放以使得数据在新的集群状态下尽可能均衡。
(5)故障检测与规复
对付分布式存储系统来说,务必要确保集群不存在单点故障,某个存储节点故障后数据能够得到及时规复。
(6)数据访问均衡
数据访问均衡要考虑:
a. 数据读/写操作在原始数据与多个副本之间的均衡;
b. 原始数据与多个副本之间的同步更新
2.3.2 分布式存储系统干系理论分布式存储系统都会涉及到三个关键指标:Consistency(同等性)、 Availability(可用性)、Partition tolerance(分区容错性)。
同等性(C):在分布式系统中的所有数据备份,在同一时候是否同样的值。
可用性(A):在集群中一部分节点故障后,集群整体是否还能相应客户真个读写要求。
分区容错性(P):如果系统正在进行数据与备份数据之间的同步更新,这时候客户端发起读写要求,则须要系统在保障同等性和保障可用性之间做出选择,要么谢绝客户端读写要求,要么容忍数据的不一致,即系统必须在C和A之间做出选择,称之为分区容错性。
【CAP理论】
CAP理论指出,任何分布式存储系统,分区容错性P是必须要实现的,我们只能在C与A之间做出选择,无法做到三者都知足。
以是任何分布式存储系统,都须要进行数据存放位置的隔离,以实现分区容错性P。
【NWR策略】
NWR是一种在分布式存储系统中用于掌握同等性级别的一种策略。
N:同一份数据的Replica的份数;
W:更新一个数据工具的时候须要确保成功更新的份数;
R:读取一个数据须要读取的Replica的份数。
NWR值的不同组合会产生不同的同等性效果,当W+R>N的时候,全体系统对付客户端来讲能担保强同等性。当W+R<N的时候只能担保终极同等性。
比如N=3、W=2、R=2:
N=3,表示,任何一个工具都必须有三个副本(Replica),W=2表示,对数据的修正操作(Write)只须要在3个Replica中的2个上面完造诣返回,R=2表示,从三个工具中要读取到2个数据工具,才能返回。
在分布式系统中,数据的单点是不许可存在的。即线上正常存在的Replica数量是1的情形是非常危险的,由于一旦这个Replica再次缺点,就可能发生数据的永久性缺点。如果我们把N设置成为2,那么,只要有一个存储节点发生破坏,就会有单点的存在。以是N必须大于2。N越高,系统的掩护和整体本钱就越高。常日把N设置为3。
当W是2、R是2的时候,W+R>N,这种情形对付客户端便是强同等性的。
在上图所示的系统中,由于W即是2,以是更新操作只须要确保完成两份就可以了。无论存储在Node3上面的第三份数据是否完成,都直接返回。假设后续的操作从Node1和Node3分别读取了两个数据。然而,Node3上面的数据尚未真正完成之前的更新操作。因此,客户端会创造读到的两个版本不一 致,这个时候,只须要选择出最新的数据就可以了。
从不等式中可以看到,当W+R>N的时候,全体系统能够担保R>N-W。也便是说,至少每次都能够读到一份最新的数据。因此只须要把最新的数据返回即可。以是,虽然做事器上的三份Replica有不一致的情形,对付客户端来讲,每次读到的数据都是最新的。以是这种情形对付客户端来讲是强同等性的。
<N,W,R>=<1,1,1>和单点运行的数据库是同一个配置。
<N,W,R>=<2,1,1>,则相称于Slave-Master模式。由于1+1不大于2,以是这种情形是可能读到非最新数据的。也便是这种配置是不一致的。
W越大,写性能越差。R越大,读性能越差。N越大,数据可靠性就越强,当然本钱也就越高。
为了保障同等性,平衡读写性能,常日的配置是:W=Q, R=Q ,Q=(N/2)+1(N=3,R=2,W=2的配置就知足这个公式)。
【分布式哈希表DHT】
1、哈希函数
哈希函数是一种打算方法,它可以把一个值A映射到一个特定例模[begin, end]之内的某个值。对付一个值的凑集{k1, k2, … , kN},哈希函数把他们均匀的映射到某个范围之中。这样,通过这些值就可以很快的找到与之对应的映射地址{index1, index2, … , indexN}。对付同一个值,哈希函数要能担保对这个值的运算结果总是相同的。
哈希函数须要经由精心设计才能够达到比较好的效果,但是总是无法达到空想的效果。多个值大概会映射到同样的地址上。这样就会产生冲突,如图中的红线所示。在设计哈希函数时要只管即便减少冲突的产生。
最大略的哈希函数便是一个求余运算: hash(A) = A % N。这样就把A这个值映射到了[0~N-1]这样一个范围之中。
2.哈希表
由于哈希函数的结果都是数值,以是如果VALUE不是数值,比如是人名,则必须要用index=hash(KEY)作为中间纽带(索引)才能够将KEY与VALUE之间建立映射关系,用于存储index与VALUE之间关系的数据表称之为哈希表。
举例:图书馆中的书会被某人借走,这样“书名”和“人名”之间就形成了KEY与VALUE的关系。假设现在有三个记录:
这便是“书名”和“人名”的对应关系,它表示某人借了某本书。书名是KEY,人名是VALUE。假设index=hash(KEY)的结果如下:
然后我们就可以在一个表中存储“人名”了:
这三个人名分别存储在0、1和2号存储空间中。当我们想要查找《钢铁是若何炼成的》这本书是被谁借走的时候,只要hash()一下这个书名,就可以找到它所对应的index,为2。然后在这个表中就可以找到对应的人名了。
当有大量的KEY VALUE对应关系的数据须要存储时,这种方法就非常有效。
3.分布式哈希表
哈希表把所有的东西都存储在一台机器上,当这台机器坏掉了之后,所存储的东西就全部消逝了。分布式哈希表可以把一整张哈希表分成多少个不同的部分,分别存储在不同的机器上,这样就降落了数据全部被破坏的风险。
4.同等性哈希函数
分布式哈希表常日采取同等性哈希函数来对机器和数据进行统一运算。
同等性哈希函数hash()对机器(常日是其IP地址)和数据(常日是其KEY值)进行统一的运算,把他们映射到一个地址空间中。假设有一个同等性哈希函数可以把一个值映射到32bit的地址空间中,从0一贯到2^32 – 1。我们用一个圆环来表示这个地址空间。
假设有N台机器,那么hash()就会把这N台机器映射到这个环的N个地方。然后我们把全体地址空间进行一下划分,使每台机器掌握一个范围的地址空间。这样,当我们向这个别系中添加数据(比如哈希表的某部分)的时候,首先利用hash()函数打算一下这个数据的index,然后找出它所对应的地址在环中属于哪个地址范围,我们就可以把这个数据放到相应的机器上。这样,就把一个哈希表分布到了不同的机器上。如下图所示:
这里蓝色的圆点表示机器,赤色的圆点表示某个数据经由hash()打算后所得出的地址。在这个图中,按照逆时针方向,每个机器霸占的地址范围为从本机器开始一贯到下一个机器为止。用顺时针方向来看,每个机器所霸占的地址范围为这台机器之前的这一段地址空间。图中的虚线表示数据会存储在哪台机器上。
剖断哈希函数好坏的四个指标:
1)平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的index区间,这样可以使得所有的index区间都得到利用。
2)单调性(Monotonicity):单调性是指如果已经有一些KEY通过哈希分派到了相应的index区间,当增加新的index区间时,哈希的结果应能够担保原有已分配的KEY可以被映射到原有的或者新的index区间,而不会被映射到旧的index凑集中的其他index区间。
3)分散性(Spread):相同的KEY被哈希到不同的index。好的哈希算法应能够只管即便避免不一致的情形发生,也便是只管即便降落分散性。
4)负载均衡性(Load):负载问题实际上是从另一个角度看待分散性问题。不同的KEY哈希到相同的index,相称于加重了index的负载。与分散性一样,这种情形也是应该避免的,好的哈希算法应能够只管即便降落index的负荷。
上面在谈论分布式哈希表的时候用到了一个hash()函数:hash(IP,KEY),这个哈希函数哀求做到所谓的单调性,则称之为同等性哈希函数。
对付分布式存储系统来说,集群节点添加、删除是常有的事情,以是哀求哈希函数也必须是同等性哈希函数,以确保数据能够重新映射到新的节点而不至于数据无法索引到。
1)节点(机器)的删除
如下图所示,如果NODE2涌现故障被删除了,如果按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变革,其它的工具没有任何的改动。
2)节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过哈希映射到环中下图所示的位置:
如果按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它工具还保持这原有的存储位置。
通过对节点的添加和删除的剖析,同等性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常得当的,避免了大量数据迁移,减小了做事器的的压力。
通过上面节点添加与删除,我们可以看到同等性哈希函数可以确保分布式存储系统的单调性、分散性和负载均衡性,但是可能会存在不平衡性:比如上图中只支配了NODE1和NODE3,object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样就造成了非常不平衡的状态。
同等性哈希算法为了知足平衡性,引入了虚拟节点。
“虚拟节点”( virtual node )是实际节点(机器)在哈希index区间的复制品( replica ),一个实际节点(机器)对应了多少个“虚拟节点”, “虚拟节点”在哈希index区间中以哈希值即index排列。
现在假设我们加入两个虚拟节点,这样全体hash环中就存在了4个虚拟节点,末了工具映射的关系图如下:
根据上图可知工具的映射关系:object1->NODE1-1,object2->NODE1-2,object3->NODE3-2,object4->NODE3-1。通过虚拟节点的引入,工具的分布就比较均衡了。
2.3.3 HDFS分布式文件存储架构HDFS是一个主/从(Mater/Slave)体系构造,从终极用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件实行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性子,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
2.3.4 Swift分布式工具存储架构
Swift是OpenStack开源云打算项目的子项目之一,被称为工具存储,供应了强大的扩展性、冗余和持久性。
Swift紧张有三个组成部分:Proxy Service、Storage Service和Consistency Service。个中Storage和Consistency做事均许可在Storage Node上。一样平常Proxy Service会单独用一个Proxy节点支配。
Proxy Server是供应Swift API的做事器进程,卖力Swift别的组件间的相互通信。对付每个客户真个要求,它将在Ring中查询Account、Container或Object的位置,并且相应地转发要求。Proxy供应了Rest-full API,并且符合标准的HTTP协议规范,这使得开拓者可以快捷构建定制的Client与Swift交互。
Storage Server供应了磁盘设备上的存储做事。在Storage Server上如何进行数据存储呢?
【Swift数据所有者管理】
Swift分为Accout、Container和Object三层数据构造,Account对应租户,记录的是包含哪些Container。Container记录包含哪些object。可以将account、container、object理解为三张sqlite数据库,三个数据库之间是树形构造关系。
下面会将讲到Swift数据按照Zone、Node(Device)、Partition和Replica四级存放,Swift用Ring数据构造来建立Object与这四级信息建立映射关系,当查询account、container、object等信息的时候,就须要访问Ring找到数据所在的位置。
【Swift数据存放管理】
Swift用Zone、Node(Device)、Partition和Replica来进行管理。
Zone:
如果所有的Node都在一个机架或一个机房中,那么一旦发生断电、网络故障等,都将造成用户无法访问。因此须要一种机制对机器的物理位置进行隔离,以知足分区容忍性(CAP理论中的P)。因此,Swift中引入了Zone的观点,把集群的Node分配到每个Zone中。
同一份数据的多个副本Replica不能放在同一个Node或zone内。
把稳,Zone的大小可以根据业务需求和硬件条件自定义,可以是一块磁盘、一台存储做事器,也可以是一个机架乃至一个IDC。下面是一个中等规模的Swift集群:
【Swift数据存放均衡】
Swift在Node数量发生变革时,数据及副本存放位置须要做调度以达到均衡,并确保可靠性。其动态均衡的算法采取所谓的“同等性哈希(consistent hashing)”算法。
Swift通过一个所谓的RING数据构造来建立object数据(包括副本)与存放位置的关系。
RING文件在系统初始化时创建,之后每次增减存储节点时,须要重新平衡一下Ring文件中的项目,以担保增减节点时,系统因此而发生迁移的数据最少。
以是,RING文件实际上便是元数据做事器,而且是具有集中的元数据做事器。
【Swift数据故障规复】
Consistency Servers的目的是查找并办理由数据破坏和硬件故障引起的缺点。紧张存在三个Server:Auditor、Updater和Replicator。 Auditor运行在每个Swift做事器的后台持续地扫描磁盘来检测工具object、Container和账号acount的完全性。如果创造数据破坏,Auditor就会将该文件移动到隔离区域,然后由Replicator卖力用一个无缺的拷贝来替代该数据。
2.3.5 Ceph分布式统一存储架构Ceph供应三种做事:工具存储、块存储和文件存储。
Ceph does not follow such traditional storage architecture; in fact, the architecture has been completely reinvented. Rather than storing and manipulating metadata, Ceph introduces a newer way: the CRUSH algorithm.
CRUSH stands for Controlled Replication Under Scalable Hashing. Instead of performing lookup in the metadata table for every client request, the CRUSH algorithm computes on demand where the data should be written to or read from. By computing metadata, the need to manage a centralized table for metadata is no longer there. The modern computers are amazingly fast and can perform a CRUSH lookup very quickly; moreover, this computing load, which is generally not too much, can be distributed across cluster nodes, leveraging the power of distributed storage. In addition to this, CRUSH has a unique property, which is infrastructure awareness. It understands the relationship between various components of your infrastructure and stores your data in a unique failure zone, such as a disk, node, rack, row, and datacenter room, among others. CRUSH stores all the copies of your data such that it is available even if a few components fail in a failure zone. It is due to CRUSH that Ceph can handle multiple component failures and provide reliability and durability.
The CRUSH algorithm makes Ceph self-managing and self-healing. In an event of component failure in a failure zone, CRUSH senses which component has failed and determines the effect on the cluster. Without any administrative intervention, CRUSH self-manages and self-heals by performing a recovering operation for the data lost due to failure. CRUSH regenerates the data from the replica copies that the cluster maintains. If you have configured the Ceph CRUSH map in the correct order, it makes sure that at least one copy of your data is always accessible. Using CRUSH, we can design a highly reliable storage infrastructure with no single point of failure. It makes Ceph a highly scalable and reliable storage system that is future ready.
CEPH FS的体系构造如下:
底层RADOS:
RADOS (Reliable, Autonomic Distributed Object Store) 是Ceph的核心之一,作为Ceph分布式文件系统的一个子项目,特殊为Ceph的需求设计,能够在动态变革和异质构造的存储设备机群之上供应一种稳定、可扩展、高性能的单一逻辑工具(Object)存储接口和能够实现节点的自适应和自管理的存储系统。事实上,RADOS也可以单独作为一种分布式数据存储系统,给适宜相应需求的分布式文件系统供应数据存储做事。
RADOS系统由OSD(Object Storage Device)、MDS(MetaData Server)和Monitor组成,这三个角色都可以是Cluster办法运行。
Moniter卖力管理Cluster Map,个中Cluster Map是全体RADOS系统的关键数据构造,管理机群中的所有成员、关系、属性等信息以及数据的分发。
2.3.6 比拟剖析这里只是谈论分布式文件系统,不谈论工具存储、块存储。
体系构造上比较,创造HDFS和Ceph都采取了“client-元数据做事器-存储节点”的构造。
元数据管理方面,HDFS用NameNode来统一管理,而且元数据在内存中管理,以是HDFS能够支撑的元数据容量与NameNode的内存来决定的。HDFS支持NameNode的HA以办理元数据管理单点故障;Ceph的元数据管理用元数据做事器MDS和监控做事Monitor来共同完成,同时都支持集群以办理单点故障。
数据存储方面,HDFS用DataNode来存储数据,Ceph用OSD来存储数据。HDFS存储块默认大小为64M,NameNode按照什么规则来将文件分成块,适宜放在哪些DataNode上呢?Ceph的MDS根据哈希同等性算法CRUSH来将数据分配到详细的OSD(PG-OSD)。
在数据同等性和冗余性方面,HDFS采取的大略同等性模型(Master-slave),支持多副本;Ceph采取Paxos或Zookeeper中的Zap算法,支持多副本和纠删码。
在利用场景方面,HDFS适用于存储超大文件,流模式访问(一次写多次读),不支持多用户并发写入和随意修正文件(只能追加);Ceph适用于存储大量小文件和随机读写等场景。
3 ceph框架剖析3.1 干系接口3.1.1 bufferraw/bufferptr/bufferlistBufferlist是ceph中最主要的类,由于Bufferlist卖力管理Ceph中所有的内存。全体Ceph中所有涉及到内存的操作,无论是msg分配内存吸收,还是OSD布局各种数据构造的持久化表示(encode/decode),再到实际磁盘操作,都将bufferlist作为根本。
bufferlist类是ceph核心的缓存类,用于保存序列化结果、数据缓存、网络通讯等,可以将bufferlist理解为一个可变长度的char数组。
Ceph中bufferlist包含三个紧张的类buffer::raw(bufferraw)、buffer::ptr(bufferptr)和buffer::list(bufferlist)。这三个类都定义在include/buffer.h中,都是buffer类的内部类,而buffer类本身没有任何内容,只起到了一个命名空间的浸染。
这三个类的职责各有不同:
buffer::raw:对应一段真实物理内存,卖力掩护这段物理内存的引用计数nref和开释操作。
buffer::ptr:对应Ceph中的一段被利用的内存,也便是某个bufferraw的一部分或者全部。
buffer::list:表示一个ptr的列表(std::list<bufferptr>),相称于将N个ptr构成一个更大的虚拟的连续内存。
buffer这三个类的相互关系可以用下面这个图来表示:
从这张图上我们就可以看出bufferlist的设计思路了: 对付bufferlist来说,仅关心一个个ptr。bufferlist将ptr连在一起,当做是一段连续的内存利用。因此,可以通过bufferlist::iterator一个字节一个字节的迭代全体bufferlist中的所有内容,而不须要关心到底有几个ptr,更不用关心这些ptr到底和系统内存是怎么对应的;也可以通过bufferlist::write_file方法直接将bufferlist中的内容输出到一个文件中;或者通过bufferlist::write_fd方法将bufferlist中的内容写入到某个fd中。
与bufferlist相对的是卖力管理系统内存的bufferraw。bufferraw只关心一件事:掩护其所管理的系统内存的引用计数,并且在引用计数减为0时——即没有ptr再利用这块内存时,开释这块内存。
连接bufferlist和bufferraw的是bufferptr。bufferptr关心的是如何利用内存。每一个bufferptr一定有一个bufferraw为其供应系统内存,然后ptr决定利用这块内存的哪一部分。bufferlist只用通过ptr才能对应到系统内存中,而bufferptr而可以独立存在,只是大部分ptr还是为bufferlist做事的,独立的ptr利用的场景并不是很多。
通过引入ptr这样一个中间层次,bufferlist利用内存的办法可以非常灵巧,这里可以举两个场景:
1. 快速encode/decode
在Ceph中常常须要将一个bufferlist编码(encode)到另一个bufferlist中,例如在msg发送的时候,常日msg拿到的osd等逻辑层通报给它的bufferlist,然后msg还须要给这个bufferlist加上头和尾,而头和尾也是用bufferlist表示的。这时候,msg常日会布局一个空的bufferlist,然后将头、尾、内容都encode到这个空的bufferlist。而bufferlist之间的encode实际只须要做ptr的copy,而不涉及到系统内存的申请和Copy,效率较高。
2. 一次分配,多次利用
我们都知道,调用malloc之类的函数申请内存是非常重量级的操作。利用ptr这个中间层可以缓解这个问题,即我们可以一次性申请一块较大的内存,也便是一个较大的bufferraw,然后每次须要内存的时候,布局一个bufferptr,指向这个bufferraw的不同部分。这样就不再须要向系统申请内存了。末了将这些ptr都加入到一个bufferlist中,就可以形成一个虚拟的连续内存。
3.1.2 序列化encode/反序列化decode1.Ceph序列化的办法
序列化(ceph称之为encode)的目的是将数据构造表示为二进制流的办法,以便通过网络传输或保存在磁盘等存储介质上,其逆过程称之为反序列化(ceph称之为decode)。 例如对付字符串“abc”,其序列化结果为8个字节(bytes):03 00 00 00 61 62 63,个中头四个字节(03 00 00 00)表示字符串的长度为3个字符,后3个字节(61 62 63)分别是字符“abc”的ASCII码的16进制表示。
Ceph采取little-endian的序列化办法,即低地址存放最低有效字节,以是32位整数0x12345678的序列化结果为78 56 34 12。
由于序列化在全体系统中是非常基本,非常常用的功能,Ceph将其序列化办法设计为一个通用的框架,即任意支持序列化的数据构造,都必须供应一对定义在全局命名空间上的序列化/反序列化(encode/decode)函数。例如,如果我们定义了一个构造体inode,就必须在全局命名空间中定义以下两个方法:
encode(struct inode, bufferlist bl);
decode(struct inode, bufferlist::iterator bl);
在此根本上,序列化的利用就变得非常随意马虎 。 即对付任意可序列化的类型T的实例instance_T,都可以通过以下语句:
::encode(instance_T, instance_bufferlist);
将instance_T序列化并保存到bufferlist类的实例instance_bufferlist中。
以下代码演示了将一个韶光戳以及一个inode序列化到一个bufferlist中:
序列化后的数据可以通过反序列化方法读取,例如以下代码片段从一个bufferlist中反序列化一个韶光戳和一个inode(条件是该bl中已经被序列化了一个utime_t和一个inode,否则会报错):
2.数据构造的序列化
Ceph为其所有用到数据类型供应了序列化方法或反序列化方法,这些数据类型包括了绝大部分根本数据类型(int、bool等)、构造体类型(ceph_mds_request_head等)、凑集类型(vector、list、set、map等)、以及自定义的繁芜数据类型(例如表示inode的inode_t等)。
2.1 基本数据类型的序列化
基本数据类型的序列化结果基本便是该类型在内存中的表示形式。基本数据类型的序列化方法利用手工编写。在手工编写encode方法过程中,为了避免重复代码,借助了WRITE_RAW_ENCODER和WRITE_INTTYPE_ENCODER两个宏:
WRITE_RAW_ENCODER宏函数实际上是通过调用encode_raw实现的,而encode_raw调用bufferlist的append的方法,通过内存拷贝,将数据构造放入到bufferlist中。
定义在include/encoding.h中,包括以下基本数据类型:
2.2 凑集类数据类型的序列化
凑集数据类型序列化的基本思路包括两步:打算序列化凑集大小,然后序列化凑集内的所有元素。
例如vector<T>& v的序列化方法:
个中元素的序列化通过调用该元素的encode方法实现。
常用凑集数据类型的序列化已经由Ceph实现,位于include/encoding.h中,包括以下凑集类型:
凑集类型的序列化方法皆为基于泛型(模板类)的实现办法,适用于所有泛型派生类。
2.3 构造体类型的序列化
构造体类型的序列化方法与基本数据类型的序列化方法同等。
在构造体定义完成后,通过调用WRITE_RAW_ENCODER宏函数天生构造体的全局encode方法,比如:
2.4 繁芜数据类型的序列化
除以上两种业务无关的数据类型外,其它数据类型的序列化实现包括两部分:先在类型内部现实encode方法,然后将类型内部的encode方法重定义为全局方法。
比如以CrushWrapper类为例(后面命令下发解析流程中会用到):
CrushWrapper内部实现了encode和decode两个方法,WRITE_CLASS_ENCODER宏函数将这两个方法转化为全局方法。
WRITE_CLASS_ENCODER宏函数定义于include/encoding.h中,其定义如下:
繁芜数据构造内部的encode方法的实现办法常日是调用其内部紧张数据构造的encode方法。
3.2 逻辑构造3.2.1 0层分解0层分解紧张描述ceph与其他外部的关系。
Ceph的外部至少有两个:一个是裸金属上的操作系统,常日情形下是Linux,一个是利用ceph做事的clients,从下面这张图可知这些clients可能有哪些:
从网络构造的角度来看:
Ceph 推举利用两个网络:
• 前端(北向)网络( a public (front-side) network)连接客户端和集群
• 后端/东西向网络 (a cluster (back-side) network)来连接 Ceph 各存储节点
这么做,紧张是从性能(OSD 节点之间会有大量的数据拷贝操作)和安全性(两网分离)考虑。可以在 Ceph 配置文件的 [global] 部分配置这两个网络:
3.2.2 1层分解3.2.2.1 模块分解Ceph Object Storage Device (OSD): As soon as your application issues a writes operation to the Ceph cluster, data gets stored in the OSD in the form of objects. This is the only component of the Ceph cluster where actual user data is stored, and the same data is retrieved when the client issues a read operation. Usually, one OSD daemon is tied to one physical disk in your cluster. So, in general, the total number of physical disks in your Ceph cluster is the same as the number of OSD daemons working underneath to store user data on each physical disk.
Ceph 支持的数据盘上的 xfs、ext4 和 btrfs 文件系统,它们都这天记文件系统(其特点是文件系统将每个提交的数据变革保存到日志文件,以便在系统崩溃或者掉电时规复数据),三者各有上风和劣势:
• btrfs (B-tree 文件系统) 是个很新的文件系统(Oracel 在2014年8月发布第一个稳定版),它将会支持许多非常高大上的功能,比如透明压缩( transparent compression)、可写的COW 快照(writable copy-on-write snapshots)、去重(deduplication )和加密(encryption )
• xfs 和 btrfs 比较较ext3/4而言,在高伸缩性数据存储方面具有上风
• Ceph明确推举在生产环境中利用 XFS,在开拓、测试、非关键运用上利用 btrfs
Ceph Monitors (MON): Ceph monitors track the health of the entire cluster by keeping a map of the cluster state. It maintains a separate map of information for each component, which includes an OSD map, MON map, PG map, and CRUSH map. All the cluster nodes report to Monitor nodes and share information about every change in their state. The monitor does not store actual data; this is the job of the OSD.
Ceph Metadata Server (MDS): The MDS keeps track of file hierarchy and stores metadata only for the CephFS file system. The Ceph block device and RADOS gateway does not require metadata, hence they do not need the Ceph MDS daemon. The MDS does not serve data directly to clients, thus removing the single point of failure from the system.
RADOS: The Reliable Autonomic Distributed Object Store (RADOS) is the foundation of the Ceph storage cluster. Everything in Ceph is stored in the form of objects, and the RADOS object store is responsible for storing these objects irrespective of their data types. The RADOS layer makes sure that data always remains consistent. To do this, it performs data replication, failure detection and recovery, as well as data migration and rebalancing across cluster nodes.
librados: The librados library is a convenient way to gain access to RADOS with support to the PHP, Ruby, Java, Python, C, and C++ programming languages. It provides a native interface for the Ceph storage cluster (RADOS), as well as a base for other services such as RBD, RGW, and CephFS, which are built on top of librados. Librados also supports direct access to RADOS from applications with no HTTP overhead.
常日情形下librados的实现逻辑如下:
以是RadosClient是librados的核心。
RADOS Block Devices (RBDs): RBDs which are now known as the Ceph block device, provides persistent block storage, which is thin-provisioned, resizable, and stores data striped over multiple OSDs. The RBD service has been built as a native interface on top of librados.
RADOS Gateway interface (RGW): RGW provides object storage service. It uses librgw (the Rados Gateway Library) and librados, allowing applications to establish connections with the Ceph object storage. The RGW provides RESTful APIs with interfaces that are compatible with Amazon S3 and OpenStack Swift.
CephFS: The Ceph File system provides a POSIX-compliant file system that uses the Ceph storage cluster to store user data on a file system. Like RBD and RGW, the CephFS service is also implemented as a native interface to librados.
3.2.2.2 流程视图3.3 关键观点
以client向ceph集群写入数据为例,涉及如下图所示的流程和关键观点。
For a read-and-write operation to Ceph clusters,
· clients first contact a Ceph monitor and retrieve a copy of the cluster map, which is inclusive of 5 maps, namely the monitor, OSD, MDS, and CRUSH and PG maps. These cluster maps help clients know the state and configuration of the Ceph cluster.
· Next, the data is converted to objects using an object name and pool names/IDs.
· This object is then hashed with the number of PGs to generate a final PG within the required Ceph pool.
· This calculated PG then goes through a CRUSH lookup function to determine the primary, secondary, and tertiary OSD locations to store or retrieve data.
Once the client gets the exact OSD ID, it contacts the OSDs directly and stores the data. All of these compute operations are performed by the clients; hence, they do not affect the cluster performance.
3.3.1 Object 工具An object has an identifier, binary data, and metadata consisting of a set of name/value pairs. The semantics are completely up to(取决于) Ceph Clients. For example, CephFS uses metadata to store file attributes such as the file owner, created date, last modified date, and so forth.
工具详细到存储介质比如disk上面表示为什么呢?Each object corresponds to a file in a filesystem, which is stored on an Object Storage Device. Ceph OSD Daemons handle the read/write operations on the storage disks.
3.3.2 Pool 池为了管理多个PG,ceph搞出一个Pool逻辑观点。
Ceph的Cluster创建:
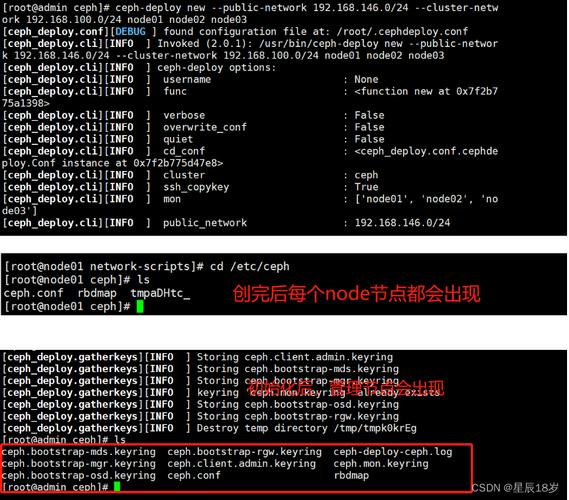
ceph-deploy new {host [host], ...}
可见ceph集群因此物理节点为最小单元。
Ceph的Pool创建:
ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] \
[crush-ruleset-name] [expected-num-objects]
ceph osd pool create {pool-name} {pg-num} {pgp-num} erasure \
[erasure-code-profile] [crush-ruleset-name] [expected_num_objects]
每个集群可以有多个pools。其属性包括:
• 所有性和访问权限
• object工具数量
• PG 数目
• CRUSH 规则凑集
Ceph Pool 有两种类型:
• Replicated pool:拷贝型 pool,通过天生工具的多份拷贝来确保在部分 OSD 丢失的情形下数据不丢失。这种类型pool 须要更多的裸存储空间,但是它支持所有的 pool 操作。
• Erasure-coded pool:纠错码型 pool(类似于 Software RAID)。在这种 pool 中,每个数据工具都被存放在 K+M 个数据块中:工具被分成 K 个数据块和 M 个编码块。
可见,这种 pool 用更少的空间实现存储,即节约空间;纠删码实现了高速的打算,但有2个缺陷,一个是速率慢,一个是只支持工具的部分操作(比如:不支持局部写)。
When you first deploy a cluster without creating a pool, Ceph uses the default pools for storing data. A pool provides you with:
· Resilience(容忍度): You can set how many OSD are allowed to fail without losing data. For replicated pools, it is the desired number of copies/replicas of an object. A typical configuration stores an object and one additional copy (i.e., size = 2), but you can determine the number of copies/replicas. For erasure coded pools, it is the number of coding chunks (i.e. m=2 in the erasure code profile)
· Placement Groups: You can set the number of placement groups for the pool. A typical configuration uses approximately 100 placement groups per OSD to provide optimal balancing without using up too many computing resources. When setting up multiple pools, be careful to ensure you set a reasonable number of placement groups for both the pool and the cluster as a whole.
· CRUSH Rules: When you store data in a pool, a CRUSH ruleset mapped to the pool enables CRUSH to identify a rule for the placement of the object and its replicas (or chunks for erasure coded pools) in your cluster. You can create a custom CRUSH rule for your pool.
· Snapshots: When you create snapshots with ceph osd pool mksnap, you effectively take a snapshot of a particular pool.
3.3.3 PG MapIt holds the PG version, time stamp, last OSD map epoch, full ratio, and near full ratio information. It also keeps track of each PG ID, object count, state, state stamp, up and acting OSD sets, and finally, the scrub details.
To check your cluster PG map, execute the following:
# ceph pg dump
PG类保存的是一个PG的信息,PG Map保存的是Cluster.pool的所有PG信息。
PG的核心是为了管理object本身及object的副本存放在哪些OSD上面。
• Ceph引入PG的目的是为了减少将object直接映射到OSD的繁芜度;
• 一个obejct对应一个PG,但是反过来,一个PG可以对应多个object。也便是说一个PG可以为多个object供应存放位置管理的做事;
• 一个PG所关联的OSD个数即是它所做事的obejct的副本数(包括object本身,比如2副本、3副本);多个PG可能共享同一OSD;
• PG用acting set和up set来管理存放在哪些OSD上以及OSD顺序,比如[0,8,3]表示osd.0是primary osd,osd.8,osd.3是replica osd。
• PG的acting/up set里面的OSD有三种:
n 主 (primary) OSD:在 acting set 中的首个 OSD,卖力吸收客户端写入数据;默认情形下,供应数据读做事,但是该行为可以被修正。它还卖力 peering 过程,以及在须要的时候申请 PG temp;
n 次 (replica)OSD:在 acting set 中的除了第一个以外的别的 OSD;
n 流浪(stray)OSD:已经不是 acting set 中了,但还没有被奉告去删除数据的OSD;
• PG 是Ceph 集群做清理(scrubbing)的基本单位,也便是说数据清理是一个一个PG来做的;
• PG 和 OSD 之间的映射关系由 CRUSH MAP决定,决定的依据是 CRUSH 规则(rules);
3.3.4 OSD MapIt stores some common fields, such as cluster ID, epoch for OSD map creation and last changed, and information related to pools, such as pool names, pool ID, type, replication level, and PGs. It also stores OSD information such as count, state, weight, last clean interval, and OSD host information.
You can check your cluster's OSD maps by executing the following:
# ceph osd dump
OSD类保存一个OSD节点的信息,OSD Map保存Cluster.pool的所有OSD节点信息。
OSDService类是OSD节点信息的掩护和管理者。
3.3.5 Monitor MapIt holds end-to-end information about the monitor node, which includes the Ceph cluster id, monitor hostname, and IP address with the port number. It also stores the current epoch for map creation and last changed time too.
You can check your cluster's monitor map by executing the following:
# ceph mon dump
3.3.6 CRUSH MapIt holds information on your clusters devices, buckets, failure domain hierarchy, and the rules defined for the failure domain when storing data.
To check your cluster CRUSH map, execute the following:
# ceph osd crush dump
1)获取CRUSH map的二进制文件
ceph osd getcrushmap-o {compiled-crushmap-filename}
# ceph osd getcrushmap -o crushmap.map
2)反编译,将二进制文件转成文本文件
crushtool -d {compiled-crushmap-filename} -o {decompiled-crushmap-filename}
# crushtool -d crushmap.map -o crushmap.txt
3)查看crush map
# vim crushmap.txt
从下面反汇编出来的crush map中:
weight: Ceph writes data evenly across the cluster disks, which helps in performance and better data distribution. This forces all the disks to participate in the cluster and make sure that all cluster disks are equally utilized, irrespective of their capacity. To do so, Ceph uses a weighting mechanism. CRUSH allocates weights to each OSD. The higher the weight of an OSD, the more physical storage capacity it will have. A weight is the relative difference between device capacities. We recommend using 1.00 as the relative weight for a 1 TB storage device. Similarly, a weight of 0.5 would represent approximately 500 GB, and a weight of 3.00 would represent approximately 3 TB.
alg: Ceph supports multiple algorithm bucket types for your selection. These algorithms differ from each other on the basis of performance and reorganizational efficiency. Let's briefly cover these bucket types:
Uniform: The uniform bucket can be used if the storage devices have exactly the same weight. For non-uniform weights, this bucket type should not be used. The addition or removal of devices in this bucket type requires the complete reshuffling(洗牌) of data, which makes this bucket type less efficient.
List: List buckets aggregate their contents as linked lists and can contain storage devices with arbitrary weights. In the case of cluster expansion, new storage devices can be added to the head of a linked list with minimum data migration. However, storage device removal requires a significant amount of data movement. So, this bucket type is suitable for scenarios under which the addition of new devices to the cluster is extremely rare or non-existent(这句话彷佛说反了?). In addition, list buckets are efficient for small sets of items, but they may not be appropriate for large sets.
Tree: Tree buckets store their items in a binary tree. It is more efficient than list buckets because a bucket contains a larger set of items. Tree buckets are structured as a weighted binary search tree with items at the leaves. Each interior node knows the total weight of its left and right subtrees and is labeled according to a fixed strategy. Tree buckets are an all-around boon(全能的), providing excellent performance and decent reorganization efficiency.
Straw: To select an item using List and Tree buckets, a limited number of hash values need to be calculated and compared by weight. They use a divide and conquer strategy(分而治之), which gives precedence to certain items (for example, those at the beginning of a list). This improves the performance of the replica placement process but introduces moderate reorganization when bucket contents change due to addition, removal, or re-weighting.
The straw bucket type allows all items to compete fairly(公正竞争) against each other for replica placement. In a scenario where removal is expected and reorganization ef ciency is critical, straw buckets provide optimal migration behavior between subtrees. This bucket type allows all items to fairly "compete" against each other for replica placement through a process analogous to a draw of straws(抽签).
Straw2: This is an improved straw bucket that correctly avoids any data movement between items A and B, when neither A's nor B's weights are changed. In other words, if we adjust the weight of item C by adding a new device to it, or by removing it completely, the data movement will take place to or from C, never between other items in the bucket. Thus, the straw2 bucket algorithm reduces the amount of data migration required when changes are made to the cluster.
Rules: The CRUSH maps contain CRUSH rules that determine the data placement for pools. As the name suggests, these are the rules that defined the pool properties and the way data gets stored in the pools. They defined the replication and placement policy that allows CRUSH to store objects in a Ceph cluster. The default CRUSH map contains a rule for default pools, that is, rbd. The general syntax of a CRUSH rule looks like this:
ruleset: An integer value; it classifies a rule as belonging to a set of rules.
type: A string value; it's the type of pool that is either replicated or erasure coded.
min_size: An integer value; if a pool makes fewer replicas than this number, CRUSH will not select this rule.
max_size: An integer value; if a pool makes more replicas than this number, CRUSH will not select this rule.
step take: 定义从CRUSH MAP的哪个bucket开始查找,default表示从root节点开始.
step choose firstn {num} type {bucket-type}: This selects the number (N) of buckets of a given type, where the number (N) is usually the number of replicas in the pool (that is, pool size):
‰ If num == 0, select N buckets
‰ If num > 0 && < N, select num buckets ‰
If num < 0, select N - num buckets
Choose与chooseleaf的差异是前者只是选择num个bucket-type类型的bucket,后者选择num个bucket-type类型的bucket后,再进入每个bucket的子树选择叶子节点;
Firstn或indep,前者表示按照广度优先搜索,后者表示深度优先搜索。
step chooseleaf firstn {num} type {bucket-type}: This first selects a set of buckets of a bucket type, and then chooses the leaf node from the subtree of each bucket in the set of buckets. The number of buckets in the set (N) is usually the number of replicas in the pool:
‰ If num == 0, selects N buckets
‰ If num > 0 && < N, select num buckets
‰ If num < 0, select N - num buckets
step emit: This first outputs the current value and empties the stack. This is typically used at the end of a rule but may also be used to form different trees in the same rule.
3.4 紧张流程3.4.1 命令下发、解析流程ceph的大部分命令都是在monitor节点上实行和解析的。
首先,用户通过ssh登录到ceph集群,实际上登录到monitor节点上面,monitor deamon供应命令窗口。比如:
Extract the CRUSH map from any of the monitor nodes:
# ceph osd getcrushmap -o crushmap_compiled_file
那么ceph的命令下发和解析流程是怎么的呢?
1.所有命令文本都定义在mon/MonCommands.h文件中:
2.命令解析与实行
3.4.2 RBD客户端写入过程3.4.2.1 RBD客户端利用RBD方法假设RBD客户端是虚机:
在客户端利用 rbd 时一样平常有两种方法:
· 第一种 是 Kernel rbd
便是创建了rbd设备后,把rbd设备map到内核中,形成一个虚拟的块设备,这时这个块设备同其他通用块设备一样,一样平常的设备文件为/dev/rbd0,后续直策应用这个块设备文件就可以了。也可以把 /dev/rbd0 格式化后 mount 到某个目录,当做普通的文件来利用。
· 第二种是 librbd 办法。便是创建了rbd设备后,这时可以利用librbd、librados库进行访问管理块设备。这种办法不会map到内核,直接调用librbd供应的接口,可以实现对rbd设备的访问和管理。
运用写入rbd块设备的过程:运用调用 librbd 接口或者对linux 内核虚拟块设备写入二进制块。下面以 librbd作为ceph client为例:
1. 首先cluster = rados.Rados(conffile = 'ceph.conf'),用当前的这个ceph的配置文件去创建一个rados,这里紧张是解析ceph.conf中中的集群配置参数。然后将这些参数的值保存在rados中。
2. cluster.connect() ,这里将会创建一个radosclient的构造,这里会把这个构造紧张包含了几个功能模块:管理模块Messager,数据处理模块Objector,finisher线程模块。
3. ioctx = cluster.open_ioctx('mypool'),为一个名字叫做mypool的存储池创建一个ioctx ,ioctx中会指明radosclient与Objector模块,同时也会记录mypool的信息,包括pool的参数等。
4. rbd_inst.create(ioctx,'myimage',size) ,创建一个名字为myimage的rbd设备,之后便是将数据写入这个设备。
5. image = rbd.Image(ioctx,'myimage'),创建image构造,这里该构造将myimage与ioctx 联系起来,后面可以通过image构造直接找到ioctx。这里会将ioctx复制两份,分为为data_ioctx和md_ctx,一个用来处理rbd存储的数据,一个用来处理rbd的管理数据。
6. image.write(data,0),通过image开始了一个写要求的生命的开始。这里指明了request的两个基本要素 buffer=data 和 offset=0。由这里开始进入了ceph的天下。
Python将image.write(data,0)连接为librbd.cc 文件中的Image::write():
3.4.2.2 客户端写入涉及到的映射Mapping以client向ceph集群写入数据为例,涉及如下图所示的流程和关键观点。
For a read-and-write operation to Ceph clusters,
· clients first contact a Ceph monitor and retrieve a copy of the cluster map, which is inclusive of 5 maps, namely the monitor, OSD, MDS, and CRUSH and PG maps. These cluster maps help clients know the state and configuration of the Ceph cluster.
· Next, the data is converted to objects using an object name and pool names/IDs.
· This object is then hashed with the number of PGs to generate a final PG within the required Ceph pool.
· This calculated PG then goes through a CRUSH lookup function to determine the primary, secondary, and tertiary OSD locations to store or retrieve data.
客户端写入便是将二进制数据块写入到底层的OSD/Disk上面去,首先则须要客户端知道数据该当写入哪个OSD,需经历(Pool, Object) → (Pool, PG) → OSD set → OSD/Disk 完全的映射过程。这个过程中包含了两次映射:
第一次是数据x到PG的映射。PG是抽象的存储节点,它不会随着物理节点的加入或则离开而增加或减少,因此数据到PG的映射是稳定的。
第二次PG ID到OSD ID的映射。
个中第一次映射包括下面两个关系:
• 文件 :object = 1 : n (由客户端实时打算)
• object :PG = n : 1 (由客户端利用哈希算法打算)
第二次映射包括下面关系:
• PG :OSD = m : n (由 MON 根据 CRUSH 算法打算)
第一次映射:
(1)创建 Pool 和它的 PG。根据上述的打算过程,PG 在 Pool 被创建后就会被 MON 在根据 CRUSH 算法打算出来的 PG 该当所在多少的 OSD 上被创建出来了。也便是说,在客户端写入工具的时候,PG 已经被创建好了,PG 和 OSD 的映射关系已经是确定了的。
如何确定一个pool该当有多少PG呢?
Ceph 不会自己打算,而是给出了一些参考原则,让 Ceph 用户自己打算:
• 少于 5 个 OSD, 建议设为128
• 5到 10 个 OSD,建议设为 512
• 10 到 50 个 OSD,建议设为 4096
• 50 个 OSD 以上,就须要有更多的权衡来确定 PG 数目
If you have more than 50 OSDs, we recommend approximately 50-100 placement groups per OSD to balance out resource usage, data durability and distribution.
For a single pool of objects, you can use the following formula to get a baseline:
Where pool size is either the number of replicas for replicated pools or the K+M sum for erasure coded pools (as returned by ceph osd erasure-code-profile get).
The result should be rounded up(取整) to the nearest power of two. Rounding up is optional, but recommended for CRUSH to evenly balance the number of objects among placement groups.
As an example, for a cluster with 200 OSDs and a pool size of 3 replicas, you would estimate your number of PGs as follows:
When using multiple data pools for storing objects, you need to ensure that you balance the number of placement groups per pool with the number of placement groups per OSD so that you arrive at a reasonable total number of placement groups that provides reasonably low variance(方差) per OSD without taxing system resources or making the peering process too slow.
上面的打算过程的打算公式::
一个Pool该当有多少个PG,一样平常根据上面的辅导原则来确定,那么背后的逻辑是什么?
• 从数据可靠性角度,一个OSD上的PG不宜过多,如果OSD增加了,PG数量也应适当增加
考虑pool 的 size 为 3,表明每个 PG 会将数据存放在 3 个 OSD 上。当一个 OSD down 了后,一定间隔后将开始 recovery 过程,recovery结束前,有部分 PG 的数据将只有两个副本。这时候和须要被规复的数据的数量有关系,如果该 OSD 上的 PG 过多,则花的韶光将越长,风险将越大。如果此时再有一个 OSD down 了,那么将有一部分 PG 的数据只有一个副本,recovery 过程连续。如果再涌现第三个 OSD down 了,那么可能会涌现部分数据丢失。可见,每个 OSD 上的PG数目不宜过大,否则,会降落数据的持久性。这也就哀求在添加 OSD 后,PG 的数目在须要的时候也须要相应增加。
• 从数据的均匀分布性角度,一个pool的PG也不宜过少
CRUSH 算法会伪随机地担保 PG 当选中来存放客户真个数据,它还会尽可能地担保所有的 PG 均匀分布在所有的 OSD 上。比方说,有10个OSD,但是只有一个 size 为 3 的 pool,它只有一个 PG,那么10个 OSD 中将只有三个 OSD 被用到。但是 CURSH 算法在打算的时候不会考虑到OSD上已有数据的大小。比方说,100万个4K工具共4G均匀地分布在10个OSD上的1000个PG内,那么每个 OSD 上大概有400M 数据。再加进来一个400M的工具(假设它不会被分割),那么有三块 OSD 年夜将有 400M + 400M = 800 M 的数据,而其它七块 OSD 上只有 400M 数据。
• 从资源花费的角度,不是PG越多越好
PG 作为一个逻辑实体,它须要花费一定的资源,包括内存,CPU 和带宽。太多 PG 的话,则占用资源会过多。
• 从数据清理scrub韶光的较多,PG的object数量或数据量不宜太多
Ceph 的清理事情因此 PG 为单位进行的。如果一个 PG 内的数据太多,则其清理韶光会很长。
PG与OSD的关系在pool创建的时候就已经确定了,如何确定的呢?
从上面创建pool的参数可以看出须要指定pool名称、pg数量、crush-ruleset名称、期望的object数量。PG与OSD的映射建立请看第二次映射过程。
(2)Ceph 客户端通过哈希算法打算出存放 object 的 PG 的 ID:
• 客户端输入 pool ID 和 object ID (比如 pool = “liverpool” and object-id = “john”)
• ceph 对 object ID 做哈希
• ceph 对该 hash 值取 PG 总数的模,得到 PG 编号 (比如 58)(两次hash打算基本担保了一个 pool 的所有 PG 将会被均匀地利用)
• ceph 对 pool ID 取 hash (比如 “liverpool” = 4)
• ceph 将 pool ID 和 PG ID 组合在一起(比如 4.58)得到 PG 的完全ID。也便是:PG-id = hash(pool-id). hash(objet-id) % PG-number
第二次映射:PG ID—>OSD ID
(3)客户端通过 CRUSH 算法打算出(或者说查找出) object 该当会被保存到 PG 中哪个 OSD 上。(把稳:这里是说”该当“,而不是”将会“,这是由于 PG 和 OSD 之间的关系是已经确定了的,那客户端须要做的便是须要知道它所选中的这个 PG 到底将会在哪些 OSD 上创建工具。)。这步骤也叫做 CRUSH 查找。
对 Ceph 客户端来说,只要它得到了 Cluster map,就可以利用 CRUSH 算法打算出某个 object 将要所在的 OSD 的 ID,然后直接与它通信:
• Ceph client 从 MON 获取最新的 cluster map
• Ceph client 根据上面的第(2)步打算出该 object 将要在的 PG 的 ID
• Ceph client 再根据 CRUSH 算法打算出 PG 中目标主和次 OSD 的 ID。也便是:OSD-ids = CURSH(PG-id, cluster-map, cursh-rules)
先看pool创建过程,设置PG数量、object数量、ruleset等:
PG什么时候创建呢?如何建立OSD的映射关系的呢?
crush_do_rule()函数先大略先容到这里,在先容CRUSH算法的时候再仔细剖析。
OSD Map建立(OSD Map的创建过程中同时创建了Crush Map):
一个osd map的实例:
可见OSD Map包括:fsid、pool及参数、osd状态及权重等。
下面是CRUSH MAP的创建:
CRUSH Map的内容紧张有四个部分:devices、types、buckets、rules。
CRUSH Map实在便是一个树形的构造,叶子节点是device(也便是osd),其他的节点称为bucket节点,这些bucket都是虚构的节点,可以根据物理构造进行抽象,当然树形构造只有一个终极的根节点称之为root节点,中间虚拟的bucket节点可以是数据中央抽象、机房抽象、机架抽象、主机抽象等如下图:
CRUSH Ruleset的建立:
从上面的关系我们可以看出:
OSD MAP保存了Pool及OSD的状态和属性;
PG MAP保存了PG与OSD的映射关系;
CRUSH MAP则保存了集群的物理拓扑与逻辑拓扑关系(types、buckets);
CRUSH MAP中的ruleset则用来表达数据映射的策略。这些策略可以灵巧的设置object存放的区域。比如可以指定 pool1中所有objects放置在机架1上,所有objects的第1个副本放置在机架1上的做事器A上,第2个副本分布在机架1上的做事器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的做事器上,第2个副本分布在机架3的服器上,第3个副本分布在机架4的做事器上。
3.4.2.3 客户端写入涉及到的数据构造在先容函数实行过程之前,先将涉及到的数据构造及其浸染进行剖析:
1.rados构造,首先创建io环境,创建rados信息,将配置文件中的数据构造化到rados中。
2.根据rados创建一个rados client的客户端构造,该构造包括了三个主要的模块,finiser 回调处理线程、Messager处理构造、Objector数据处理构造。末了的数据都是要封装成 通过Messager发送给目标的osd。
3.根据pool的信息与radosclient创建一个ioctx,这里面包好了pool干系的信息,然后得到这些信息后在数据处理时会用到。
4.紧接着会复制这个ioctx到imagectx中,变成data_ioctx与md_ioctx数据处理通道,前者用于处理image的写入或读取的数据,后者用于管理数据处理。末了将imagectx封装到image构造当中。之后所有的写操作都会通过这个image进行。顺着image的构造可以找到前面创建并且可以利用的数据构造。
5.通过最右上角的image进行读写操作,当读写操作的工具为image时,这个image会开始处理要求,然后这个要求经由处理拆分成object工具的要求。拆分后会交给objector进行处理查找目标osd,当然这里利用的便是crush算法,找到目标osd的凑集与主osd。
6.将要求op封装成MOSDOp,然后交给SimpleMessager处理,SimpleMessager会考试测验在已有的osd_session中查找,如果没有找到对应的session,则会重新创建一个OSDSession,并且为这个OSDSession创建一个数据通道pipe,把数据通道保存在SimpleMessager中,可以下次利用。
7.pipe 会与目标osd建立Socket通信通道,pipe会有专门的写线程writer来卖力socket通信。在线程writer中会先连接目标ip,建立通信。从SimpleMessager收到后会保存到pipe的outq行列步队中,writer线程其余的一个用场便是监视这个outq行列步队,当行列步队中存在等待发送时,会就将写入socket,发送给目标OSD。
3.4.2.4 RBD客户端写入流程RBD客户端写入涉及到三层:librbd、(librados+rados)和OSD。
每层见到的数据形式不一样,librbd看到的是二进制块,librados及rados看到的是条带和工具,OSD看到的是工具对应的文件。
第一层:librbd对二进制块进行分块,默认块大小为 4M,成为一个工具
Ceph客户端,这里即librdb所见的是一个完全的连续的二进制数据块。
数据如何按照object进行拆分的呢?
librbd对写入的二进制块履行所谓的“条带化stripe”,从而使得数据可以分散存储在多个object。那么条带宽度、数量;object大小、数量;PG数量是怎么来定义的呢?
PG数量由创建或修正pool来设定:
条带及object属性由创建RBD镜像时设定:
常日情形下,pool size指的是此pool的副本数量,比如默认为3;pool order指的是object大小折算成2的幂次,比如默认为22,即object的大小默认为4M。
镜像创建时条带、object等属性设置对应的代码:
从上面的代码剖析可以看出object大小与条带宽度、数量有什么关系呢:
· object大小=2^order
· 条带宽度必须要小于即是object大小,而且必须要能够被object大小整除
第二层:librados
librados 卖力在 RADOS 中创建工具(object),其大小为 pool 的 order 决定,默认情形下 order = 22 此时 object 大小为 4MB。
librados 掌握哪个条带写入哪个 OSD (条带-à写入哪个----> object ----位于哪个 ----> OSD)。
Librados将一块二进制数据(文件)分为多个 object 来保存,从而使得对一个file 的多个读写可以分在多个 object 进行,从而可以防止某个 file非常大或者非常忙时单个节点称为性能瓶颈。还可以将 object 进一步条带化为多个条带(stripe unit)。条带(stripe)是 librados 通过 ODS 写入数据的基本单位。这么做的好处是在保持工具数目的同时,进一步减少可以同步读写的粒度(从 object 粒度减少到 stripe 粒度),从而提高读写效率。
Ceph 的条带化行为(如何划分条带和如何写入条带)受三个参数掌握:
• order:RADOS Object 的大小为 2^[order] bytes。默认的 oder 为 22,这时候工具大小为4MB。最小 4k,最大 32M,默认 4M.
• stripe_unit:条带(stripe unit)的大小。每个 [stripe_unit] 的连续字节会被连续地保存到同一个工具中,client 写满 stripe unit 大小的数据后,接着去下一个 object 中写下一个 stripe unit 大小的数据。默认为 1,此时一个 stripe 便是一个 object。
• stripe_count:在分别写入了 [stripe_unit] 个字节到 [stripe_count] 个工具后,ceph 又重新从一个新的工具开始写下一个条带,直到该工具达到了它的最大大小。这时候,ceph 转移到下 [stripe_unit] 字节。默认为 object site。
以下图为例:
(1)Client Data会被保存在8 个 RADOS object (打算办法为 client data size 除以 2^order)。
(2)stripe_unit 为 object size 的四分之一,也便是说每个 object 包含 4 个 stripe。
(3)stripe_count 为 4,即每个 object set 包含四个 object。这样,client 以 4 为一个循环,向一个 object set 中的每个 object 依次写入 stripe,写到第 16 个 stripe 后,按照同样的办法写第二个 object set。
详细过程如下:
连续接着AbstractAioImageWrite::send_request()函数,数据按照object拆分后,又是如何写入的呢?
由于_calc_target非常主要,稍后剖析。先将_op_submit中的发送到目标osd的通信过程剖析一下。
接下来重点剖析_calc_target()函数。
第三层:OSD
主 OSD 卖力调用文件系统接口将二进制数据写入磁盘上的文件(每个 object 对应一个 file,file 的内容是一个或者多个 stripe)。
主 ODS 完成数据写入后,它利用 CRUSH 打算出第二个OSD(secondary OSD)和第三个OSD(tertiary OSD)的位置,然后向这两个 OSD 拷贝工具。都完成后,它向 ceph client 反馈该 object 保存完毕。
OSD的初始化:
OSD层写数据的大致步骤:
1)首先rados会将数据发送给主osd,主osd同样要前辈行写操作预处理,完成后它要发送写给其他的从osd,让他们对副本pg进行变动;
2)从osd通过FileJournal完成写操作到Journal中后发送见告主osd说完成,进入第4)步;
3)当主osd收到所有的从osd完成写操作的后,会通过FileJournal完成自身的写操作到Journal中。完成后会关照客户端,已经完成了写操作;
4)主osd,从osd的线程开始事情调用Filestore将Journal中的数据写入到底层文件系统。
OSD端吸收来自RADOS发送来的写:















