
因此如何在这种背景下,做到对利用方无感知的动态调度是我们所要实现的目标。本文更加看重实践而非深层次的理论讲解,有兴趣深入理解的可以自行研习。
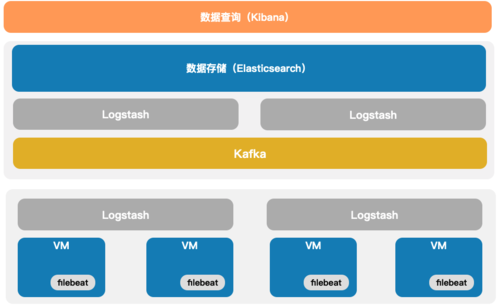
总体架构
CASE1:按日/月天生索引
创建的nginx access_log索引,开始采集2周后,数据达到25G+(number_of_replicas=1,因此总体数据超过50G),如果不进行索引拆分,该索引将越来越大,终极会严重影响查询效率,并且一旦涌现索引破坏造成的风险也更大。
通过配置logstash ouput 插件实现按照日期天生新索引:
output { elasticsearch { hosts => [\"大众192.168.0.1:9200\"大众] index => \公众php-nginx-log-%{+YYYY.MM.DD}\"大众 #按照天生成索引 }}
通过我们的配置,目前会存在2个index,分别为历史的php-nginx-log索引和以php-nginx-log.2019-01-15索引。
CASE2:Kibana查询所有数据
由于目前我们的索引不再是指定的详细索引,还是一类按照事先约定的命名格式索引凑集,这时我们想要能够在Kibana查询数据时不受影响,能够正常查询到数据,此时紧张有两种办理办法:
1、变动Kibana的Create index pattern,利用通配符关联出所有index
2、利用index aliases,详情:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/indices-templates.html
Elasticsearch的别名,就类似数据库的视图,别名不仅仅可以关联一个索引,它能聚合多个索引,下文还会提到别名的更主要的特性。
通过别名的办法是更加建议的办法。
POST /_aliases{ \"大众actions\"大众 : [ { \公众add\"大众 : { \公众index\"大众 : \"大众new_index1\"大众, \"大众alias\"大众 : \"大众alias1\"大众 } } ]}
解释:这里利用Elasticsearch的REST API进行设置,详细详情参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/docs.html ,下文中的类似代码块都是此类调用。
CASE3:通过模板创建Index
创建index后,如果未指定详细mapping,则在插入详细doc数据时,会自动天生,详细数据字段的数据类型Elasticsearch会做一定的动态识别,但是大部分都将以string定义,这种情形下我们在利用数据时 ,就会涌现一些不便,如 Kibana一些函数必须是整型类型、ip类型的字段才可以利用,其余全部默认为string类型会导致查询效率的低下和存储容量的摧残浪费蹂躏。
这时就须要我们去指定index的mapping,而很主要的一点:mapping中的filed一点指定后(无论是默认天生还是手动声明)就无法进行update filed操作,如果要修正常日只能进行create 新的index。因此我们每每会在index写入数据前就创建好index的mapping,如下:
PUT new_index1{ \公众settings\公众 : { \"大众number_of_shards\"大众 : 1 }, \公众mappings\"大众 : { \"大众_doc\"大众 : { \"大众properties\公众 : { \公众field1\"大众 : { \"大众type\"大众 : \"大众text\"大众 } } } }}
而通过CASE1中,已经解释了我们的index都是由Logstash按照日期自动创建的,因此手动通过API的办法无法知足我们的需求,这时我们就须要利用Elasticsearch的template特性:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/indices-templates.html
创建template:
PUT _template/template_nginx_log{ \公众index_patterns\公众: [\"大众php-nginx-log\"大众], \"大众settings\"大众: { \"大众number_of_shards\"大众: \"大众5\公众, \"大众number_of_replicas\"大众: \公众1\"大众 }, \"大众aliases\"大众: { \"大众php-nginx-log\公众: {} }, \公众mapping\"大众: { \公众doc\"大众: { \公众properties\"大众: { \公众@timestamp\公众: { \"大众type\"大众: \"大众date\公众 }, \"大众geoip\"大众: { \公众type\公众: \"大众object\公众 }, \"大众geoip_city_name\公众: { \"大众type\"大众: \公众text\"大众, \公众fields\"大众: { \"大众keyword\"大众: { \公众type\"大众: \"大众keyword\"大众, \"大众ignore_above\"大众: 256 } } }, \"大众geoip_continent_code\"大众: { \公众type\"大众: \公众text\"大众, \公众fields\公众: { \"大众keyword\"大众: { \"大众type\"大众: \"大众keyword\"大众, \公众ignore_above\"大众: 256 } } }, \公众geoip_country_code2\公众: { \公众type\"大众: \公众text\"大众, \"大众fields\公众: { \"大众keyword\"大众: { \公众type\"大众: \公众keyword\"大众, \"大众ignore_above\"大众: 256 } } }, \"大众user_device_os_name\"大众: { \公众type\公众: \"大众text\"大众, \"大众fields\"大众: { \"大众keyword\"大众: { \"大众type\公众: \"大众keyword\公众, \"大众ignore_above\"大众: 256 } } } } } }}
详细解释:
index_patterns:指定index匹配表达式,这个特性十分主要,如果配置为 ”php-nginx-log“,则所有以php-nginx-log为前缀的索引都将自动利用该template进行索引创建,而不须要分外指定aliases:为索引指定一个别名,同样的,通过该配置就能实现我们前面提到的问题,让按照日期创建的新index能够被精确的查询到CASE4:原index数据迁移(mapping有修正)
1)CASE3开头的时候提到过,须要按照固定的mapping创建index,来达到天生的index能利用规范的数据类型的目的,而历史index中数据想要修正mapping只能重新创建,这时我们常日利用Elasticsearch的reindex特性:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/docs-reindex.html
POST _reindex?slices=5&refresh{ \"大众source\"大众: { \公众index\公众: \"大众php-nginx-log-2019.01\"大众, \公众size\"大众: 10000 }, \"大众dest\公众: { \"大众index\"大众: \"大众php-nginx-log-2019.01.15\公众 } }
解释:
默认情形下,_reindex利用1000进行批量操作,您可以在source中调度batch_size,如上面设置为了1万Reindex支持Sliced Scroll以并行化重修索引过程。 这种并行化可以提高效率,并供应一种方便的方法将要求分解为更小的部分,如上面设置为了slices=51)slices大小的设置可以手动指定,或者设置slices设置为auto,auto的含义是:针对单索引,slices大小=分片数;针对多索引,slices=分片的最小值。2)当slices的数量即是索引中的分片数量时,查询性能最高效。slices大小大于分片数,非但不会提升效率,反而会增加开销。3)如果这个slices数字很大(例如500),建议选择一个较低的数字,由于过大的slices 会影响性能。如果要进行大量批量导入,请考虑通过设置index.number_of_replicas来禁用副本:0。紧张缘故原由在于:复制文档时,将全体文档发送到副本节点,并逐字重复索引过程。这意味着每个副本都将实行剖析,索引和潜在合并过程。相反,如果利用零副本进行索引,然后在提取完成时启用副本,则规复过程实质上是逐字节的网络传输。 这比复制索引过程更有效。2)我们要担保新旧index的数据平滑迁移对用户无感知,此时可以利用前文提到的alias,流程为:
1 . 就index利用alias,数据利用方通过alias查询数据
2 . reindex天生的新index不要创建别名,进行数据reindex操作
3 . 待数据复制完成后,调用remove+add alias接口,该操作为原子操作,可以担保数据无缝迁移,详细代码如下:https://www.elastic.co/guide/en/elasticsearch/reference/6.5/indices-aliases.html
POST /_aliases{ \"大众actions\"大众 : [ { \公众remove\"大众 : { \"大众index\"大众 : \"大众test1\"大众, \"大众alias\公众 : \"大众alias1\"大众 } }, { \"大众add\"大众 : { \"大众index\"大众 : \公众test2\"大众, \"大众alias\公众 : \"大众alias1\"大众 } } ]}总结
至此我们就总结完了一些Elasticsearch及ELK架构下常用CASE,通过合理的利用组件的特性,来知足我们的业务需求。
后面我们还将总结一些Logstash的经典CASE。
欢迎关注 高广超的简书博客 与 收藏文章 !
欢迎关注 头条号:互联网技能栈 !















