
张晨,清华大学打算机系高性能所博士生,导师为翟季冬老师,紧张研究方向为面向人工智能和量子打算的高性能异构打算系统。在OSDI、SC、ATC、ICS会议上揭橥一作论文,并得到 ICS21 最佳学生论文。曾得到 SC19, SC20, ISC21 国际超级打算机竞赛冠军。获清华大学本科生特等奖学金、国家奖学金、北京市精良毕业生、北京市精良毕业设计等名誉。
2024 年 7 月,清华大学打算机系 PACMAN 实验室发布开源深度学习编译器 MagPy,可一键编译用户利用 Python 编写的深度学习程序,实现模型的自动加速。

只管目前存在大量高性能的深度学习编译器,但是这些编译器均以打算图作为输入,须要由用户将编写的 Python 程序手动转化为打算图。为了避免这种不便性,该团队设计了 MagPy,直接面向用户编写的 Python+PyTorch 程序,自动将其转化为适用于深度学习编译器的打算图表示,从而充分发挥深度学习编译器的优化能力,避免用户利用繁芜 Python 语法带来的性能低落,为用户带来易用性和效率的双丰收。
该事情同时于系统领域主要国际会议 USENIX ATC’24 揭橥长文,第一作者清华大学博士生张晨、通讯作者为翟季冬教授。PACMAN 实验室在机器学习系统领域持续深入研究。MagPy 是继 PET、EINNET 等事情后在深度学习编译器上的又一次探索。欲理解更多干系成果可查看翟季冬教授首页:https://pacman.cs.tsinghua.edu.cn/~zjd
论文地址:https://www.usenix.org/system/files/atc24-zhang-chen.pdf项目地址:https://github.com/heheda12345/MagPy
研究背景:深度学习打算图提取技能
近年来,深度学习在生物科学、景象预报和推举系统等多个领域展示了其强大能力。为了简化编程过程,用户方向于利用 Python 编写深度学习模型,并在须要进行张量操作时调用如 PyTorch 等的张量库。此时,用户程序会在调用张量库时立即实行张量操作,如此不加优化地直接实行程序性能较差。另一方面,为了提升深度学习模型的运行速率,深度学习编译器方向于利用以算子图的格式表示的深度学习模型作为输入,在打算图上进行图级优化,如图更换和算子领悟。当可以获取到模型的打算图时,代表性的深度学习编译器 TorchInductor 和 XLA 可以在 PyTorch 的根本上均匀加速模型 1.47 倍和 1.40 倍。
详细结果如图 1 所示,标记为 Fullgraph-Inductor 和 Fullgraph-XLA。然而,实现这种加速的条件是用户手动将程序转换为打算图格式,这对许多模型开拓者来说是困难的。尤其是随着深度学习的广泛运用,越来越多的模型是由化学、生物和天文学等领域的非专业程序员开拓的。因此,急迫须要一种自动化方法将用户编写的 Python 程序转换为编译器友好的图格式来加速程序,这被称为打算图提取技能。
由于 Python 程序具有极强的动态性,加之用户程序存在行为的不愿定性,现有的打算图提取技能在处理较繁芜的用户程序时无法取得最优的性能,如图 1 中的 TorchDynamo-Inductor(利用 TorchDynamo 提取打算图,利用 TorchInductor 编译)、 LazyTensor-XLA(利用 LazyTensor 追踪打算图,利用 XLA 编译)所示。
图 1 :深度学习编译器可以显著提升模型运行效率,但现有的图提取技能阻碍了这一点。图中 Eager 表示直接实行 PyTorch 程序,Fullgraph-Inductor 与 Fullgraph-XLA 分别表示 Inductor、XLA 对模型的打算图进行编译后的加速,TorchDynamo-Inductor 与 LazyTensor-XLA 分别表示利用 TorchDynamo 和 LazyTensor 技能从用户 Python 程序中提取打算图再进行编译的性能。
MagPy 的办理方案
MagPy 的核心思想是剖析 Python 阐明器中的实行状态信息,从而让编译器能够更好的理解用户程序。Python 阐明器能够准确支持所有 Python 特性,并在运行时保留了高层次的实行状态信息,如各个变量的类型和值等等。通过有效利用阐明器供应的信息,能够更全面地理解程序的行为,从而更好地提取程序打算图。
MagPy 的设计基于以下几点不雅观察:
首先,大多数深度学习程序的动态性是有限的。只管这些程序是用 Python 编写的,具有数据类型、掌握流逻辑和运行时函数调度等潜在的动态特性,但其打算图构造在不同批次间常日保持不变。ParityBench 是一个从 Github 上自动爬取超过 100 颗星的 PyTorch 深度学习程序组成的基准测试集,它的 1421 个程序中,83% 的程序(1191 个)均知足有限动态性的性子。对付这些程序,可以通过在程序实行过程中监控张量操作,较为简便地获取其打算图。根据这个性子,MagPy 将打算图提取问题从剖析 “打算图是什么” 简化为剖析 “得到的打算图何时会发生变革”。
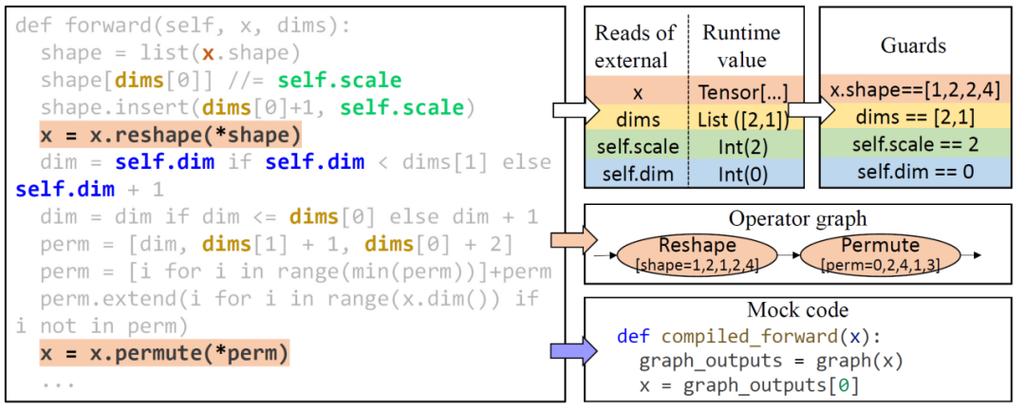
其次,只有外部值能影响程序行为。利用这一特性,可以更大略单纯地检测出会导致打算图发生变革的成分。这里的 “程序行为” 包括打算图的构造和所有程序副浸染(side effect)。只要程序从外部读取的所有值(如输入参数和全局变量)保持不变,且调用的函数的输出结果不具有随机性,程序行为就不会发生变革。因此,MagPy 只需验证所有从外部读取的值都不变,即可担保打算图构造不变。例如,只管图 2 中的程序利用了许多繁芜的 Python 特性,但只要所有从外部读取的值(如 x、dims、self.scale 和 self.dim,标记为粗体)与之前运行同等,打算图就保持不变。MagPy 会首先运行一个 “守卫函数” 对付这些值是否发生变革进行检讨(Guards),当检讨通过时,MagPy 将会运行一个 “仿照函数”(mock code),用以调用经由深度学习编译器编译的打算图及仿照程序的所有副浸染(如示例中的对 x 进行赋值)。
第三,守卫函数和仿照函数都可以通过剖析程序实行状态来确定。守卫函数的浸染是验证新一次实行的输入状态是否与之前运行匹配,仿照函数的目的是重现之前运行的终极状态。这两个部分仅基于运行时状态,而不是用户程序的逻辑。Python 阐明器在阐明实行程序的过程中,保留了所有须要的实行状态信息,因此不再须要详细剖析 Python 繁芜而动态的实行逻辑。守卫函数和仿照函数须要关注的变量包括显式读取或写入外部的值(如 self)以及被它们引用的值(如 self.dim)。因此,MagPy 设计了引用关系图来记录和剖析程序行为。
基于上述不雅观察,MagPy 提出了引用关系图(Reference Graph,简写为 RefGraph)来记录程序实行期间的程序状态。MagPy 定义了实行状态接口,用于在程序实行期间网络运行时信息,并利用基于标注的图更新规则来掩护 RefGraph。MagPy 还提出了在 RefGraph 上进行遍历天生守卫函数和仿照函数的算法。详细细节可以阅读论文。
实验
MagPy 具有极高的 Python 措辞特性覆盖率,其在对 ParityBench 中 1191 个静态的真实用户程序进行测试时,成功将 93.40% 的程序转化为完全的操作符图,大幅高于现有事情 TorchScript(35%)和 TorchDynamo(77.2%)
由于更完全的打算图导出,MagPy 在端到端测试中,也表现出具有竞争力的性能。下图展示了对付图像处理、自然措辞处理等范例深度学习模型,MagPy 取得的加速。MagPy 可取得最高 2.88 倍,均匀 1.55 倍的提升。实验在单张 A100 上进行,X-Y 表示利用图导出技能 X 和图层编译器 Y。















