
如下:
select from user where exists (select 1);

对user表的记录逐条取出,由于子条件中的select 1永久能返回记录行,那么user表的所有记录都将被加入结果集,以是与 select from user;是一样的
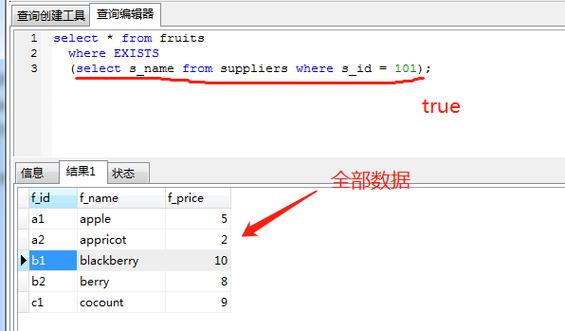
又如下
select from user where exists (select from user where userId = 0);
可以知道对user表进行loop时,检讨条件语句(select from user where userId = 0),由于userId永久不为0,以是条件语句永久返回空集,条件永久为false,那么user表的所有记录都将被丢弃
not exists与exists相反,也便是当exists条件有结果集返回时,loop到的记录将被丢弃,否则将loop到的记录加入结果集
总的来说,如果A表有n条记录,那么exists查询便是将这n条记录逐条取出,然后判断n遍exists条件
in查询相称于多个or条件的叠加,这个比较好理解,比如下面的查询
select from user where userId in (1, 2, 3);
等效于
select from user where userId = 1 or userId = 2 or userId = 3;
not in与in相反,如下
select from user where userId not in (1, 2, 3);
等效于
select from user where userId != 1 and userId != 2 and userId != 3;
总的来说,in查询便是先将子查询条件的记录全都查出来,假设结果集为B,共有m条记录,然后在将子查询条件的结果集分解成m个,再进行m次查询
值得一提的是,in查询的子条件返回结果必须只有一个字段,例如
select from user where userId in (select id from B);
而不能是
select from user where userId in (select id, age from B);
而exists就没有这个限定
下面来考虑exists和in的性能
考虑如下SQL语句
1: select from A where exists (select from B where B.id = A.id);
2: select from A where A.id in (select id from B);
查询1.可以转化以下伪代码,便于理解
for ($i = 0; $i < count(A); $i++) {
$a = get_record(A, $i); #从A表逐条获取记录
if (B.id = $a[id]) #如果子条件成立
$result[] = $a;
}
return $result;
大概便是这么个意思,实在可以看到,查询1紧张是用到了B表的索引,A表如何对查询的效率影相应当不大
假设B表的所有id为1,2,3,查询2可以转换为
select from A where A.id = 1 or A.id = 2 or A.id = 3;
这个好理解了,这里紧张是用到了A的索引,B表如何对查询影响不大
下面再看not exists 和 not in
1. select from A where not exists (select from B where B.id = A.id);
2. select from A where A.id not in (select id from B);
看查询1,还是和上面一样,用了B的索引
而对付查询2,可以转化成如下语句
select from A where A.id != 1 and A.id != 2 and A.id != 3;
可以知道not in是个范围查询,这种!=的范围查询无法利用任何索引,即是说A表的每条记录,都要在B表里遍历一次,查看B表里是否存在这条记录
故not exists比not in效率高
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一贯大家都认为exists比in语句的效率要高,这种说法实在是不准确的。这个是要区分环境的。
如果查询的两个表大小相称,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
例如:表A(小表),表B(大表)
1:
select from A where cc in (select cc from B) 效率低,用到了A表上cc列的索引;
select from A where exists(select cc from B where cc=A.cc) 效率高,用到了B表上cc列的索引。
相反的
2:
select from B where cc in (select cc from A) 效率高,用到了B表上cc列的索引;
select from B where exists(select cc from A where cc=B.cc) 效率低,用到了A表上cc列的索引。
not in 和not exists如果查询语句利用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。以是无论那个表大,用not exists都比not in要快。
in 与 =的差异
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。















