
但实际上正则表达式的浸染常见的紧张是:数据的校验,数据的查找和数据洗濯和提取,个中数据的洗濯和提取在python的爬虫中利用比较多,这些功能实在有其他实现方法
利用beautiful代替正则实现数据的洗濯和提取在python爬虫中,正则表达式每每用来提取爬取的页面中的数据。由于爬取的页面代码是由HTML标签构成的,他们每每符合一定的规律(比如链策应用a标签,以<a开头(由于a标签每每会带属性,在<a后面的内容每每有所不同),以</a>结尾),利用布局好的正则表达式可以批量地把页面中的一些我们须要的资源(他们每每是重复的且有规律的)筛选出来。举个例子,筛选html中所有标签为span,类名为title的标签,可以利用如下正则表达式<span class="title">(.?)</span>但是利用其他方法也能达成同样的效果,比如beautifulsoup4(简称bs4),便是一个用于解析HTML代码的库,利用bs4可以用一种比较随意马虎理解的办法来选中和洗濯我们须要的数据,以爬取豆瓣前250的代码为例:

import requestsfrom bs4 import BeautifulSoupurl = "https://movie.douban.com/top250"response = requests.get(url)html = response.contentsoup = BeautifulSoup(html, 'html.parser')titles = soup.select('div.hd > a > span:nth-child(1)') for title in titles: print(title.get_text()) 利用正则表达式天生工具天生数据校验正则式
对付前端开拓而言,正则表达式是避免不了的内容,前端今后端发送数据时每每要先经由前端正则查一遍,严格一点的话后端也要查一遍,不过这些须要查的数据每每有固定的正则表达式可用。这个工具可以用来测试正则表达式,也供应了一些常用的正则表达式的写法:
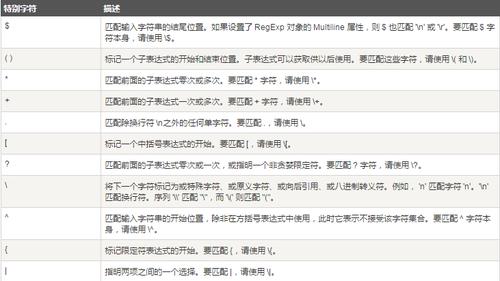
在线正则表达式测试
而这个工具可以根据正则表达式天生代码:
在线正则表达式测试
利用字符串方法实现查找要在一个字符串中查找一个子字符串不一定须要利用正则表达式,很多编程措辞都供应了字符串查找的方法。在python中,可以利用find方法来查找一个已知的字符串,利用replace方法来更换一个字符串,利用split方法来切割一个字符串。其他编程措辞中一页有类似的方法。不过并不是所有的查找都能用字符串方法办理,它只适用于已确定子字符串的情形下的利用。
小结虽然正则表达式语法比较繁芜,但是多用几次也能熟习它的语法,我们的编程并不是利用正则表达式来开拓的,利用正则表达式的韶光或许只有1%,以是并不必花费太多韶光去研究正则表达式,利用好工具也可以快速写好一个正则表达式!















