
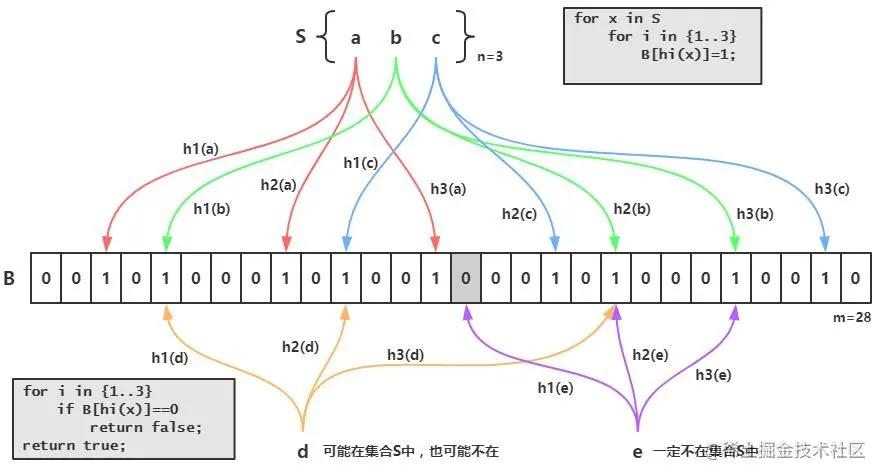
BloomFilter见告你一个元素不在,那它一定不在;但是如果BloomFilter见告你这个元素在凑集中,那你就要小心了,这个元素可能由于哈希碰撞的问题它实际上是不存在的。
在去重点场景中运用非常广泛,redis也支持这样的数据构造哦。

Bloomfilter的基本过程
添加了n个元素之后,数组上的任意一个点未当选中的概率
那么终极的误判率如下(误判率便是一个不在凑集中的元素被剖断成存在),通过上述公式我们可以打算出来,一个不存在的元素,经由k次哈希打算之后创造数组中都已经当选中,这个时候就涌现了误判,因此误判概率如下:误判率
因此当我们已经知道了大致的数据量和期望的准确率,就能打算出须要多大的BitSet(也便是数组m的大小),用来大致评估内存花费。Bloomfilter的JAVA实现package com.jx.bloomfilter;import java.util.BitSet;public class BloomFilter { private BitSet bitSet; private int size; private int numHashFunctions; public BloomFilter(int size, int numHashFunctions) { this.size = size; this.bitSet = new BitSet(size); this.numHashFunctions = numHashFunctions; } public void add(String element) { for (int i = 0; i < numHashFunctions; i++) { int hash = hash(element, i); bitSet.set(hash); } } public boolean mightContain(String element) { for (int i = 0; i < numHashFunctions; i++) { int hash = hash(element, i); if (!bitSet.get(hash)) { return false; } } return true; } // 随便设计一个哈希函数 private int hash(String element, int seed) { int hash = 0; for (char c : element.toCharArray()) { hash = 31 hash + c; } hash = hash ^ (hash >>> 20) ^ (hash >>> 12); hash = hash ^ (hash >>> 7) ^ (hash >>> 4); return Math.abs((hash + seed) % size); } public static void main(String[] args) { BloomFilter filter = new BloomFilter(1000, 3); filter.add("apple"); filter.add("banana"); filter.add("orange"); System.out.println(filter.mightContain("apple")); // true System.out.println(filter.mightContain("grape")); // false (probably) }}Python版本
须要安装bitarray:pip install bitarray
from bitarray import bitarrayimport mmh3class BloomFilter: def __init__(self, size, num_hash_functions): self.size = size self.num_hash_functions = num_hash_functions self.bit_array = bitarray(size) self.bit_array.setall(0) def add(self, element): for seed in range(self.num_hash_functions): index = mmh3.hash(element, seed) % self.size self.bit_array[index] = 1 def might_contain(self, element): for seed in range(self.num_hash_functions): index = mmh3.hash(element, seed) % self.size if not self.bit_array[index]: return False return True# 利用示例if __name__ == "__main__": bloom_filter = BloomFilter(1000, 3) # 添加元素 bloom_filter.add("apple") bloom_filter.add("banana") bloom_filter.add("orange") # 检讨元素 print(bloom_filter.might_contain("apple")) # 该当返回 True print(bloom_filter.might_contain("grape")) # 很可能返回 False















