
当今,正处于互联网高速发展的时期,每个人的生活都离不开互联网,互联网已经影响了每个人生活的方方面面。我们利用淘宝、京东进行购物,利用微信进行沟通,利用美图秀秀进行拍照美化等等。而这些每一步的操作下面,都离不开一个技能观点HTTP(Hypertext Transfer Protocol,超文本传输协议)。
举个,当我们打开京东APP的时候,首先进入的是开屏页面,然后进入首页。在开屏一样平常是广告,而首页是内容干系,包括秒杀,商品推举以及各个tag页面,而各个tag也有其对应的内容。当我们在进入开屏之前或者开屏之后(这块依赖于各个app的技能实现),会向后端做事发送一个http要求,这个要求会带上该页面广告位信息,向后端要内容,后端根据广告位的配置,挑选一个得当的广告或者推举商品返回给APP端进行展示。在这里,为了描述方便,后端当做一个大略的整体,实际上,后端会有非常繁芜的业务调度,比如获取用户画像,广告定向,获取素材,打算坐标,返回APP,APP端根据坐标信息,下载素材,然后进行渲染,从而在用户端进行展示,这统统都是秒级乃至毫秒级相应,一个高效的HTTP Client在这里就显得尤为主要,本文紧张从业务场景来剖析,如何实现一个高效的HTTP Client。

目录
1 观点
curl
libcurl
特点
2 实现
同步
代码实现(easy_curl.cc)
编译
结果
异步
http_request.h
http_request.cc
main.cc
3 性能比拟
4 一点心得
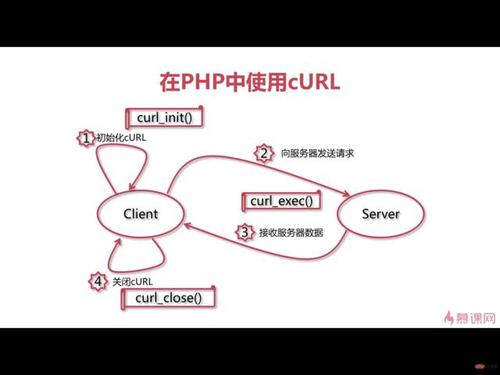
1 观点当我们须要仿照发送一个http要求的时候,每每有两种办法:1、通过浏览器2、通过curl命令进行发送要求
如果我们在大规模高并发的业务中,如果利用curl来进行http要求,厥后果以及性能是不能知足业务需求的,这就引入了其余一个观点libcurl。
curl利用URL语法在命令行办法下事情的开源文件传输工具。它支持很多协议:DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, Telnet and TFTP。支持SSL证书,HTTP POST, HTTP PUT,FTP上传,基于表单的HTTP上传,代理(proxies)、cookies、用户名/密码认证(Basic, Digest, NTLM等)、下载文件断点续传,上载文件断点续传(file transfer resume),http代理做事器管道(proxy tunneling)以及其他特性。libcurl一个免费开源的,客户端url传输库,支持DICT, FILE, FTP, FTPS, Gopher, HTTP, HTTPS, IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, Telnet and TFTP等协议。支持SSL证书,HTTP POST, HTTP PUT,FTP上传,基于表单的HTTP上传,代理(proxies)、cookies、用户名/密码认证(Basic, Digest, NTLM等)、下载文件断点续传,上载文件断点续传(file transfer resume),http代理做事器管道(proxy tunneling)等。高度可移植,可以事情在不同的平台上,支持Windows,Unix,Linux等。免费的,线程安全的,IPV6兼容的,同事它还有很多其他非常丰富的特性。libcurl已经被很多有名的大企业以及运用程序所采取。特点curl和libcurl都可以利用多种多样的协议来传输文件,包括HTTP, HTTPS, FTP, FTPS, GOPHER, LDAP, DICT, TELNET and FILE等支持SSL证书,HTTP POST, HTTP PUT,FTP上传,基于表单的HTTP上传,代理(proxies)、cookies、用户名/密码认证(Basic, Digest, NTLM等)、下载文件断点续传,上载文件断点续传(file transfer resume),http代理做事器管道(proxy tunneling)等。libcurl是一个库,常日与别的程序绑定在一起利用,如命令行工具curl便是封装了libcurl库。以是我们也可以在你自己的程序或项目中利用libcurl以得到类似CURL的强大功能。2 实现在开始实现client发送http要求之前,我们先理解两个观点:
同步要求:当客户端向做事器发送同步要求时,做事处理在要求的过程中,客户端会处于等待的状态,一贯等待做事器处理完成,客户端将做事端处理后的结果返回给调用方。
sync
异步要求:客户端把要求发送给做事器之后,不会等待做事器返回,而是去做其他事情,待做事器处理完成之后,关照客户端该事宜已经完成,客户端在获取到关照后,将做事器处理后的结果返回给调用方。
async
通过这俩观点,就能看出,异步在实现上,要比同步繁芜的多。同步,即我们大略的等待处理结果,待处理结果完成之后,再返回调用方。而对付异步,每每在实现上,须要各种回调机制,各种关照机制,即在处理完成的时候,须要知道是哪个任务完成了,从而关照客户端去处理该任务完成后剩下的逻辑。
下面,我们将从代码实现的角度,来更深一步的理解libcurl在实现同步和异步要求操作上的差异,从而更近异步的理解同步和异步的实现事理图片。
同步利用libcurl完成同步http要求,事理和代码都比较大略,紧张是分位以下几个步骤:
1、初始化easy handle
2、在该easy handle上设置干系参数,在本例中紧张有以下几个参数
CURLOPT_URL,即要求的urlCURLOPT_WRITEFUNCTION,即回调函数,将http server返回数据写入对应的地方CURLOPT_FOLLOWLOCATION,是否获取302跳转后的内容CURLOPT_POSTFIELDSIZE,这次发送的数据大小CURLOPT_POSTFIELDS,这次发送的数据内容更多的参数设置,请参考libcurl官网
3、curl_easy_perform,调用该函数发送http要求,并同步等待返回结果
4、curl_easy_cleanup,开释步骤一中申请的easy handle资源
代码实现(easy_curl.cc)#include <curl/curl.h>#include <iostream>#include <string>std::string resp;size_t WriteData( char buffer, size_t size, size_t nmemb, void userp) { resp.append(buffer, size nmemb); return size nmemb;}int main(void) { CURLcode res; CURL curl = curl_easy_init(); std::string post = "abc"; if(curl) { // 设置url curl_easy_setopt(curl, CURLOPT_URL, "https://www.baidu.com"); // 设置回调函数,即当有返回的时候,调用回调函数WriteData curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteData); // 抓取302跳转后d额内容 curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION,1); // 设置发送的内容大小 curl_easy_setopt(curl, CURLOPT_POSTFIELDSIZE, post.size()); // 设置发送的内容 curl_easy_setopt(curl, CURLOPT_POSTFIELDS, post.c_str()); // 开始实行http要求,此处是同步的,即等待http做事器相应 res = curl_easy_perform(curl); / Check for errors / if(res != CURLE_OK) fprintf(stderr, "curl_easy_perform() failed: %s\n", curl_easy_strerror(res)); / always cleanup / curl_easy_cleanup(curl); } std::cout << resp << std::endl; return 0;}
g++ --std=c++11 easy_curl.cc -I ../artifacts/include/ -L ../artifacts/lib -lcurl -o easy_curl
<!DOCTYPE html><!--STATUS OK--><html><head> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <meta http-equiv="content-type" content="text/html;charset=utf-8"> <meta content="always" name="referrer"> <script src="https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/nocache/imgdata/seErrorRec.js"></script> <title>页面不存在_百度搜索</title> <style data-for="result"> body {color: #333; background: #fff; padding: 0; margin: 0; position: relative; min-width: 700px; font-family: arial; font-size: 12px } p, form, ol, ul, li, dl, dt, dd, h3 {margin: 0; padding: 0; list-style: none } input {padding-top: 0; padding-bottom: 0; -moz-box-sizing: border-box; -webkit-box-sizing: border-box; box-sizing: border-box } img {border: none; } .logo {width: 117px; height: 38px; cursor: pointer } #wrapper {_zoom: 1 } #head {padding-left: 35px; margin-bottom: 20px; width: 900px } ...
打仗过网络编程的读者,都或多或少的理解多路复用的事理。IO多路复用在Linux下包括了三种,select、poll、epoll,抽象来看,他们功能是类似的,但详细细节各有不同:首先都会对一组文件描述符进行干系事宜的注册,然后壅塞等待某些事宜的发生或等待超时。在利用Libcurl进行异步要求,从上层构造来看,大略来说,便是对easy handle 和 multi 接口的结合利用。个中,easy handle底层也是一个socket,multi接口,其底层实现也用的是epoll,那么我们如何利用easy handle和multi接口,来实现一个高性能的异步http 要求client呢?下面我们将利用代码的形式,使得读者能够进一步理解实在现机制。multi 接口的利用是在easy 接口的根本之上,将easy handle放到一个行列步队中(multi handle),然后并发发送要求。与easy 接口比较,multi接口是一个异步的,非壅塞的传输办法。multi接口的利用,紧张有以下几个步骤:
curl_multi _init初始化一个multi handler工具初始化多个easy handler工具,利用curl_easy_setopt进行干系设置调用curl_multi _add_handle把easy handler添加到multi curl工具中添加完毕后实行curl_multi_perform方法进行并发的访问访问结束后curl_multi_remove_handle移除干系easy curl工具,先用curl_easy_cleanup打消easy handler工具,末了curl_multi_cleanup打消multi handler工具。http_request.h/该类是对easy handle的封装,紧张做一些初始化操作,设置url 、发送的内容header以及回调函数/class HttpRequest {public: using FinishCallback = std::function<int()>; HttpRequest(const std::string& url, const std::string& post_data) : url_(url), post_data_(post_data) { } int Init(const std::vector<std::string> &headers); CURL GetHandle(); const std::string& Response(); void SetFinishCallback(const FinishCallback& cb); int OnFinish(int response_ret); CURLcode Perform(); void AddMultiHandle(CURLM multi_handle); void Clear(CURLM multi_handle);private: void AppendData(char buffer, size_t size, size_t nmemb); static size_t WriteData(char buffer, size_t size, size_t nmemb, void userp); std::string url_; std::string post_data_; CURL handle_ = nullptr; struct curl_slist chunk_ = nullptr; FinishCallback cb_; int response_ret_;};
/http_request.h的实现/int HttpRequest::Init(const std::vector<std::string> &headers) { handle_ = curl_easy_init(); if (handle_ == nullptr) { return kCurlEasyInitFailed; } CURLcode ret = curl_easy_setopt(handle_, CURLOPT_URL, url_.c_str()); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_WRITEFUNCTION, &HttpRequest::WriteData); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_WRITEDATA, this); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_NOSIGNAL, 1); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_PRIVATE, this); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_POSTFIELDSIZE, post_data_.length()); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_POSTFIELDS, post_data_.c_str()); if (ret != CURLE_OK) { return ret; } ret = curl_easy_setopt(handle_, CURLOPT_TIMEOUT_MS, 100); if (ret != CURLE_OK) { return ret; }// ret = curl_easy_setopt(handle_, CURLOPT_CONNECTTIMEOUT_MS, 10); ret = curl_easy_setopt(handle_, CURLOPT_DNS_CACHE_TIMEOUT, 600); if (ret != CURLE_OK) { return ret; } chunk_ = curl_slist_append(chunk_, "Expect:"); for (auto item : headers) { chunk_ = curl_slist_append(chunk_, item.c_str()); } ret = curl_easy_setopt(handle_, CURLOPT_HTTPHEADER, chunk_); if (ret != CURLE_OK) { return ret; } // 设置http header if (boost::algorithm::starts_with(url_, "https://")) { curl_easy_setopt(handle_, CURLOPT_SSL_VERIFYPEER, false); curl_easy_setopt(handle_, CURLOPT_SSL_VERIFYHOST, false); } return kOk;}//获取easy handleCURL HttpRequest::GetHandle() { return handle_;}// 获取http server真个相应const std::string& HttpRequest::Response() { return response_;}//设置回调函数,当server返回完成之后,调用void HttpRequest::SetFinishCallback(const FinishCallback& cb) { cb_ = cb;}// libcurl 缺点码信息int HttpRequest::OnFinish(int response_ret) { response_ret_ = response_ret; if (cb_) { return cb_(); } return kRequestFinishCallbackNull;}// 实行http要求CURLcode HttpRequest::Perform() { CURLcode ret = curl_easy_perform(handle_); return ret;}// 将easy handle 加入到被监控的multi handlevoid HttpRequest::AddMultiHandle(CURLM multi_handle) { if (multi_handle != nullptr) { curl_multi_add_handle(multi_handle, handle_); }}// 开释资源void HttpRequest::Clear(CURLM multi_handle) { curl_slist_free_all(chunk_); if (multi_handle != nullptr) { curl_multi_remove_handle(multi_handle, handle_); } curl_easy_cleanup(handle_);}// 获取返回void HttpRequest::AppendData(char buffer, size_t size, size_t nmemb) { response_.append(buffer, size nmemb);}// 回调函数,获取返回内容size_t HttpRequest::WriteData( char buffer, size_t size, size_t nmemb, void userp) { HttpRequest req = static_cast<HttpRequest>(userp); req->AppendData(buffer, size, nmemb); return size nmemb;}
curl_global_init(CURL_GLOBAL_DEFAULT);auto multi_handle_ = curl_multi_init();int numfds = 0;int running_handles = 0;while (true) { //此处读者来实现,基本功能如下: // 1、获取上游的要求内容,从里面获取要发送http的干系信息 // 2、通过步骤1获取的干系信息,来创建HttpRequest工具 // 3、将该HttpRequest工具跟multi_handle_工具关联起来 curl_multi_perform(multi_handle_, &running_handles); CURLMcode mc = curl_multi_wait(multi_handle_, nullptr, 0, 200, &numfds); if (mc != CURLM_OK) { std::cerr << "RequestDispatcher::Run" << " curl_multi_wait failed, ret: " << mc; continue; } curl_multi_perform(multi_handle_, &running_handles); CURLMsg msg = nullptr; int left = 0;while ((msg = curl_multi_info_read(multi_handle_, &left))) { // msg->msg will always equals to CURLMSG_DONE. // CURLMSG_NONE and CURLMSG_LAST were not used. if (msg->msg != CURLMSG_DONE) { std::cerr << "RequestDispatcher::Run" << " curl_multi_info_read failed, msg: " << msg->msg; continue; } CURL easy_handle = msg->easy_handle; CURLcode curl_ret = msg->data.result; int response_ret = kOk; if (curl_ret != CURLE_OK) { std::cerr << "RequestDispatcher::Run" << " msg->data.result != CURLE_OK, curl_ret: " << curl_ret; response_ret = static_cast<int>(curl_ret); } int http_status_code = 0; curl_ret = curl_easy_getinfo(easy_handle, CURLINFO_RESPONSE_CODE, &http_status_code); if (curl_ret != CURLE_OK) { std::cerr << "RequestDispatcher::Run" << " curl_easy_getinfo failed, curl_ret=" << curl_ret; if (response_ret == kOk) { response_ret = static_cast<int>(curl_ret); } } if (http_status_code != 200) { std::cerr << "RequestDispatcher::Run" << " http_status_code=" << http_status_code; if (response_ret == kOk) { response_ret = http_status_code; } } HttpRequest req = nullptr; // In fact curl_easy_getinfo will // always return CURLE_OK if CURLINFO_PRIVATE was set. curl_ret = curl_easy_getinfo(easy_handle, CURLINFO_PRIVATE, &req);if (curl_ret != CURLE_OK) { std::cerr << "RequestDispatcher::Run" << " curl_easy_getinfo failed, curlf_ret=" << curl_ret; if (response_ret == kOk) { response_ret = static_cast<int>(curl_ret); } } if (req != nullptr) { ret = req->OnFinish(response_ret); } } }
至此,我们已经可以利用libcurl来实现并发发送http要求,当然这个只是一个大略异步实现功能,更多的功能,还须要读者去利用libcurl中的其他功能去实现,此处留给读者一个问题(这个问题,也是笔者项目中利用的一个功能,该项目已经线上稳定运行4年,日要求量在20E图片),业务须要,某一个要求须要并发发送给指定的几家,即该要求,须要并发发送给几个http server,在一个特定的超时时间内,获取这几个http server的返回内容,并进行处理,那么这种功能该当如何利用libcurl来实现呢?透露下,可以利用libcurl的其余一个参数CURLOPT_PRIVATE。
3 性能比拟至此,我们已经基本完成了高性能http 并发功能的设计,那么到底性能如何呢?笔者从 以下几个角度来做了测试:1、串行发送同步要求2、多线程情形下,发送同步要求(此处线程为4个,笔者测试的做事器为4C)3、利用multi接口4、利用multi接口,并复用其对应的easy handle5、利用dns cache(对easy handle设置CURLOPT_DNS_CACHE_TIMEOUT),即不用每次都进行dns解析
方法
均匀耗时(ms)
最大耗时(ms)
串行同步
21.381
30.617
多线程同步
4.331
16.751
multi接口
1.376
11.974
multi接口 连接复用
0.352
0.748
multi 接口利用dns cache
0.381
0.731
4 一点心得libcurl是一个高性能,较易用的HTTP client,在利用其直接,一定要对其接口功能进行详细的理解,否则很随意马虎入坑,犹记得在18年中的时候,上线了某一个功能,会偶现coredump(在上线之前,也进行了大量的性能测试,都没有涌现过一次coredump),为了剖析这个缘故原由,笔者将做事的代码一贯精简精简,然后仿照测试,缩小coredump定位范围,终极创造,只有在超时的时候,才会导致coredump,这就解释了为什么测试环境没有coredump,而线上会产生coredump,这是由于线上的超时时间设置的是5ms,而测试环境超时时间是20ms,这就基本把缘故原由定位到超时导致的coredump。
然后,剖析libcurl源码,发送时一个libcurl的参数设置导致coredump,至此,笔者耗费了23个小时,问题才得以办理。
更多文章,请访问
http://www.studyinfo.top















