
RAG 系统是一种创新的信息检索方法。它利用传统的信息检索方法,如向量相似性搜索,并结合最前辈的大措辞模型技能。这些技能相结合,构成了一个强大的系统,可以通过大略的提示访问大量信息。
动机
我写这篇文章的动机是我在考试测验查找旧邮件时碰着的挫败感。我常日有一些有关邮件的信息,例如联系人是谁或模糊地电子邮件的主题是什么。只管如此,在 Gmail 中进行直接单词搜索时,我必须更加详细,这使得查找我正在探求的特定邮件变得具有寻衅性。我想要一个 RAG 系统,许可我提示我的电子邮件搜索它们。因此,如果我须要一封来自大学的关于某个主题的旧电子邮件,我可以提示诸如“我在 公司 第二年注册了哪些技能课程?”之类的内容。与此提示等效的直接单词搜索具有寻衅性,由于我须要在提示中供应更详细的信息。相反,RAG 系统可以找到邮件,由于它具有所有必需的数据。

检索数据
制作 RAG 系统的第一步是找到您希望 RAG 系统利用的数据。就我而言,我想搜索电子邮件,虽然我将谈论的方法也适用于任何其他数据源。我下载了所有电子邮件,您可以在takeout.google.com上找到这些电子邮件。在那里,您可以选择仅下载邮件并按导出。这将发送一个链接到您的电子邮件,您可以从中下载所有邮件信息。如果您有其他电子邮件客户端,则可以利用类似的方法下载所有电子邮件信息。
此外,除了电子邮件之外,您还可以在本教程中利用其他数据源。一些例子是:
中等篇幅的文章在线文档,例如Langchain 文档PDF文档这些示例的共同点是它们包含文本信息。但是,您也可以将此信息运用于其他类型的信息,例如图像或音频。RAG 系统面临的寻衅不是搜索数据,由于您可以轻松地对不同形式的数据(如文本、照片和音频)进行矢量化。相反,更主要的问题将是天生文本、音频或图像,只管有一些方法可以实现。然而,本文将仅谈论从文本信息天生文本答案。
预处理数据
下载数据后,须要对其进行预处理,这是大多数机器学习流程中的主要步骤。我下载了电子邮件,因此我的预处理步骤将先容如何预处理下载的电子邮件,只管您可以对其他类型的数据运用相同的思维过程。
从 takeout.google.com 下载数据后,您的下载文件夹中将涌现一个 zip 文件夹。解压 zip 文件夹,然后找到名为All mail Include Spam and Trash.mbox 的文件,个中包含所有必要的邮件信息。将此文件移动到您正在利用的编程文件夹中,然后您可以利用StackOverflow中的以下部分代码从该文件中读出最主要的信息:
StackOverflow:https://stackoverflow.com/questions/59681461/read-a-big-mbox-file-with-python/59682472#59682472
首先,安装并导入包:
# install packages!pip install beautifulsoup4!pip install pandas!pip install tqdm# import packagesimport pandas as pdimport emailfrom email.policy import defaultfrom tqdm import tqdmfrom bs4 import BeautifulSoup #to clean the payload然后创建一个类来读取 mbox 文件:
# code for class from <https://stackoverflow.com/questions/59681461/read-a-big-mbox-file-with-python/59682472#59682472>class MboxReader: def __init__(self, filename): self.handle = open(filename, 'rb') assert self.handle.readline().startswith(b'From ') def __enter__(self): return self def __exit__(self, exc_type, exc_value, exc_traceback): self.handle.close() def __iter__(self): return iter(self.__next__()) def __next__(self): lines = [] while True: line = self.handle.readline() if line == b'' or line.startswith(b'From '): yield email.message_from_bytes(b''.join(lines), policy=default) if line == b'': break lines = [] continue lines.append(line)然后,您可以利用以下命令将邮件信息提取到 pandas 数据框:
path = r"<PATH TO MBOX FILE>/All mail Including Spam and Trash.mbox"mbox = MboxReader(path)MAX_EMAILS = 5current_mails = 0all_mail_contents = ""mail_from_arr, mail_date_arr, mail_body_arr = [],[],[]for idx,message in tqdm(enumerate(mbox)): # print(message.keys()) mail_from = f"{str(message['From'])}\\n".replace('"','').replace('\\n','').strip() mail_date = f"{str(message['Date'])}\\n".replace('"','').replace('\\n','').strip() payload = message.get_payload(decode=True) if payload: current_mails += 1 if current_mails > MAX_EMAILS: break soup = BeautifulSoup(payload, 'html.parser') body_text = soup.get_text().replace('"','').replace("\\n", "").replace("\\t", "").strip() mail_from_arr.append(mail_from) mail_date_arr.append(mail_date) mail_body_arr.append(body_text) all_mail_contents += body_text + " "解释:
<PATH TO MBOX FILE> 是前面引用的 mbox 文件的根路径MAX_EMAILS 是您要提取的电子邮件数量。请把稳,我正在提取电子邮件的正文(有效负载),所有电子邮件都不包含该正文。因此,某些电子邮件将被跳过,因此不计入您要提取的最大电子邮件数这段代码将邮件信息保存到数组和所有邮件内容的字符串中。您可以将其保存到文件中:
df = pd.DataFrame({'From':mail_from_arr, 'Date':mail_date_arr, 'Body':mail_body_arr})df.to_pickle("df_mail.pkl")# write all mail contents to txtwith open("all_mail_contents.txt", "w", encoding="utf-8") as f: f.write(all_mail_contents)您须要的所有信息现在都已存储在文件中,可供 RAG 系统检索。
其他选项
在开始履行 RAG 系统之前,我还想提一下一些不那么花哨但仍旧可靠的 RAG 替代方案。RAG是一个来自傲息检索领域的搜索系统。信息检索至关主要,由于它使我们能够访问大量可用数据。例如,信息检索技能可用于任何搜索引擎,例如谷歌。TF-IDF于1972年实现,至今仍旧是一种可靠的信息搜索算法。我自己用它实现了一个搜索引擎系统,您可以不才面的文章中看到它,您会对算法仍旧有效的效果印象深刻。
BM25是对TF-IDF的改进,只需对TF-IDF代码稍作修正即可轻松实现。我提到其他信息搜索选项(如 TF-IDF 和 BM25)的不雅观点是,完全的 RAG 系统可能并不总是必要的。如果您只须要直接访问信息,那么更大略的选择仍旧有效。
履行 RAG
现在是履行 RAG 系统的时候了。我将利用 Langchain 框架,这是一个快速设置可定制 RAG 系统的精良工具。我按照 Langchain 文档定制了自定义数据的代码来创建此部分。
首先,您必须安装并加载所有必需的包:
# install packages!pip install langchain!pip install gpt4all!pip install chromadb!pip install llama-cpp-python!pip install langchainhub# import packagesfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_community.embeddings import GPT4AllEmbeddingsfrom langchain_community.vectorstores import Chromafrom langchain_community.llms import LlamaCppfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain.docstore.document import Documentfrom langchain import hubfrom langchain_core.runnables import RunnablePassthrough, RunnablePickimport pandas as pd准备数据然后,加载您在预处理数据步骤中创建的数据集。请把稳,在本例中我仅利用邮件内容,但您也可以添加其他信息,例如发件人和每封电子邮件的数据。
# load custom datasetwith open("all_mail_contents.txt", "r", encoding="utf-8") as f: all_mail_contents = f.read()然后,您必须将字符串转换为 Langchain 可以读取的格式。下面的代码首先将所有文本转换为 Langchain 文档格式并初始化文本分割器,该分割器将字符串分割成具有重叠的不同块。这些块是必不可少的,由于当您向 RAG 系统讯问问题时,将检索最干系的块并将其供应给 LLM 作为回答问题的高下文。块之间也有一些重叠,因此每个块都可以包含足够的信息来回答给定的问题。分割成块后,每个块都会被矢量化(转换为数字)。这是一个范例的信息检索步骤,个中您要搜索的数据被矢量化。然后,当您提出问题时,该问题也会被向量化,并且您可以通过从与问题向量间隔最近的数据中获取向量来选择与问题最干系的数据。
# convert to langchain document formatdoc = Document(page_content=all_mail_contents, metadata={"source": "local"})#split uptext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)all_splits = text_splitter.split_documents([doc])vectorstore = Chroma.from_documents(documents=all_splits, embedding=GPT4AllEmbeddings())把稳:我在 Python3.8 上运行上面末了一行时碰着问题,但它可以在 Python3.11 上现成运行。该问题是由于 Python 3.8 中的 sqllite3(Python 预装包)版本引起的。
矢量化矢量化过程的事情事理如下。我在这里给出一个随机选择数字的例子。首先,对每个文档进行矢量化:
然后你将问题向量化:
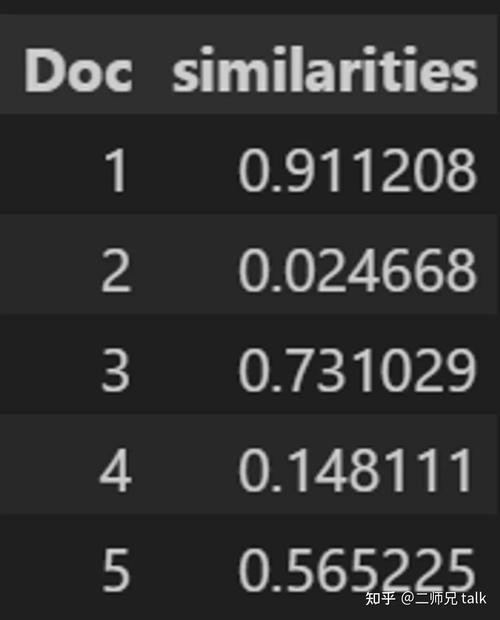
然后你找到问题和每个文档之间的相似度;例如,对付余弦相似度,这会输出 0 到 1 之间的单个数字数组,如下所示:
然后,您选择与问题最相似的文档。如果您须要两个文档,则应选择文档 1 和 3。
加载LLM准备好数据后,您必须加载大型措辞模型。措辞模型有很多选择,但我将重点关注免费模型。Langchain 是一个可以轻松利用LLM的包装器,但您仍旧须要自己下载LLM。然而,这不一定是一个繁芜的过程,我将向您展示两种方法。
第一个选项,也是我的首选,是 Llama2
您必须下载模型并将其转换为 Langchain 可以轻松利用的 .gguf 格式。然后您可以将该模型用于:
n_gpu_layers = 1 n_batch = 512 # Make sure the model path is correct for your system!llm = LlamaCpp( model_path=r"<path to model>\\ggml-model-f16_q4_1.gguf", n_gpu_layers=n_gpu_layers, n_batch=n_batch, n_ctx=1024, f16_kv=True, # MUST set to True, otherwise you will run into problem after a couple of calls verbose=True,)个中模型路径是模型的路径,n_ctx 是您要利用的高下文大小。高下文大小越大越好,但也须要更多打算,这是您必须考虑的权衡。
第二个更随意马虎访问的选项是利用 Langchain 教程中提到的 GPT4All。不管顾名思义,GPT4All 都有可供您利用的开源模型。然后,您可以下载 Tiny LLama HuggingFace(tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf模型)。如果您想要提高性能,您也可以探求更大的 Llama 模型,只管利用较小的模型仍旧可以得到不错的结果。
下载模型后,将其移至本地文件夹。然后您可以利用以下命令加载模型:
from langchain_community.llms import GPT4Allllm = GPT4All( model=r"<root path to your model>\\tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf", max_tokens=2048,)然后您就可以开始实行下面的LLM了!
利用LLM如果你想利用你的措辞模型,你可以像这样调用它:
question = "What is Medium"llm.invoke(question)我的 Llama2 模型给出的相应是:
l experience, share your expertise in a particular field, or tell a story, Medium provides a platform for you to do so.\\n2. Follow other writers: Medium has a large community of writers, and you can follow other writers whose work interests you. This way, you'll see their new publications in your feed and can discover new voices and perspectives.\\n3. Read and engage with publications: Medium publishes a wide variety of content, including articles, essays, personal stories, and more. You can read and engage with these publications by commenting, liking, or sharing them with others.您可以利用的另一个令人愉快的功能是相似性搜索。相似性搜索作为标准搜索算法,返回与您的问题最相似的数据点。这是通过向量化问题和数据点并选择与问题间隔最小的数据点来实现的。您可以利用以下方法进行相似性搜索:
#this code can be used to see if the correct documents are retrieved. The documents retrieved should be regarding your questions, and is the data the LLM uses to answer the questionsquestion = "What is Google"docs = vectorstore.similarity_search(question)这对付调试 RAG 系统是否按预期检索文档来说是一个很有代价的工具。您该当查看与您提出的问题干系的文件。
如果您有一个帮助函数来格式化文档,那就最好了:
def format_docs(docs): return "\\n\\n".join(doc.page_content for doc in docs)并形成Langchain帮助您提问。rag_prompt会向您的问题添加额外的文本,以确保 LLM 利用检索到的文档来帮助回答问题。
# retrieve relevant docsrag_prompt = hub.pull("rlm/rag-prompt")rag_prompt.messagesretriever = vectorstore.as_retriever()qa_chain = ( {"context": retriever | format_docs, "question": RunnablePassthrough()} | rag_prompt | llm | StrOutputParser())末了,您可以让LLM利用检索到的文档回答问题,个中包含以下内容:
qa_chain.invoke(question)这行代码调用您创建的链,该链检索与您的问题最干系的文档,然后根据检索到的文档提示LLM士回答您的问题。
测试
定量测试 RAG 系统可能很困难,由于创建标记数据集是劳动密集型的。因此,我将在本文中进行定性测试来检讨其性能。请把稳,上面的实现很大略,您可以期待除了高等性能之外的其他东西。
我测试了我的 RAG 系统,首先找到了一些我想要创造的电子邮件,然后查看 RAG 系统是否可以检索我须要的信息。值得把稳的是,我的许多电子邮件都将用挪威语编写,这使得 RAG 系统的某些任务变得更加困难,只管这仍旧是可能的。我不会在这里分享示例,由于我想将我的电子邮件保密,但您可以自己考试测验一下。为了进行这些测试,我网络了大约 100 封包含正文的电子邮件,并讯问了与这些电子邮件干系的问题。
测试1我收到一封来自 Digipost(挪威数字邮政做事)的电子邮件。我想看看RAG系统是否可以确定我是否收到了这样的电子邮件。
我问一个问题:
question = "Have I gotten a message from Digipost?"RAG 系统回答:
'Yes, you have received a message from Digipost.'以是,LLM通过了测试。这个测试很有趣,由于文档检索设法检索干系电子邮件,由于 Digipost 是一个不常见的词。然而,有关 Digipost 的电子邮件是挪威语的,这更令人印象深刻。
测试2我收到了一封来自 Microsoft 的有关云技能寻衅赛的电子邮件,因此我向 RAG 讯问:
question = "What is the topic of my last Microsoft email I have gotten?"它回答:
'The topic of your last Microsoft email is learning content.'正如您所看到的,RAG 再次精确,只管这次的答案很模糊并且不是最佳的。
由于我认为答案有点模糊,我考试测验让LLM的答案更详细:
question = "What is the topic of my last Microsoft email I have gotten? Answer in detail"个中回答说:
'\\nBased on the provided context, the topic of your last Microsoft email is likely related to learning paths and modules in Microsoft Learn, with a mention of trending content and contact information for feedback or help.'这样系统就可以事情了!
未来的方案
虽然系统按预期事情,但我想向这个 RAG 系统添加许多功能。以下是我正在考虑的一些未来事情:
添加有关每封电子邮件的更多信息,例如发件人和日期。这将为 RAG 系统供应更多可用信息添加一个选项,以便 RAG 可以返回特定邮件。给出这样的问题:“您能找到 6 月 23 日旁边收到的关于……的电子邮件吗?”我希望它给我一封特定的邮件(或电子邮件列表),这可能是我正在探求的邮件更好地分割数据。现在,我正在合并所有电子邮件中的文本,但相反,我可以将每封电子邮件分成一个块并以这种办法访问信息。更大的高下文窗口。增加 LLM 的高下文窗口,并许可提出后续问题,例如,如果 RAG 模型没有给出足够详细的答案。结论在本文中,我谈论了如何利用数据创建 RAG 系统。根据提示,这可以成为一个强大的搜索引擎来检索您所寻求的信息。要创建该系统,您首先要检索数据,例如从 Gmail 下载邮件。然后,您必须预处理数据以使其可供 RAG 系统访问。此后,所有数据将转换为 Langchain 格式并加载到 LLM 中。然后,您可以讯问有关您下载的数据的问题。我还包含了两个测试,显示 RAG 系统如何相应查询并展示系统是否按预期事情。
资源:
Gihub:https://github.com/mcks2000/llm_notebooks/tree/main/search_mail_dataStackOverflow:https://stackoverflow.com/questions/59681461/read-a-big-mbox-file-with-python/59682472#59682472Langchain:https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa点赞关注 二师兄 talk 获取更多资讯,并在 头条 上阅读我的短篇技能文章















