
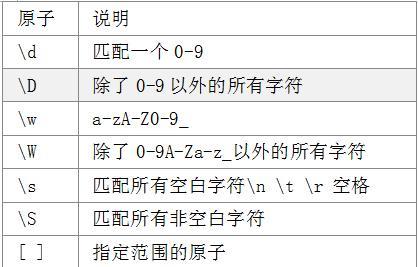
eg. 利用[a-d]表示a~d之间的字母,而不是利用(a|b|c|d)
function regTest($pattern,$str,$cnt){

$start=microtime(true);
for ($i=0;$i<$cnt;$i++){
preg_match($pattern,$str);
}
echo 'waste time(s): ',number_format(microtime(true)-$start, 10),'<br>';
}
$cnt=15;//最好设大数,eg.1000
$str='';
for ($i=0;$i<$cnt;$i++){
$str.='abababcdefg';
}
//方案1:分支条件
regTest(\公众/^(a|b|c|d|e|f|g)+$/\"大众,$str,$cnt);
//方案2:字符组
regTest(\公众/^[a-g]+$/\"大众,$str,$cnt);
//方案3:同方案2
regTest(\"大众/^[abcdefg]+$/\"大众,$str,$cnt);
123456789101112131415161718可以看出利用字符组比利用分支条件速率快很多。这是由于在匹配单个字符的时候,引擎会把[abc]这样的字符组视为一个元素,而不是3个元素(a、b、c)。全体元素作为匹配迭代的一个单元,不须要进行三次迭代,从而提高匹配效率。
二、优化选择最左真个匹配结果
对付传统NFA引擎来说,由于引擎一旦找到匹配结果就会停下来,而不会去考试测验正则表达式的每一种可能(PHP中的preg函数就属于传统型NFA引擎)。
三、标准量词是匹配优先的
若用量词约束某个表达式,那么在匹配成功前,进行的考试测验次数有下限和上限。eg.
preg_match('/\w(\d+)/','copy2003y',$match);
1这条正则表达式匹配的$1结果该当是3。阐明如下:当正则引擎用“\w(\d+)”匹配字符串copy2003y时,会先用“\w”匹配字符串copy2003y。而“\w”会匹配字符串copy2003y的所有字符,然后再交给“\d+”匹配剩下的字符串,而剩下的没有了。这时,“\w”规则会不宁愿地吐出一个字符,给“\d+”匹配。同时,在吐出字符之前,记录一个点,这个点便是用于回溯的点。然后“\d+”匹配y,创造不能匹配成功,此时会哀求“\w”再吐出一个字符;“\w”先记录一个回溯的点,再吐出一个字符。这时,“\w”匹配结果只有copy200,已经吐出3y。“\d+”再去匹配3,创造匹配成功,会关照引擎,并且直接显示出来。以是,“(\d+)”的结果是3,而不是2003。
如果改为非贪婪模式呢?“\w?(\d+)”匹配的结果就该当是2003。由于“\w?”是非贪婪,正则引擎会用表达式“\w?”每次仅匹配一个字符串,然后再将掌握权交给后面的“(\d+)”匹配下一个字符,同时记录一个点,用于匹配不堪利时,返回这里再次匹配。
只管即便以组为单位进行匹配,利用固话分组就能避免无休止的匹配。
四、谨慎用点号元字符,尽可能不用星号和加号这样的任意量词
只要能确定范围(eg.“\w”),就不要用点号;只要能够预测重复次数,就不要用量词。假设一条微博的XML正文部分构造如下:
<span class=\"大众msg\"大众>...</span>
1正文中无尖括号,写法如下:
<span class=\"大众msg\"大众>[^<]{1,200}</span>
1或者:
<span class=\"大众msg\"大众>.</span>
1上述第一种代码的思路要好于第二种,缘故原由如下:
1、利用“[^<]”,担保了文本的范围不会超过下一个小于号所在位置
2、明确长度范围{1,200},依据是一条微博大致的字符长度范围是固定的,现在微博字数长度限定是140个字。
同时,能利用
五、只管即便利用字符串函数处理代替
利用字符串函数和正则表达式都可以处理字符串,两者比较,字符串函数处理的效率更高。当然,有些情形险些是非正则表达式不能胜任的,或者不用正则表达式的本钱太高,这些情形不得不用正则表达式。
六、合理利用括号
每利用一个普通括号(),而不是非捕获型括号(?:),就会保留一部分内存等着再次访问。
七、起始、行描点优化
能确定起止位置,利用^能提高匹配的速率。同理,利用$标记结尾,正则引擎则会从符合条件的长度处开始匹配,略过目标字符串中许多可能的字符。在写正则表达式时,该当将描点独立出来,例如“^(?:abc|123)”比“^123|^abc”效率高,而“^(abc)”比“(^abc)”效率更高。
这个原则不适用于所有正则引擎。比如在PCRE中,二者效率相称。
八、量词等价转换的效率差异
例如在PHP中,利用“\d\d\d”和“\d{3}”,或者“====”和“={4}”,它们之间的效率险些没有差别。但是利用其他措辞可能就会有比较明显的性能差异了。
九、对大而全的表达式进行拆分
十、利用正则以外的办理方案
eg.
1、 同五;
2、在某项目须要剖析PHP代码,分离出对应的函数调用(以及源代码对应的位置)。虽然这些正则表达式也可以实现,但无论从效率还是代码繁芜度方面考虑,这都不是最有方法。PHP已经内置解析器的接口PHP Tokenizer。利用PHP Tokenizer能大略、高效、准确地剖析出PHP源代码的组成;
3、在解析URL时没必要利用正则表达式,利用parse_url函数即可;
4、在获取HTTP头时,也可以利用get_headers函数;
5、在进行输入校验时,可以利用filter_var函数,如:
filter_var($email,FILTER_VALIDATE_EMAIL);
16、如果在JavaScript里,可以利用DOM代替一些正则匹配。















