
本文作者 Mathew Duggan 是 Git 长达十年的虔诚用户,他一边吐槽 Git 存在许多不敷,不断试用新产品探求替代方案,一边却无奈地创造自己仍在利用。Git 为什么难以替代?让我们跟随作者,在不同的版本掌握系统(VCS,version control system)的利害比拟中探求答案吧~
我全职利用 Git 将近十年了。我每天都在利用它,紧张依赖命令行版本。(针对Git利用,)我读过书、听过讲座、练习实践过,总之,我用 Git 有效地完成了事情。为了保持良好的事情状态,我还在新的软件仓库中安装了一些定制的 Git 钩子。

仅从曝光效应(译者注:Exposure Effect,人们偏好自己熟习的事物,只要某件事常常涌现,就能增加人们的喜好程度)的角度来说,我该当喜好这个利用十年的工具,但我并不喜好。
我不总是能“掌握”Git 的事情,有时命令会导存问想不到的操作,这些操作与 Git 的事情办法同等,但与我偏好的事情办法不符。相反,我须要在脑筋里设想很多东西,才能让它完成我想要的事情。
“好吧,我想把未暂存的编辑内容移到一个新的分支。如果该分支不存在,我想利用 checkout,但如果它存在,我就须要 stash、checkout,然后再 stash pop。”“如果现在问题是,我在缺点的分支上做了修正,我须要stash apply 而不是 stash pop。”我须要引入一些跨版本的依赖关系,利用submodules还是subtree?
在事情中,我须要深刻理解reset、revert、checkout、clone、pull、fetch、cherrypick之间的差异,只管这些词在英语中的含义相同。
你须要记住,push和pull并不像它们的名字含义那样对立。说到merge,你须要考虑清楚什么情形下须要比较rebase、merge、merge --squash的逻辑。Merge的方向是什么?糟糕,我欠妥心删除了一个文件。我得记住 Git rev-list -n 1 HEAD - filename。Git reset --hard HEAD~1 可以纠正我的缺点,我也得记住利用 --hard 时的详细浸染,并确保通报的flag是精确的。
要记住这些操作,却没有人认为这不可能,而且很明显,Git 对全天下数百万人都大有用处。但我们能不能老实地承认,以上操为难刁难我险些每次事情都要用到的流程(如下所示)来说,实在是大材小用了:
创建分支将分支推送到远程在分支上开展事情,然后提交拉取要求合并 PR,常日是压扁后合并,由于这样更随意马虎阅读让 CI/CD 做它该做的事
我从未通过电子邮件发送过补丁,也从未从本地副本中还原过 repo。我不会花几周韶光离线事情,只为考试测验合并一个巨大的分支。我们不会让版本库的容量超过 1-2 GB,由于这样一来,我须要修正三个文件并提交一份报告,同时它们会变得难以处理。范例的事情流程都无法从 Git 的繁芜性中获益。
更详细地说,Git 不能离线事情。它依赖于合并掌握,而这种掌握乃至不是 Git 和拉取要求的一部分。当我合并提交(squash)时,大部分的分布式历史记录都会被丢弃。我确当地磁盘上堆满了过期的版本,以至于我不得不在开始事情提高行更新,但这种操为难刁难我只是摧残浪费蹂躏韶光。
现在有人提出“我不喜好 Git 的事情办法”,这有点像重新鲜的角度抱怨 PHP。让我来阐述一下我心目中的完美 VCS(version control system,版本掌握系统),并磋商市情上的VCS能否知足这些需求。
Gitlite
要取代 Git,我认为 VCS 须要增加(或减少)一些功能,知足日常 95% 的利用需求。
抛弃分散模式。我以及所有 Git 用户利用大量的软件仓库,无论如何,我都须要常常访问做事器才能完成事情。去中央化的繁芜性并不划算,我甘心做完下一部分就丢弃它。如果 GitHub 本日宕机了,无论如何也无法支配,那还不如把做事器哀求当成一种额外福利。
将大量事情转移到做事器端,按需进行。如果我须要在一个版本库中搜索某个内容,与其从版本库中复制所有内容,在本地搜索到可能已经由时的信息,不如在做事器上运行搜索,按需获取我想的文件,而不是复制所有文件。我须要大版本库,但不想把所有文件都拷贝到磁盘上。只在须要的时候供应给我对应文件,然后将剩下文件留存。为什么我只要用 3 个文件,却要一直下载数百个文件?拉取要求是第一类公民(译者注:First-class Citizen,支持其他实体所有操作的实体)。我们理解“分支”的观点,也秉持“分支在合并前必须通过检讨”的理念。我提倡将其变成 CLI 流程的一部分。如果能在同一个工具中哀求做事器“空运行(dry-run)”一个 PR 检讨,查看我的分支是否通过,那该有多好?想象一下,在不同的 Kubernetes 托管做事供应商中利用 gh CLI 的功能,而不使其针对特定平台,就像利用 kubectl 一样。认可并简化跨版本依赖的理念。子模块(submodules)的事情办法并不尽如人意,子树(subtree)轻微好点,但将事情推回上游依赖关系会让人产生困惑与误解。相反,我想要的是:https://Gitmodules.com/如果我从远程做事器拉取内容,我的做事器会与远程做事器保持同步,但我也可以选择将版本固定在我的版本库中。如果我有权限,我在版本库中的变动会转到远程依赖库中。如果涌现冲突,则通过 PR 来办理。内置更好的可视化工具。用户可通过浏览器或其他工具,更直不雅观地理解他们正在查看的内容。很多人在利用 Git 时都会利用 CLI + 图形用户界面临象来实现这个功能,我们可以把这个操作合并至一个步骤。更易于集中管理提交信息和规则。没错,我可以利用一堆 Git 钩子,但如果能够在克隆 repo 时就被全面检讨就更好了,由此可以确保自己的做法精确,以免被 CI 插件或提交信息格式检讨器创造缺点,摧残浪费蹂躏大量韶光。我还希望能有一些提示,例如“嘿,这个分支越来越大了”或“每个提交都必须是 fix/feat/docs/style/test/ci”等。Read replica观点。我很希望能将我的 CI/CD 系统指向一个只读副本集(Read replica box),并为实际用户保留我的主 VCS box。主理事器触发一个 webhook,该 webhook 会触发一个带有标签(tag)的项目构建(build),然后点击只读副本,如果只读副本没有该标签,它就会从主理事器中提取。最好能建立某种主/副模型,可以在配置中同时设置主理事器和副做事器,纵然主理事器(云供应商)宕机,也能连续将内容推送到有备份的地方。因此,我考试测验了一些竞品,看看“有没有系统能在这些部分(比Git)设计得更好”。
2024 年的 SVN
我第一次打仗版本掌握是 SVN(Subversion),当时的说法是“在事情满一年之前不要考试测验创建分支”。不过,作为一名新手,SVN 的事情非常大略,由于它功能并不多。Add、delete、copy、move、mkdir、status、diff、update、commit、log、revert、update -r、co -r 险些便是你所须要的所有命令。Subversion 有一个非常大略的事情事理模型,即“我们把东西复制到文件做事器上,然后在你哀求时再传回你的条记本电脑”,这也有助于新用户入门。
但不得不说,SVN 比我过往影象中的体验要好得多。产品存在的“粗糙边缘”彷佛都被打磨掉了,我没有再碰着之前的问题,为 Subversion 团队的出色事情点个大大的赞。
Subversion 根本知识
实际上,Subversion 客户真个基本功能是将所有文件作为单个原子事务提交到中心做事器。无论何时,它都会为全体项目创建一个新版本,称为修订版。这不是哈希值,只是一个从零开始的数字,以是新用户不会稠浊“新版本”和“旧版本”。这些数字是全局数字(global number),与文件无关,因此是world的状态。每个文件都有 4 种状态:
本地未修正 + 当前远程:保持不变本地已变动 + 当前远程:要发布变动,您须要将其提交,更新将不起任何浸染本地未修正 + 远程已过期:SVN update 会将最新副本合并到事情副本中本地已变动 + 远程已过期:SVN commit 将不起浸染,SVN update 会考试测验办理问题,但如果无法办理,用户就要自行办理。
要“毁坏”SVN险些是不可能的,由于向上推送并不虞味着向下拉取。这意味着不同的文件和目录可以设置为不同的版本,但只有运行 SVN update 时,全体world才会自动更新到最新版本。
利用 SVN 的事情流程如下:
确保已联网运行 SVN update,将事情副本升级到最新版本进行所需的修正,牢记不要利用操作系统工具来移动或删除文件,而应利用 SVN copy 和 SVN move,这样它就会知道这些变动运行 SVN diff,确保你已经做了想做的任务再次运行 SVN update,用 SVN resolve 办理冲突觉得不错?点击 SVN commit 就大功告成了
那为什么 SVN 会被抛弃呢?一个缘故原由:分支(branches)。
SVN 分支
在 SVN 中,分支实在便是把一个目录粘贴到正在事情的地方。常日情形下,你会把它作为一个远程拷贝,然后开始事情,以是看起来更像是把 URL 路径复制到一个新的 URL 路径。但对用户来说,它们看起来就像你创建的版本库中的普通目录。在 SVN 1.4 之前,合并一个分支最少需得要交给硕士学历的员工,但他们增加了一个 SVN merge,简化了合并。
实际上,你可以利用 SVN merge 来与主分支保持同步,然后当你准备就绪时,运行 SVN merge --reintegrate 来将分支推送到主分支。然后,你就可以删除该分支,但如果须要读取日志,该分支的 URL 将始终有效。这一特性在票据系统特殊有效,由于在票据系统中,URL 只是票据编号。不过,你也没必要永久用随机目录把事情搞得一团糟。
总之,SVN 分支以前的很多问题现在都不存在了。
那么,SVN还存在什么问题?
涉及到自动化功能,SVN 在我看来是失落败的,用户只能亲自动手。虽然你可以对 repo 的不同部分进行细致入微的访问掌握,但在实践中并不常见。如果没有某种额外的掌握或检讨,你就无法阻挡他人合并分支。纵然你增加了项目职员,也不太会有人更新这一功能,SVN 做事器依旧包袱沉重。
此外,用户界面已经由时,全体工具生态系统也由于用户的离开而开始腐蚀。我不知道现在还能否成功推举别人从 Git 转向利用 SVN,但我确实认为SVN有很多好的想法,能更靠近我想要的事情办法。SVN只是在网络方面须要大量的 UI/UX 投入,才能让我喜好用它而不是 Git。但我认为,如果有人对这项事情感兴趣,Subversion 的基本架构还是不错的。
Sapling
与我共事过的每一位前 Meta 工程师都见告我,他们非常怀念自己的 VCS。Sapling 便是这样一个团队,它让我们能在一个更以 GitHub 为中央的天下里玩转功能。几个月来,我一贯在利用它Sapling来处理我的事情。我真的爱上了Sapling,它是为了易于理解而设计的,利用起来令民气境愉快。
Sapling和Git很多东西都是一样的。用 sl clone 克隆,用 sl status 检讨状态,用 sl commit 提交。最明显的不同之处在于堆栈的观点和 smartlog 的观点。堆栈是“提交的凑集”,这一观点的含义是,可以通过命令行利用 sl pr submit 为这些变更发布 PR,每个 GitHub PR 都是个中一个提交。这种视图(显然)既凌乱又恼人,以是还有另一种工具可以帮助你精确查看变更,那便是 ReviewStack。
除非我向你展示我在说什么,否则这统统都毫无意义。我新建了一个 repo,并向个中添加文件。首先,我检讨状态:
❯ sl st? Dockerfile? all_functions.py? get-roles.sh? gunicorn.sh? main.py? requirements.in? requirements.txt
然后添加文件:
sl add .adding Dockerfileadding all_functions.pyadding get-roles.shadding gunicorn.shadding main.pyadding requirements.inadding requirements.txt
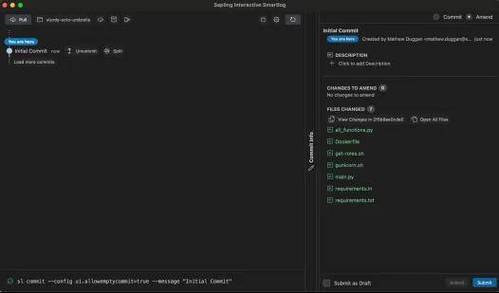
如果我想在本地运行一个更俊秀的网页用户界面,我会运行 sl web 并得到这个界面:
以是我把所有这些文件都添加到了初始提交中,很好,让我们连续添加:
❯ sl@ 5a23c603a 4 seconds ago mathew.duggan│ feat: adding the exceptions handler│o 2652cf416 17 seconds ago mathew.duggan│ feat: adding auth│o 2f5b8ee0c 9 minutes ago mathew.duggan Initial Commit
现在,如果我想浏览这个堆栈,只需利用 sl prev 即可高下移动堆栈:
sl prev 10 files updated, 0 files merged, 1 files removed, 0 files unresolved[2f5b8e] Initial Commit
这也表示在我的 sl 输出中:
❯ slo 5a23c603a 108 seconds ago mathew.duggan│ feat: adding the exceptions handler│o 2652cf416 2 minutes ago mathew.duggan│ feat: adding auth│@ 2f5b8ee0c 11 minutes ago mathew.duggan Initial Commit
这也显示在我确当地网络用户界面上:
末了,流程以创建拉取要求的 sl pr 结束。它们是 GitHub 的拉取要求,但它们看起来与普通的 GitHub 拉取要求不同,你也不会以相同的办法,而是利用ReviewStack进行审查。
我为什么喜好它?
Sapling符合我对 VCS 的期望,它更随意马虎察觉到正在进行的事情,其设计旨在方便大型团队互助,同时以更合理的办法供应所需信息。命令对我来说更故意义,所有操作都能完成。
更详细地说,我喜好它抛弃分支的观点。我所拥有的是一系列从开拓主线分叉出来的提交,但我并没有想要命名的明确内容,以是我哀求添加这些提交。我想要的是在主线上添加一堆提交,然后由专人查看这些提交凑集,确保其合理性,并对其进行自动检讨。以是“分支”观点对我毫无用途,末了被我删除了。
我还喜好Sapling易于撤销事情的特性,对我来说,uncommit、unamend、unhide 和 undo更加好用,而且险些总能达到预期效果。取消暂存区域,将重点放在易于利用的命令上,这样的设计更符合逻辑。
为什么不应该切换?
既然我这么喜好Sapling,那还有什么问题呢?为了让Sapling达到我真正想要的效果,我须要运行更多的 Meta干系组件(译者注:Sapling 是 Meta 开拓和利用的源代码掌握系统)。Sapling在 GitHub 上运行得很好,但我最想得到的是:
Mononoke:Sapling的做事器端组件
https://Github.com/facebook/sapling/blob/main/eden/mononoke/README.md
EdenFS
https://Github.com/facebook/sapling/blob/main/eden/fs/docs/Overview.md
以上组件基本席卷了Sapling的所有优点,如下所述:
按需获取历史文件(remotefilelog,2013)文件系统监控器,以更快地节制事情副本状态(watchman,2014)回存稀疏配置文件以缩小事情副本(2015)限定引用交流(选择性拉取,2016)按需获取历史树(2017)增量更新事情副本状态(treestate,2017)用于推送吞吐量和更快索引的新做事器根本举动步伐(Mononoke,2017)虚拟化事情副本,可按需获取当前已签出的文件或树(EdenFS,2018)更快的提交图算法(分段更新日志,2020)按需获取提交(2021)
我很想考试测验将所有这些优点结合在一起(由于个中很多都有源代码,我正在努力考试测验启动),但到目前为止,我还无法复现完全的Sapling体验。以上所有特点都吸引着人选择过渡到 Sapling,但如果没有这些特点,我就真的要在 GitHub 上添加很多自定义事情流了。我想我可以把 GitHub 整体迁移到其他地方,但 Meta 须要以一种更易于利用的办法发布更多这些组件。
Scalar
Sapling 是 GitHub 个中一个很好的技能栈,但(实际上)我不会将一个团队迁移到 Sapling 上,除非 Facebook(现Meta) 决定从头到尾发布全体软件包。我能让 Git 按照我想要的办法事情吗?或者至少让管理所有文件不那么麻烦?
微软有一款工具可以做到这一点,那便是 VFS for Git,但它只适用于 Windows,以是对我来说毫无用途。不过他们也供应了一款名为 Scalar 的跨平台工具,旨在“实现大规模的大型仓库管理”。它最初是微软的一项技能,终极被转移到了 Git 身上,大概它能实现我想要的功能。
Scalar的浸染是,有效设置所有最当代的 Git 选项,以便在大型仓库中利用。以上内容包括,内置的文件系统监视器、多包索引、提交图、操持后台掩护、部分克隆和克隆模式稀疏检出。
以上这些都是什么?
文件系统监视器是 FSMonitor,它是一个从操作系统跟踪文件和目录变革并将其加入行列步队的守护进程。这就意味着 Git status 不须要查询 repo 中的每个文件就能创造改动。
把带有 pack 文件的 Git pack 目录拆分成多个。文档中的提交图:“commit-graph 文件存储了提交图构造以及一些额外的元数据,以加快图的走行速率。通过按词典顺序列出提交 OID,我们可以为每个提交确定一个整数位置,并利用这些整数位置来引用提交的父节点。我们利用二进制搜索查找初始提交,然后在过程中利用整数位置进行快速查找。”末了是克隆模式 sparse-checkout。这许可儿们将事情目录限定为特定文件这个工具的目的是创建一种处理大型单核项目的简便模式,着眼于实际上是微做事凑集的单核项目。好吧,但它能知足我的需求吗?
我为什么喜好它?
Scalar已经内置在 Git 中,这很好,便于用户上手并利用。此外,它还能实现我想要的功能,把一堆现有的 repo 合并成一个巨大的 monorepo,性能出奇地好。稀疏签出意味着我可以指定哪些是须要的,哪些是不须要的,还办理了“如果我有一个巨大的二进制文件目录,但我不想让别人担心怎么办”的问题,由于它采取了与 .Gitignore 相同的模式匹配。
但Scalar并不能从根本上改变 Git 的实质。利用这些默认设置,你可以把仓库扩大很多,但它仍旧须要在本地处理很多事情,而且须要人工处理。不过我想说,Scalar让我少了很多抱怨。结合用于 PR 的 gh CLI 工具,我能够拼凑出一个相称满意的事情流程。
因此,虽然这肯定是我往后要采取的模式(充满微做事的 monorepo,我能够用标量来管理规模),但我认为它代表了你能在多大程度上修正 Git 作为现有平台。这是目前最好的选择,虽然已经很靠近我的目标,但仍无法达到。
你可以亲自试试:Git-scm.com/docs/scalar
结论
以是我们该当怎么选择VCS?诚笃说,我可以就这个问题再写上 5000 字。在这一领域,我们总觉得自己离破解这个秘密越来越近,然后又放弃了,由于我们找到的办理方案基本上已经足够好了。随着事情流程的不断发展,我们再也没有回过分来触碰运用程序设计的“第三条轨道”(新方案)。
为什么呢?我认为,人们之以是对 Git 不满意,是由于他们不理解它。这种状况让人觉得,如果你不喜好这个工具,那么问题就出在你身上,而不是工具。我还认为,程序员之以是喜好分散式设计,是由于它(在某种程度上)鼓励了对可移植性的虚假希望。是的,我完备依赖于 GitHub 的操作(包括Pull Requests、GitHub 访问掌握、SSO、secrets 和releases),但在存亡关头,我可以将实际的 repo 本身转移到另一个供应商那里。
我非常希望有人能再次动手办理这个问题。我以为我们的事情还没有完成,而且从对所有这些问题的研究来看,彷佛有很多低垂的优化果实可供任何人摘取。我认为紧张的障碍是你须要离开 Git,迁移到一个完备不同的构造,这对我们来说可能太难了。不过,我始终期待这个问题能够被办理。
作者丨Mathew Duggan 编译丨onehunnit
来源丨matduggan.com/why-dont-i-like-git-more/
dbaplus社群欢迎广大技能职员投稿,投稿邮箱:editor@dbaplus.cn















