
然后履行更好的掌握和管理,同时利用多台机器的CPU、内存、存储,供应更好的性能。而分治有两种实现办法:垂直拆分和水平拆分。
2 垂直拆分(Scale Up 纵向扩展)垂直拆分分为垂直分库和垂直分表,紧张按功能模块拆分,以办理各个库或者各个表之间的资源竞争。比如分为订单库、商品库、用户库...这种办法,多个数据库之间的表构造是不同的。

先说说垂直分库。垂直分库实在是一种大略逻辑分割。比如我们的数据库中有商品表Products、还有对订单表Orders,还有积分表Scores。接下来我们就可以创建三个数据库,一个数据库存放商品,一个数据库存放订单,一个数据库存放积分。
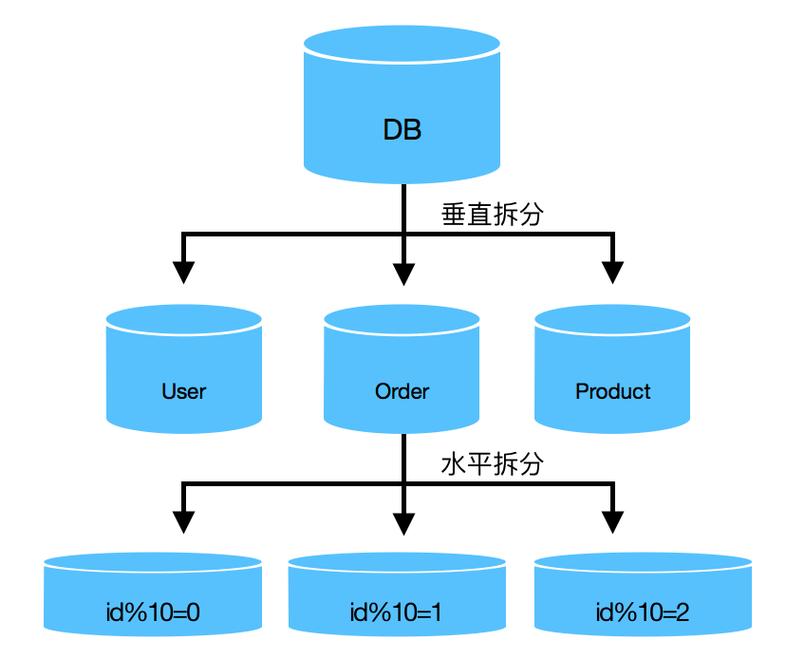
垂直分库有一个优点,他能够根据业务场景进行孵化,比如某一单一场景只用到某2-3张表,基本上运用和数据库可以拆分出来做成相应的做事。拆分办法如下图所示:
2.2 垂直分表
再来说说垂直分表,比较适用于那种字段比较多的表,假设我们一张表有100个字段,我们剖析了一下当前业务实行的SQL语句,有20个字段是常常利用的,而其余80个字段利用比较少。
这样我们就可以把20个字段放在主表里面,我们再创建一个赞助表,存放其余80个字段。当然主表和赞助表都是有主键的,他们通过主键进行关联合并,就可以组合成100个字段的表。拆分办法如下图所示。
除了这种访问频率的冷热拆分之外,还可以按照字段类型构造来拆分,比如大文本字段单独放在一个表中,与根本字段隔离,提高根本字段的访问效率。
也可以将字段按照功能用场来拆分,比如采购的物料表可以按照基本属性、发卖属性、采购属性、生产制造属性、财务司帐属性等用场垂直拆分。
总体来说:垂直拆分有以下优点:
跟随业务进行分割,类似微做事的分管理念,方便解耦之后的管理及扩展。高并发的场景下,垂直拆分利用多台做事器的CPU、I/O、内存能提升性能,同时对单机数据库连接数、一些资源限定也得到了提升,能实现冷热数据的分离。垂直拆分的缺陷:
部分业务表无法join,运用层须要很大的改造,只能通过聚合的办法来实现。增加了开拓的难度。单表数据量膨胀的问题依然没有得到有效的办理。分布式事务也是一个难题。3 水平拆分(Scale Out 横向扩展)水平拆分又分为库内分表和分库分表,来办理单表中数据量增长涌现的压力,这些数据库中的表构造完备相同。
3.1 库内分表先说说库内分表。假设当我们的Orders表达到了5000万行记录的时候,非常影响数据库的读写效率,怎么办呢?
我们可以考虑按照订单编号的order_id进行rang分区,便是把订单编号在1-1000万的放在order1表中,将编号在1000万-2000万的放在order2中,以此类推,每个表中存放1000万数据。
关于水平分表的机遇,业内的标准不是很统一,阿里的Java 开拓手册的标准是当单表行数超过 500万行或者单表容量超过 2 GB时,才推举进行分库分表。百度的则是1000 W行的进行分表,这个是百度的DBA经由测试推算出的结果。
但是这边忽略了单表的字段数和字段类型,如果字段数很多,超过50列,对性能影响也是不小的,我们曾经有个业务,表字段是随着业务的增长而自动扩增的,到了后期,字段越来越多,查询性能也越来越慢。
以是个人以为不必拘泥于500W 还是1000W,开拓职员在利用过程中,如果压测创造由于数据基数变大而导致实行效率慢下来,就可以开始考虑分表了。
3.2 库内分表的实现策略目前在MySql中支持四种表分区的办法,分别为HASH、RANGE、LIST及KEY,当然在其它的类型数据库中,分区的实现办法略有不同,但是分区的思想事理是相同,详细如下:
3.2.1 HASH(哈希)HASH分区紧张用来确保数据在预先确定数目的分区中均匀分布,而在RANGE和LIST分区中,必须明确指定一个给定的列值或列值凑集该当保存在哪个分区中,而在HASH分区中,MySQL自动完成这些事情,
你所要做的只是基于将要被哈希的列值指定一个列值或表达式,以及指定被分区的表将要被分割成的分区数量。 示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL,10 `gravalue` varchar(20) DEFAULT NULL,11 `createtime` DateTime NOT NULL12 ) ENGINE=InnoDB DEFAULT CHARSET=utf813 PARTITION BY HASH(YEAR(createtime))14 PARTITIONS 10;
上面的例子,利用HASH函数对createtime日期进行HASH运算,并根据这个日期来分区数据,这里共分为10个分区。
建表语句上添加一个“PARTITION BY HASH (expr)”子句,个中“expr”是一个返回整数的表达式,它可以是字段类型为MySQL 整型的一列的名字,也可以是返回非负数的表达式。
其余,可能须要在后面再添加一个“PARTITIONS num”子句,个中num 是一个非负的整数,它表示表将要被分割身分区的数量。
3.2.2 RANGE(范围)基于属于一个给定连续区间的列值,把多行分配给同一个分区,这些区间要连续且不能相互重叠,利用VALUES LESS THAN操作符来进行定义。示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL,10 `gravalue` varchar(20) DEFAULT NULL,11 `createtime` DateTime NOT NULL12 ) ENGINE=InnoDB DEFAULT CHARSET=utf813 PARTITION BY RANGE(gwcode) (14 PARTITION P0 VALUES LESS THAN(101) ,15 PARTITION P1 VALUES LESS THAN(201) ,16 PARTITION P2 VALUES LESS THAN(301) ,17 PARTITION P3 VALUES LESS THAN MAXVALUE18 );
上面的示例,利用了范围RANGE函数对岗位编号进行分区,共分为4个分区,
岗位编号为1~100 的对应在分区P0中,101~200的编号在分区P1中,依次类推即可。那么种别编号大于300,可以利用MAXVALUE来将大于300的数据统一存放在分区P3中即可。
3.2.3 LIST(预定义列表)类似于按RANGE分区,差异在于LIST分区是基于列值匹配一个离散值凑集中的某个值来进行选择分区的。LIST分区通过利用“PARTITION BY LIST(expr)”来实现,个中“expr” 是某列值或一个基于某个列值、并返回一个整数值的表达式,
然后通过“VALUES IN (value_list)”的办法来定义每个分区,个中“value_list”是一个通过逗号分隔的整数列表。 示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL,10 `gravalue` varchar(20) DEFAULT NULL,11 `createtime` DateTime NOT NULL12 ) ENGINE=InnoDB DEFAULT CHARSET=utf813 PARTITION BY LIST(`gwcode`) (14 PARTITION P0 VALUES IN (46,77,89) ,15 PARTITION P1 VALUES IN (106,125,177) ,16 PARTITION P2 VALUES IN (205,219,289) ,17 PARTITION P3 VALUES IN (302,317,458,509,610) 18 );
上面的例子,利用了列表匹配LIST函数对员工岗位编号进行分区,共分为4个分区,编号为46,77,89的对应在分区P0中,106,125,177种别在分区P1中,依次类推即可。
不同于RANGE的是,LIST分区的数据必须匹配列表中的岗位编号才能进行分区,以是这种办法只是适宜比较区间值确定并少量的情形。
3.2.4 KEY(键值)类似于按HASH分区,差异在于KEY分区只支持打算一列或多列,且MySQL 做事器供应其自身的哈希函数。必须有一列或多列包含整数值。 示例如下:
1 drop table if EXISTS `t_userinfo`; 2 CREATE TABLE `t_userinfo` ( 3 `id` int(10) unsigned NOT NULL, 4 `personcode` varchar(20) DEFAULT NULL, 5 `personname` varchar(100) DEFAULT NULL, 6 `depcode` varchar(100) DEFAULT NULL, 7 `depname` varchar(500) DEFAULT NULL, 8 `gwcode` int(11) DEFAULT NULL, 9 `gwname` varchar(200) DEFAULT NULL,10 `gravalue` varchar(20) DEFAULT NULL,11 `createtime` DateTime NOT NULL12 ) ENGINE=InnoDB DEFAULT CHARSET=utf813 PARTITION BY KEY(gwcode)14 PARTITIONS 10;
把稳:此种分区算法目前利用的比较少,利用做事器供应的哈希函数有不愿定性,对付后期数据统计、整理存在会更繁芜,以是我们更方向于利用由我们定义表达式的Hash,大家知道其存在和怎么利用即可。
3.2.5 Composite(复合模式)Composite是上面几种模式的组合利用,比如你在Range的根本上,再进行Hash 哈希分区。
3.3 分库分表库内分表办理了单表数据量过大的瓶颈问题,但利用还是同一主机的CPU、IO、内存,其余单库的连接数也有限定,并不能完备的降落系统的压力。
此时,我们就要考虑其余一种技能叫分库分表。分库分表在库内分表的根本上,将分的表挪动到不同的主机和数据库上。可以充分的利用其他主机的CPU、内存和IO资源。 拆分办法进一步演进到下面:
4 分库分表存在的问题4.1 事务问题
在实行分库分表之后,由于数据存储到了不同的库上,数据库事务管理涌现了困难。如果依赖数据库本身的分布式事务管理功能去实行事务,将付出高昂的性能代价;如果由运用程序去帮忙掌握,形成程序逻辑上的事务,又会造成编程方面的包袱。
4.2 跨库跨表的join问题在实行了分库分表之后,难以避免会将原来逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限定,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原来一次查询能够完成的业务,可能须要多次查询才能完成。
4.3 额外的数据管理包袱和数据运算压力额外的数据管理包袱,最显而易见的便是数据的定位问题和数据的增编削查的重复实行问题,这些都可以通过运用程序办理,但一定引起额外的逻辑运算,例如,对付一个记录用户成绩的用户数据表userTable,业务哀求查出成绩最好的100位,在进行分表之前,
只需一个order by语句就可以搞定,但是在进行分表之后,将须要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并打算,才能得出结果。
为帮助开拓者们提升口试技能、有机会入职BATJ等大厂公司,特殊制作了这个专辑——这一次整体放出。
大致内容包括了: Java 凑集、JVM、多线程、并发编程、设计模式、Spring百口桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、MySQL、RabbitMQ、Kafka、Linux、Netty、Tomcat等大厂口试题等、等技能栈!
欢迎大家关注公众年夜众号【Java烂猪皮】,回答【666】,获取以上最新Java后端架构VIP学习资料以及视频学习教程,然后一起学习,一文在手,口试我有。
每一个专栏都是大家非常关心,和非常有代价的话题,如果我的文章对你有所帮助,还请帮忙点赞、好评、转发一下,你的支持会勉励我输出更高质量的文章,非常感谢!















