
在linux下首先更新apt包:
sudoapt-getupdate
安装SSH server:

sudo apt-get install openssh-server
配置SSH:
ssh localhost
输入密码登录本机和退出本机:
exit
由于须要跨机器登录,以是还须要配置无密码。在进行了初次上岸后,进入.ssh文件夹下:
cd ~/.ssh/
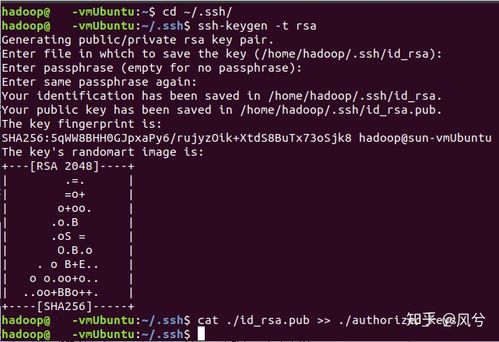
利用rsa算法天生秘钥和公钥对:
ssh-keygen -t rsa
运行后一起Enter,个中第一个是要输入秘钥和公钥对的保存位置,默认是在:.ssh/id_rsa。然后把公钥加入到授权中:
cat ./id_rsa.pub >> ./authorized_keys
再次ssh localhost 就可以无密码登录了。
安装JDK:
首先检讨Java是否已经安装:
java -version
如果没有安装,点击链接https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 并选择相应系统以及位数下载(本文选择jdk-8u241-linux-x64.tar.gz,如详细版天职歧则灵巧修正).
为其单独创立一个文件夹,然后将其放到该目录下(下载后以详细为止为准):
sudo mkdir -p /usr/local/javasudomv~/Downloads/jdk-8u241-linux-x64.tar.gz /usr/local/java/
进入该目录进行解压:
cd /usr/local/javasudo tar xvzf jdk-8u241-linux-x64.tar.gz
解压成功后会在当前目录下看到jdk1.8.0_241安装包,然后删除安装包:
sudormjdk-8u241-linux-x64.tar.gz
配置JDK:
设置环境变量,打开环境变量的配置文件:
sudo vim /etc/profile
在末端添加:
JAVA_HOME=/usr/local/java/jdk1.8.0_241PATH=$PATH:$HOME/bin:$JAVA_HOME/binexport JAVA_HOMEexport PATH
见告linux Java JDK的位置并设置为默认模式:
sudoupdate-alternatives--install"/usr/bin/java""java""/usr/local/java/jdk1.8.0_241/bin/java"1sudoupdate-alternatives--install"/usr/bin/javac""javac""/usr/local/java/jdk1.8.0_241/bin/javac"1sudo update-alternatives--install"/usr/bin/javaws""javaws""/usr/local/java/jdk1.8.0_241/bin/javaws"1sudoupdate-alternatives--setjava/usr/local/java/jdk1.8.0_241/bin/javasudoupdate-alternatives--setjavac/usr/local/java/jdk1.8.0_241/bin/javacsudoupdate-alternatives--setjavaws/usr/local/java/jdk1.8.0_241/bin/javaws
重新加载环境变量的配置文件:
source /etc/profile
检测Java版本:
java -version
如果涌现以下代表成功:
java version "1.8.0_241"Java(TM) SE Runtime Environment (build 1.8.0_241-b07)JavaHotSpot(TM)64-BitServerVM(build25.241-b07,mixedmode)
安装Hadoop:
进入镜像文件https://mirrors.cnnic.cn/apache/hadoop/common/ 并选择对应Hadoop版本(把稳版本不是越新越好,要考虑版本兼容问题,本文选择hadoop-2.10.0.tar.gz)
然后将其解压至刚刚创建的文件夹 /usr/local并删除安装包:
sudo tar -zxf ~/Downloads/hadoop-2.10.0.tar.gz -C /usr/localrm ~/Downloads/hadoop-2.10.0.tar.gz
重命名文件夹并修正权限(个中phenix为用户名):
cd/usr/local/sudomvhadoop-2.10.0hadoopsudo chown -R phenix ./hadoop
检测hadoop版本:
/usr/local/hadoop/bin/hadoop version
涌现以下信息则代表成功:
Hadoop 2.10.0Subversion ssh://git.corp.linkedin.com:29418/hadoop/hadoop.git -r e2f1f118e465e787d8567dfa6e2f3b72a0eb9194Compiled by jhung on 2019-10-22T19:10ZCompiled with protoc 2.5.0From source with checksum 7b2d8877c5ce8c9a2cca5c7e81aa4026This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.10.0.jar
配置Hadoop(伪分布式):
切换到路径/usr/local/hadoop/etc/hadoop下,须要修正2个配置文件core-site.xml和hdfs-site.xml。
首先打开core-site.xml
cd /usr/local/hadoop/etc/hadoopvimcore-site.xml
在<configuration></configuration>中添加如下配置:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property></configuration>
注:本文利用的是hdfs://localhost:9000即hdfs文件系统
再打开hdfs-site.xml:
vim hdfs-site.xml
同样在<configuration></configuration>中添加如下配置:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/tmp/dfs/data</value> </property></configuration>
注:dfs.replication便是指备份的份数;dfs.namenode.name.dir和dfs.datanode.data.dir分别指名称节点和数据节点存储路径
切换回hadoop主目录并实行NameNode的格式化(格式化成功后轻易不要再次格式化):
cd/usr/local/hadoop./bin/hdfs namenode -format
涌现以下信息代表成功:
00000000 using no compression18/08/20 11:07:16 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 320 bytes saved in 0 seconds .18/08/20 11:07:16 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 018/08/20 11:07:16 INFO namenode.NameNode: SHUTDOWN_MSG:/SHUTDOWN_MSG: Shutting down NameNode at phenix/127.0.1.1/
手动添加JAVA_HOME,在hadoop-env.sh文件中添:
cdetc/hadoop/ vimhadoop-env.sh
在hadoop-env.sh文件中添加如下内容即可:
export JAVA_HOME=/usr/local/java/jdk1.8.0_241
开启NameNode和DataNode守护进程:
./sbin/start-dfs.sh
开启yarn资源管理器:
./sbin/start-yarn.sh
验证:
jps
涌现以下六个则代表启动成功:
18192DataNode18922 NodeManager20044 Jps18812 ResourceManager18381 SecondaryNameNode18047 NameNode
大略示例:
首先切换至hadoop主目录并在HDFS中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
创建输入文件夹:
./bin/hdfs dfs -mkdir /user/hadoop/input
将etc/hadoop下所有的xml文件复制到输入:
./bin/hdfs dfs -put ./etc/hadoop/.xml /user/hadoop/input
然后通过命令查看:
./bin/hdfs dfs -ls /user/hadoop/input
结果如下:
Found 8 items-rw-r--r-- 1 phenix supergroup 8814 2020-01-31 13:21 /user/hadoop/input/capacity-scheduler.xml-rw-r--r-- 1 phenix supergroup 1119 2020-01-31 13:21 /user/hadoop/input/core-site.xml-rw-r--r-- 1 phenix supergroup 10206 2020-01-31 13:21 /user/hadoop/input/hadoop-policy.xml-rw-r--r-- 1 phenix supergroup 1173 2020-01-31 13:21 /user/hadoop/input/hdfs-site.xml-rw-r--r-- 1 phenix supergroup 620 2020-01-31 13:21 /user/hadoop/input/httpfs-site.xml-rw-r--r-- 1 phenix supergroup 3518 2020-01-31 13:21 /user/hadoop/input/kms-acls.xml-rw-r--r-- 1 phenix supergroup 5939 2020-01-31 13:21 /user/hadoop/input/kms-site.xml-rw-r--r--1phenixsupergroup6902020-01-3113:21/user/hadoop/input/yarn-site.xml
运行grep:
./bin/hadoopjar./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jargrep/user/hadoop/inputoutput'dfs[a-z]+'
查看运行结果:
./bin/hdfs dfs -cat output/
涌现以下输出则解释Hadoop集群搭建完成:
1 1 dfsadmin
我们还可以利用HDFS Web界面,不过只能查看文件系统数据,点击链接http://localhost:50070即可进行查看:
同时也可通过http://localhost:8088/cluster查看hadoop集群当前运用状况:
关闭Hadoop:
./sbin/stop-dfs.sh./sbin/stop-yarn.sh
末了!
细心的同学会创造每次开启关闭都得切换至指定目录不太方便,因此我们将其加入环境变量中,开启更加方便:
vim /etc/bash.bashrc
在末端添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_241export JRE_HOME=${JAVA_HOME}/jreexport HADOOP_HOME=/usr/local/hadoopexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
然后实行source更新命令:
source /etc/bash.bashrc
之后会创造在任意位置考试测验hadoop命令都会输出对应结果:
hadoop version
至此Hadoop安装及环境配置完成。















