
在本章中,我们将摆脱 JSON 文件并引入 PostgreSQL 数据库来存储数据。 我们将通过利用 Docker 设置数据库开拓环境来实现此目的。 我们还将研究如何监控 Docker 数据库容器。 然后,我们将创建迁移来构建数据库架构,然后在 Rust 中构建数据模型以与数据库交互。 然后,我们将重构我们的运用程序,以便创建、编辑和删除端点与数据库而不是 JSON 文件进行交互。
在本章中,我们将谈论以下主题:

构建我们的 PostgreSQL 数据库
利用 Diesel 连接到 PostgreSQL
将我们的运用程序连接到 PostgreSQL
配置我们的运用程序
管理数据库连接池
在本章结束时,您将能够管理一个利用数据模型在 PostgreSQL 数据库中实行读取、写入和删除数据的运用程序。 如果我们对数据模型进行变动,我们将能够通过迁移来管理它们。 完成此操作后,您将能够优化与池的数据库连接,并让做事器在无法建立数据库连接的情形下在 HTTP 要求到达视图之前谢绝该要求。
技能哀求在本章中,我们将利用 Docker 来定义、运行 PostgreSQL 数据库并运行它。 这将使我们的运用程序能够与本地打算机上的数据库进行交互。 可以按照 https://docs.docker.com/engine/install/ 上的解释安装 Docker。
我们还将在 Docker 之上利用 docker-compose 来编排我们的 Docker 容器。 可以按照 https://docs.docker.com/compose/install/ 上的解释进行安装。
构建我们的 PostgreSQL 数据库
到目前为止,我们一贯在利用 JSON 文件来存储待办事项。 到目前为止,这对我们很有帮助。 事实上,我们没有情由不能在本书的别的部分中利用 JSON 文件来完成任务。 但是,如果您将 JSON 文件用于生产项目,您会碰着一些缺陷。
为什么我们该当利用得当的数据库如果对 JSON 文件的读取和写入增加,我们可能会面临一些并发问题和数据破坏。 也没有检讨数据的类型。 因此,另一个开拓职员可以编写一个函数,将不同的数据写入 JSON 文件,没有任何障碍。
还有一个迁移问题。 如果我们想向待办事项添加韶光戳,这只会影响我们插入到 JSON 文件中的新待办事项。 因此,我们的一些待办事项将有韶光戳,而另一些则没有,这会给我们的运用程序带来缺点。 我们的 JSON 文件在过滤方面也有限定。
现在,我们所做的便是读取全体数据文件,变动全体数据集中的项目,并将全体数据集写入 JSON 文件。 这是无效的并且不能很好地扩展。 它还阻挡我们将这些待办事项链接到另一个类似数据模型的用户。 其余,我们现在只能利用状态进行搜索。 如果我们利用带有链接到待办事项数据库的用户表的 SQL 数据库,我们将能够根据用户、状态或标题过滤待办事项。 我们乃至可以利用它们的组合。 当谈到运行我们的数据库时,我们将利用 Docker。 那么我们为什么要利用Docker呢?
为什么利用 Docker?要理解为什么要利用 Docker,我们首先须要理解 Docker 是什么。 Docker 实质上具有像虚拟机一样事情的容器,但以更详细和更风雅的办法事情。 Docker 容器隔离单个运用程序及其所有依赖项。 该运用程序在 Docker 容器内运行。 然后 Docker 容器就可以相互通信。 由于 Docker 容器共享一个通用操作系统 (OS),因此它们彼此之间以及全体操作系统之间是分别隔的,这意味着与虚拟机比较,Docker 运用程序利用的内存更少。 由于 Docker 容器,我们的运用程序可以更加便携。 如果 Docker 容器在您的打算机上运行,它将在另一台也具有 Docker 的打算机上运行。 我们还可以打包我们的运用程序,这意味着我们的运用程序运行所需的额外包不须要单独安装,包括操作系统级别的依赖项。 因此,Docker 为我们的 Web 开拓供应了极大的灵巧性,由于我们可以在本地打算机上仿照做事器和数据库。
如何利用Docker运行数据库考虑到所有这些,实行设置和运行 SQL 数据库所需的额外步骤是故意义的。 为此,我们将利用 Docker:一个帮助我们创建和利用容器的工具。 容器本身是 Linux 技能,用于打包和隔离运用程序及其全体运行时环境。 容器在技能上是隔离的文件系统,但为了帮助可视化我们在本章中所做的事情,您可以将它们视为迷你轻量级虚拟机。 这些容器由可从 Docker Hub 下载的映像组成。 我们可以将自己的代码插入到这些图像中,然后再从个中旋转出容器,如下图所示:
图 6.1 – Docker 镜像和容器之间的关系
利用 Docker,我们可以下载一个镜像,例如 PostgreSQL 数据库,并在我们的开拓环境中运行它。 借助 Docker,我们可以启动多个数据库和运用程序,然后在须要时关闭它们。 首先,我们须要通过在终端中运行以下命令来盘点容器:
docker container ls -a
如果 Docker 是全新安装的,我们会得到以下输出:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
正如我们所看到的,我们没有容器。 我们还须要盘点我们的图像。 这可以通过运行以下终端命令来完成:
docker image ls
前面的命令给出以下输出:
REPOSITORY TAG IMAGE ID CREATED SIZE
再说一遍,如果 Docker 是全新安装的,那么就不会有容器。
我们还可以通过其他办法在 Docker 中创建数据库。 例如,我们可以创建自己的 Dockerfile,在个中定义操作系统和配置。 但是,我们已经安装了 docker-compose。 利用 docker-compose 将使数据库定义变得大略。 它还将使我们能够添加更多容器和做事。 为了定义 PostgreSQL 数据库,我们在根目录的 docker-compose.yml 文件中编写以下 YAML 代码:
version: "3.7"services: postgres: container_name: 'to-do-postgres' image: 'postgres:11.2' restart: always ports: - '5432:5432' environment: - 'POSTGRES_USER=username' - 'POSTGRES_DB=to_do' - 'POSTGRES_PASSWORD=password'
在前面的代码中,我们在文件顶部定义了版本。 旧版本(例如 2 或 1)具有不同的文件布局样式。 不同的版本也支持不同的论点。 在撰写本书时,第 3 版是最新版本。 以下 URL 涵盖了每个 docker-compose 版本之间的变动:https://docs.docker.com/compose/compose-file/compose-versioning/。
然后我们定义嵌套在 postgres 标签下的数据库做事。 postgres 和 services 等标签表示字典,列表中的每个元素用 - 定义。 如果我们将 docker-compose 文件转换为 JSON,它将具有以下构造:
{ "version": "3.7", "services": { "postgres": { "container_name": "to-do-postgres", "image": "postgres:11.2", "restart": "always", "ports": [ "5432:5432" ], "environment": [ "POSTGRES_USER=username", "POSTGRES_DB=to_do", "POSTGRES_PASSWORD=password" ] } }}
在前面的代码中,我们可以看到我们的做事是表示每个做事的字典的字典。 因此,我们可以推断出我们不能有两个同名的标签,由于我们不能有两个相同的字典键。 前面的代码还见告我们,我们可以连续堆叠具有自己参数的做事标签。
在 Docker 中运行数据库对付我们的数据库做事,我们有一个名称,因此当我们查看容器时,我们知道每个容器与做事(例如做事器或数据库)干系的功能。 在配置数据库和构建数据库方面,我们幸运地拉取了官方的 postgres 镜像。 该镜像已为我们配置了所有内容,Docker 将从存储库中提取它。 该图像就像一个蓝图。 我们可以从我们拉取的一个镜像中利用它们自己的参数来启动多个容器。 然后我们一如既往地定义重启策略。 这意味着容器的重启策略将在容器退出时触发。 我们还可以将其定义为仅根据故障或停滞重新启动。
须要把稳的是,Docker 容器有自己的端口,不对机器开放。 但是,我们可以公开容器端口并将公开的端口映射到 Docker 容器内的内部端口。 考虑到这些功能,我们可以定义我们的端口。
然而,在我们的示例中,我们将保持大略的定义。 我们将声明我们接管端口 5432 上的 Docker 容器的传入流量,并将其路由到内部端口 5432。然后,我们将定义环境变量,即用户名、数据库名称和密码。 虽然我们在本书中利用通用的、易于记住的密码和用户名,但建议您在推送莅临盆环境时切换到更安全的密码和用户名。 我们可以通过运行以下命令导航到 docker-compose 文件所在的根目录来为我们的系统构建旋转:
docker-compose up
前面的命令将从存储库中拉取 postgres 映像并开始构建数据库。 在一系列日志之后,终端该当停滞并显示以下输出:
LOG: listening on IPv4 address "0.0.0.0", port 5432LOG: listening on IPv6 address "::", port 5432LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"LOG: database system was shut down at 2022-04-23 17:36:45 UTCLOG: database system is ready to accept connections
如您所见,日期和韶光会有所不同。 然而,我们在这里被奉告的是我们的数据库已准备好接管连接。 是的,确实便是这么大略。 因此,Docker 的采取是势不可挡的。 单击 Ctrl + C 将停滞我们的 docker-compose; 因此,关闭我们的 postgres 容器。
现在,我们利用以下命令列出所有容器:
docker container ls -a
前面的命令为我们供应了以下输出:
CONTAINER ID IMAGE COMMAND c99f3528690f postgres:11.2 "docker-entrypoint.s…"CREATED STATUS PORTS4 hours ago Exited (0) About a minute ago NAMESto-do-postgres
在前面的输出中,我们可以看到所有参数都在那里。 然而,由于我们停滞了做事,端口是空的。
探索 Docker 中的路由和端口如果我们要再次启动做事并在另一个终端中列出我们的容器,则端口 5432 将位于 PORTS 标签下。 我们必须记下 Docker 容器的 CONTAINER ID 引用,由于它对付每个容器来说都是唯一且不同/随机的。 如果我们要访问日志,我们将须要引用这些。 当我们运行 docker-compose up 时,我们基本上利用以下构造:
图 6.2 – docker-compose 为我们的数据库供应做事
在图 6.2 中,我们可以看到我们的 docker-compose 利用唯一的项目名称将容器和网络保留在其命名空间中。 必须把稳的是,我们的容器在本地主机上运行。 因此,如果我们想调用 docker-compose 管理的容器,我们必须发出 localhost 要求。 但是,我们必须调用从 docker-compose 打开的端口,并且 docker-compose 会将其路由到 docker-compose.yml 文件中定义的端口。 例如,我们有两个数据库,个中包含以下 yml 文件:
version: "3.7"services: postgres: container_name: 'to-do-postgres' image: 'postgres:11.2' restart: always ports: - '5432:5432' environment: - 'POSTGRES_USER=username' - 'POSTGRES_DB=to_do' - 'POSTGRES_PASSWORD=password' postgres_two: container_name: 'to-do-postgres_two' image: 'postgres:11.2' restart: always ports: - '5433:5432' environment: - 'POSTGRES_USER=username' - 'POSTGRES_DB=to_do' - 'POSTGRES_PASSWORD=password'
在前面的代码中,我们可以看到我们的两个数据库都通过端口 5432 接管进入其容器的流量。但是,这会发生冲突,因此我们打开的端口之一是端口 5433,该端口被路由到端口 5432 第二个数据库容器,它为我们供应了以下布局:
图 6.3 – docker-compose 为多个数据库供应做事
这种路由为我们运行多个容器时供应了灵巧性。 我们不会为待办事项运用程序运行多个数据库,因此我们该当删除 postgres_two 做事。 一旦我们删除了 postgres_two 做事,我们就可以再次运行 docker-compose,然后利用以下命令列出我们的容器:
docker image ls
前面的命令现在将为我们供应以下输出:
REPOSITORY TAG IMAGE ID postgres 11.2 3eda284d1840CREATED SIZE17 months ago 312MB
在前面的输出中,我们可以看到我们的映像已从 postgres 存储库中提取。 我们还有一个图像的唯一/随机 ID 以及该图像的创建日期。
现在我们已经基本理解了如何启动和运行数据库,我们可以利用以下命令在后台运行 docker-compose:
docker-compose up -d
前面的命令只是见告我们哪些容器已启动,输出如下:
Starting to-do-postgres ... done
当我们利用以下输出列出容器时,我们可以看到我们的状态:
STATUS PORTS NAMESUp About a minute 0.0.0.0:5432->5432/tcp to-do-postgres
在前面的输出中,其他标签是相同的,但我们还可以看到 STATUS 标签见告我们容器已经运行了多永劫光,以及它占用了哪个端口。 虽然 docker-compose 在后台运行,但这并不虞味着我们看不到发生了什么。 我们可以随时通过调用logs命令并利用以下命令引用容器的ID来访问容器的日志:
docker logs c99f3528690f
前面的命令该当供应与我们的标准 docker-compose up 命令相同的输出。 要停滞 docker-compose,我们可以运行 stop 命令,如下所示:
docker-compose stop
前面的命令将停滞 docker-compose 中的容器。 须要把稳的是,这与down命令不同,如下所示:
docker-compose down
down 命令也将停滞我们的容器。 但是,down 命令将删除该容器。 如果我们的数据库容器被删除,我们也将丢失所有数据。
有一个名为volumes的配置参数,可以防止容器被移除时我们的数据被删除; 然而,这对付我们打算机上确当地开拓来说并不是必需的。 事实上,您会希望定期从条记本电脑中删除容器和映像。 我在条记本电脑上打消了一次不再利用的容器和图像,这开释了 23GB!
我们本地开拓机器上的 Docker 容器该当被视为临时容器。 虽然 Docker 容器比标准虚拟机更轻量,但它们不是免费的。 在本地打算机上运行 Docker 背后的想法是,我们可以仿照在做事器上运行运用程序的情形。 如果它在我们条记本电脑上的 Docker 中运行,我们可以确定它也将在我们的做事器上运行,特殊是当做事器由 Kubernetes 等生产就绪的 Docker 编排工具管理时。
利用 Bash 脚本在后台运行 DockerDocker 还可以帮助进行同等的测试和开拓。 我们希望每次运行测试时都能得到相同的结果。 我们还希望轻松地加入其他开拓职员,并使他们能够拆卸和启动容器,以快速轻松地支持开拓。 我个人亲眼目睹了由于不支持大略的拆卸和启动程序而造成的开拓延迟。 例如,在处理繁芜的运用程序时,我们添加和测试的代码可能会破坏数据库。 规复可能是不可能的,删除数据库并重新开始会很痛楚,由于重修这些数据可能须要很永劫光。 开拓职员乃至可能不记得他们最初是如何构建数据的。 有多种方法可以防止这种情形发生,我们将在第 9 章“测试我们的运用程序端点和组件”中先容这些方法。
现在,我们将构建一个脚本,在后台启动数据库,等待与数据库的连接准备就绪,然后拆除数据库。 这将为我们构建管道、测试和入门包以开始开拓奠定根本。 为此,我们将在 Rust Web 运用程序的根目录中创建一个名为 script 的目录。 然后我们可以创建一个 scripts/wait_for_database.sh 文件,个中包含以下代码:
#!/bin/bashcd ..docker-compose up -duntil pg_isready -h localhost -p 5432 -U usernamedo echo "Waiting for postgres" sleep 2;doneecho "docker is now running"docker-compose down
利用前面的代码,我们将脚本确当前事情目录从脚本目录移到根目录中。 然后我们在后台启动 docker-compose。 接下来,我们循环利用 pq_isready 命令 ping 端口 5432,等待数据库准备好接管连接。
主要的提示
pg_isready Bash 命令可能在您的打算机上不可用。 pg_isready 命令常日随 PostgreSQL 客户真个安装一起供应。 或者,您可以利用以下 Docker 命令代替 pg_isready:
直到 docker run -it postgres --add-host host.docker.internal:host-gateway docker.io/postgres:14-alpine -h localhost -U 用户名 pg_isready
这里发生的情形是,我们利用 postgres Docker 映像来运行数据库检讨,以确保我们的数据库已准备好接管连接。
一旦我们的数据库正在运行,我们就会在掌握台上打印出我们的数据库正在运行,然后拆除我们的 docker-compose,销毁数据库容器。 运行 wait_for_database.sh Bash 脚本的命令将给出以下输出:
❯ sh wait_for_database.sh [+] Running 0/0 ⠋ Network web_app_default Creating 0.2s ⠿ Container to-do-postgres Started 1.5slocalhost:5432 - no responseWaiting for postgreslocalhost:5432 - no responseWaiting for postgreslocalhost:5432 - accepting connectionsdocker is now running[+] Running 1/1 ⠿ Container to-do-postgres Removed 1.2s ⠿ Network web_app_default Removed
从前面的输出中,考虑到我们让循环在每次迭代时休眠 2 秒,我们可以推断出新启动的数据库大约须要 4 秒才能接管连接。 至此,我们已经具备了利用Docker管理本地数据库的基本能力。
在本节中,我们设置环境。 我们还充分理解了 Docker 的根本知识,只需几个大略的命令即可构建、监控、关闭和删除我们的数据库。 现在,我们可以连续下一部分,我们将利用 Rust 和Diesel与数据库进行交互。
利用 Diesel 连接到 PostgreSQL现在我们的数据库正在运行,我们将在本节中建立与该数据库的连接。 为此,我们将利用disel。 diesel使我们能够将 Rust 代码连接到数据库。 我们利用Diesel而不是其他crate,由于Diesel是最成熟的,有大量的支持和文档。 为此,我们须要实行以下步骤:
首先,我们将利用Dielsel。 为此,我们可以在 Cargo.toml 文件中添加以下依赖项:
diesel = { version = "1.4.8", features = ["postgres", "chrono", "r2d2"] }dotenv = "0.15.0"chrono = "0.4.19"
在前面的代码中,我们在diesel crate中包含了postgres功能。 柴油箱定义还具有 chrono 和 r2d2 功能。 chrono 功能使我们的 Rust 代码能够利用日期韶光构造。 r2d2 功能使我们能够实行连接池。 我们将在本章末端先容连接池。 我们还包含了 dotenv 板条箱。 这个包使我们能够在 .env 文件中定义变量,然后将其通报到我们的程序中。 我们将利用它来通报数据库凭据,然后通报到进程中。
我们现在须要安装diesel客户端以通过我们的终端而不是我们的运用程序运行到数据库的迁移。 我们可以利用以下命令来完成此操作:
cargo install diesel_cli --no-default-features --features postgres
我们现在须要定义环境 DATABASE_URL URL。 这将使我们的客户端命令能够利用以下命令连接到数据库:
echo DATABASE_URL=postgres://username:password@localhost/to_do > .env
在前面的URL中,我们的用户名表示为username,我们的密码表示为password。 我们的数据库运行在我们自己的打算机上,表示为 localhost,我们的数据库称为 to_do。 这会在根文件中创建一个 .env 文件,输出以下内容:
DATABASE_URL=postgres://username:password@localhost/to_do
现在我们的变量已经定义了,我们可以开始设置数据库了。 我们须要利用 docker-compose up 命令来启动我们的数据库容器。 然后我们利用以下命令设置数据库:
diesel setup
然后,上述命令在根目录中创建一个具有以下构造的迁移目录:
── migrations│ └── 00000000000000_diesel_initial_setup│ ├── down.sql│ └── up.sql
升级迁移时会触发 up.sql 文件,降级迁移时会触发 down.sql 文件。
现在,我们须要创建迁移来创建待办事项。 这可以通过命令我们的客户端利用以下命令天生迁移来完成:
diesel migration generate create_to_do_items
运行后,我们该当在掌握台中得到以下打印输出:
Creating migrations/2022-04-23-201747_create_to_do_items/up.sqlCreating migrations/2022-04-23-201747_create_to_do_items/down.sql
前面的命令在迁移中为我们供应了以下文件构造:
├── migrations│ ├── 00000000000000_diesel_initial_setup│ │ ├── down.sql│ │ └── up.sql│ └── 2022-04-23-201747_create_to_do_items│ ├── down.sql│ └── up.sql
从表面上看,利用diesel彷佛很不幸,我们将不得不创建自己的 SQL 文件。 然而,这迫使我们采纳良好的做法。 虽然让 crate 自动编写 SQL 更随意马虎,但这将我们的运用程序与数据库耦合在一起。 例如,有一次我正在重构一个微做事系统。 我碰着的问题是我利用 Python 包来管理数据库的所有迁移。 但是,我想变动做事器的代码。 听到我要将做事器从 Python 切换到 Rust,您不会感到惊异。 然而,由于迁移是由 Python 库自动天生的,以是我必须构建赞助 Docker 容器,直到本日,这些容器在新版本完成时启动,然后在发布时将数据库模式复制到 Rust 运用程序。 正在培植中。 这很混乱。 这也阐明了为什么当我还是金融科技领域的研发软件工程师时,我们必须手动编写所有 SQL。
数据库与我们的运用程序是分开的。 因此,我们该当将它们隔离开来,这样我们就不会认为手动编写 SQL 是一种障碍。 拥抱它,由于你正在学习一项好技能,这将让你在未来不再头痛。 我们必须记住,不要强制一种工具用于所有事情,它必须是适宜精确事情的精确工具。 在创建待办事项迁移文件夹中,我们在 up.sql 文件中利用以下 SQL 条款定义 to_do 表:
CREATE TABLE to_do ( id SERIAL PRIMARY KEY, title VARCHAR NOT NULL, status VARCHAR NOT NULL, date timestamp NOT NULL DEFAULT NOW())
在前面的代码中,我们有一个唯一的项目 ID。 这样我们就有了头衔和地位。 我们还添加了一个日期字段,默认情形下,该字段包含待办事项插入表中确当前韶光。 这些字段包含在 CREATE TABLE 命令中。 在 down.sql 文件中,如果我们利用以下 SQL 命令降级迁移,则须要删除该表:
DROP TABLE to_do
现在我们已经为 up.sql 和 down.sql 文件编写了 SQL 代码,我们可以用下图描述我们的代码的浸染:
图 6.4 – up.sql 和 down.sql 脚本的效果
现在我们的迁移已准备就绪,我们可以利用以下终端命令运行它:
diesel migration run
前面的命令运行创建 to_do 表的迁移。 有时,我们可能会在 SQL 中引入不同的字段类型。 为了纠正这个问题,我们可以变动 up.sql 和 down.sql 文件中的 SQL 并运行以下重做终端命令:
diesel migration redo
前面的命令将运行 down.sql 文件,然后运行 up.sql 文件。
接下来,我们可以在数据库 Docker 容器中运行命令来检讨我们的数据库是否具有包含我们定义的精确字段的 to_do 表。 我们可以通过直接在数据库 Docker 容器上运行命令来做到这一点。 我们可以利用用户名username进入容器,同时利用以下终端命令指向to_do数据库:
docker exec -it 5fdeda6cfe43 psql -U username to_do
须要把稳的是,在上面的命令中,我的容器ID是5fdeda6cfe43,但你的容器ID会不同。 如果您没有输入精确的容器 ID,您将无法在精确的数据库上运行精确的数据库命令。 运行该命令后,我们会得到一个 shell 界面,提示如下:
to_do=#
在涌现上述提示后,当我们输入\c时,我们将连接到数据库。 这常日用一条语句表示,表示我们现在已连接到 to_do 数据库并作为用户名 user。 末了,输入 \d 将列出关系,在终端中给出下表:
Schema | Name | Type | Owner --------+----------------------------+----------+---------- public | __diesel_schema_migrations | table | username public | to_do | table | username public | to_do_id_seq | sequence | username
从上表中我们可以看到有一个migrations表来跟踪数据库的迁移版本。
我们还有 to_do 表和 to_do 项目 ID 的序列。 要检讨模式,我们须要做的便是输入 \d+ to_do,这会在终端中供应以下模式:
Table "public.to_do" Column | Type | Collation |--------+-----------------------------+-----------+ id | integer | | title | character varying | | status | character varying | | date | timestamp without time zone | || Nullable | Default | Storage |+----------+-----------------------------------+----------+| not null | nextval('to_do_id_seq'::regclass) | plain | | not null | | extended | | not null | | extended | | not null | now() | plain | Indexes: "to_do_pkey" PRIMARY KEY, btree (id)
在上表中,我们可以看到我们的模式正是我们设计的。 我们在日期列中得到了更多信息,澄清我们没有得到待办事项的创建韶光。 鉴于我们的迁移已经成功,我们该当不才一步中探索迁移如何在数据库中显示。
我们可以通过运行以下 SQL 命令来检讨我们的迁移表:
SELECT FROM __diesel_schema_migrations;
前面的命令为我们供应了下表作为输出:
version | run_on ----------------+---------------------------- 00000000000000 | 2022-04-25 23:10:07.774008 20220424171018 | 2022-04-25 23:29:55.167845
正如您所看到的,这些迁移对付调试非常有用,由于有时我们可能会忘却在更新数据模型后运行迁移。 为了进一步探索这一点,我们可以在 Docker 容器外部利用以下命令规复上次迁移:
diesel migration revert
然后我们得到以下打印输出,关照我们回滚已实行:
Rolling back migration 2022-04-24-171018_create_to_do_items
现在我们的迁移已经回滚,我们的迁移表将类似于以下打印输出:
version | run_on ----------------+---------------------------- 00000000000000 | 2022-04-25 23:10:07.774008
在前面的打印输出中,我们可以看到上次迁移已被删除。 因此,我们可以推断出迁移表不这天记。 它仅跟踪当前活动的迁移。 迁移跟踪将帮助柴油客户在运行迁移时进行精确的迁移。
在本节中,我们利用diesel客户端连接到Docker容器中的数据库。 然后我们在环境文件中定义数据库 URL。 接下来,我们初始化了一些迁移并在数据库中创建了一个表。 更好的是,我们直接连接到 Docker 容器,我们可以在个中运行一系列命令来探索我们的数据库。 现在我们的数据库可以通过终端中的客户端完备交互,我们可以开始构建待办事项数据库模型,以便我们的 Rust 运用程序可以与我们的数据库交互。
将我们的运用程序连接到 PostgreSQL在上一节中,我们成功地利用终端连接到 PostgreSQL 数据库。 但是,我们现在须要我们的运用程序来管理待办事项的数据库读写。 在本节中,我们将把我们的运用程序连接到在 Docker 中运行的数据库。 要连接,我们必须构建一个函数来建立连接然后返回它。 必须强调的是,有一种更好的方法来管理数据库连接和配置,我们将在本章末端先容。 现在,我们将实现最大略的数据库连接来运行我们的运用程序。 在 src/database.rs 文件中,我们利用以下代码定义该函数:
use diesel::prelude::;use diesel::pg::PgConnection;use dotenv::dotenv;use std::env;pub fn establish_connection() -> PgConnection { dotenv().ok(); let database_url = env::var("DATABASE_URL") .expect("DATABASE_URL must be set"); PgConnection::establish(&database_url) .unwrap_or_else( |_| panic!("Error connecting to {}", database_url))}
在前面的代码中,首先,您可能会把稳到利用diesel::prelude::; 导入命令。 此命令导入一系列连接、表达式、查询、序列化和结果构造。 完成所需的导入后,我们定义连接函数。 首先,我们须要确保如果利用 dotenv().(); 加载环境失落败,程序不会抛出错误。 命令。
完成此操作后,我们从环境变量中获取数据库 URL,并利用对数据库 URL 的引用建立连接。 然后我们解开结果,如果我们不设法做到这一点,我们可能会错愕地显示数据库 URL,由于我们希望确保利用精确的 URL 和精确的参数。 由于连接是函数中的末了一条语句,因此这便是返回的内容。
现在我们有了自己的连接,我们须要定义模式。 这会将待办事项的变量映射到数据类型。 我们可以利用以下代码在 src/schema.rs 文件中定义模式:
table! { to_do (id) { id -> Int4, title -> Varchar, status -> Varchar, date -> Timestamp, }}
在前面的代码中,我们利用了diesel宏table!,它指定一个表存在。 这个映射很大略,我们将来将利用这个模式来引用数据库查询和插入中的列和表。
现在我们已经构建了数据库连接并定义了模式,我们必须利用以下导入在 src/main.rs 文件中声明它们:
#[macro_use] extern crate diesel;extern crate dotenv;use actix_web::{App, HttpServer};use actix_service::Service;use actix_cors::Cors;mod schema;mod database;mod views;mod to_do;mod state;mod processes;mod json_serialization;mod jwt;
在前面的代码中,我们的第一次导入还启用了过程宏。 如果我们不该用#[macro_use]标签,那么我们将无法在其他文件中引用我们的模式。 我们的模式定义也将无法利用表宏。 我们还导入 dotenv 板条箱。 我们保留在第 5 章“在浏览器中显示内容”中创建的模块。 我们还定义了模式和数据库模块。 完成此操作后,我们就拥有了开始构建数据模型所需的统统。
创建我们的数据模型我们将利用我们的数据模型来定义 Rust 数据库中数据的参数和行为。 它们实质上充当数据库和 Rust 运用程序之间的桥梁,如下图所示:
图 6.5 – 模型、模式和数据库之间的关系
在本节中,我们将定义待办事项的数据模型。 但是,我们须要使我们的运用程序能够根据须要添加更多数据模型。 为此,我们实行以下步骤:
我们定义了一个新的待办事项数据模型构造。
然后,我们为新的待办事项构造定义一个布局函数。
末了,我们定义一个待办事项数据模型构造。
在开始编写任何代码之前,我们在 src 目录中定义以下文件构造,如下所示:
├── models│ ├── item│ │ ├── item.rs│ │ ├── mod.rs│ │ └── new_item.rs│ └── mod.rs
在上述构造中,每个数据模型在 models 目录中都有一个目录。 在该目录中,我们有两个定义模型的文件。 一个用于新插入,另一个用于管理数据库周围的数据。 新的插入数据模型没有 ID 字段。
没有ID字段,由于数据库会为该项目分配一个ID; 我们之前没有定义它。 然而,当我们与数据库中的项目交互时,我们将获取它们的ID,并且我们可能希望通过ID进行过滤。 因此,现有的数据项模型包含一个ID字段。 我们可以利用以下代码在 new_item.rs 文件中定义新的项目数据模型:
use crate::schema::to_do;use chrono::{NaiveDateTime, Utc};#[derive(Insertable)]#[table_name="to_do"]pub struct NewItem { pub title: String, pub status: String, pub date: NaiveDateTime}impl NewItem { pub fn new(title: String) -> NewItem { let now = Utc::now().naive_local(); return NewItem{ title, status: String::from("PENDING"), date: now } }}
正如您在前面的代码中看到的,我们导入表定义,由于我们要引用它。 然后,我们用标题和状态定义新项目,它们是字符串。 chrono crate 用于将我们的日期字段定义为 NaiveDateTime。 然后,我们利用diesel宏将表定义为属于“to_do”表中的该构造。 不要被这个定义利用引号的事实所迷惑。
如果我们不导入架构,运用程序将无法编译,由于它无法理解引用。 我们还添加了另一个diesel宏,声明我们许可利用 Insertable 标签将数据插入到数据库中。 如前所述,我们不会向该宏添加更多标签,由于我们只想让该构造插入数据。
我们还添加了一个新函数,使我们能够定义创建新构造的标准规则。 例如,我们只会创建待处理的新项目。 这降落了创建泼皮状态的风险。 如果我们想稍后扩展,新函数可以接管状态输入并通过匹配语句运行它,如果状态不是我们乐意接管的状态之一,则抛出错误。 我们还自动声嫡期字段是我们创建项目的日期。
考虑到这一点,我们可以利用以下代码在 item.rs 文件中定义项目数据模型:
use crate::schema::to_do;use chrono::NaiveDateTime;#[derive(Queryable, Identifiable)]#[table_name="to_do"]pub struct Item { pub id: i32, pub title: String, pub status: String, pub date: NaiveDateTime}
正如您在前面的代码中看到的,NewItem 和 Item 构造之间的唯一差异是我们没有布局函数; 我们已将 Insertable 标签更换为 Queryable 和 Identificable,并且在构造中添加了一个 id 字段。 为了使这些可供应用程序的别的部分利用,我们利用以下代码在 models/item/mod.rs 文件中定义它们:
pub mod new_item;pub mod item;
然后,在 models/mod.rs 文件中,我们利用以下代码将 item 模块公开给其他模块和 main.rs 文件:
pub mod item;
接下来,我们利用以下代码行在 main.rs 文件中定义模型的模块:
mod models;
现在我们可以在全体运用程序中访问我们的数据模型。 我们还锁定了读写数据库的行为。 接下来,我们可以连续导入这些数据模型并在我们的运用程序中利用它们。
从数据库获取数据与数据库交互时,可能须要一些韶光来习气我们的操作办法。 不同的工具关系映射器 (ORM) 和措辞有不同的特性。 虽然基本事理是相同的,但这些 ORM 的语法可能有很大差异。 因此,仅仅利用 ORM 计时就能让您变得更加自傲并办理更繁芜的问题。 我们可以从最大略的机制开始,从表中获取所有数据。
为了探索这一点,我们可以从 to_do 表中获取所有项目,并在每个视图的末端返回它们。 我们在第 4 章“处理 HTTP 要求”中定义了这种机制。 就我们的运用程序而言,您会记得我们有一个 get_state 函数,它为我们的前端打包待办事项。 此 get_state 函数位于 src/json_serialization/to_do_items.rs 文件中的 ToDoItems 构造中。 首先,我们必须利用以下代码导入我们须要的内容:
use crate::diesel;use diesel::prelude::;use crate::database::establish_connection;use crate::models::item::item::Item;use crate::schema::to_do;
在前面的代码中,我们导入了diesel crate和宏,这使我们能够构建数据库查询。 然后,我们导入建立连接函数以建立与数据库的连接,然后导入架构和数据库模型以进行查询和处理数据。 然后我们可以利用以下代码重构 get_state 函数:
pub fn get_state() -> ToDoItems { let connection = establish_connection(); let mut array_buffer = Vec::new(); let items = to_do::table .order(to_do::columns::id.asc()) .load::<Item>(&connection).unwrap(); for item in items { let status = TaskStatus::new(&item.status.as_str()); let item = to_do_factory(&item.title, status); array_buffer.push(item); } return ToDoItems::new(array_buffer)}
在前面的代码中,我们首先建立连接。 建立数据库连接后,我们将获取表并根据它构建数据库查询。 查询的第一部分定义顺序。 正如我们所看到的,我们的表还可以通报对也有自己的功能的列的引用。
然后,我们定义将利用什么构造来加载数据并传入对连接的引用。 由于宏在加载中定义了却构,以是如果我们将 NewItem 构造通报到加载函数中,我们会收到缺点,由于该构造未启用 Queryable 宏。
还可以把稳到,load 函数在 load::<Item>(&connection) 中通报参数的函数括号之前有一个前缀。 这个前缀观点已在第 1 章“Rust 快速简介”“利用特色验证”部分的第 4 步中先容过,但现在,您可以利用以下代码:
fn some_function<T: SomeType>(some_input: &T) -> () { . . .}
通报到前缀 <Item> 的类型定义接管的输入类型。 这意味着当编译器运行时,将为通报给加载函数的每种类型编译一个单独的函数。
然后,我们直接解包加载函数,从而得到数据库中的项目向量。 利用数据库中的数据,我们循环构建项目构造并将它们附加到缓冲区。 完成此操作后,我们从缓冲区布局 ToDoItems JSON 模式并返回它。 现在我们已经履行了此变动,我们的所有视图都将直接从数据库返回数据。 如果我们运行它,将不会显示任何项目。 如果我们考试测验创建任何东西,它们将不会涌现。 然而,虽然它们没有被显示出来,但我们所做的便是从数据库中获取数据并将其序列化为我们想要的 JSON 构造。 这是从数据库返回数据并以标准办法返回给要求者的根本。 这是 Rust 构建的 API 的支柱。 由于从数据库获取项目时我们不再依赖于读取 JSON 状态文件,以是我们可以从 src/json_serialization/to_do_items.rs 文件中删除以下导入:
use crate::state::read_file;use serde_json::value::Value;use serde_json::Map;
我们删除了前面的导入,由于我们没有重构任何其他端点。 结果,创建端点将精确触发; 但是,端点只是在 JSON 状态文件中创建 return_state 不再读取的项目。 为了再次启用创建,我们必须重构创建端点以将新项目插入数据库。
插入数据库在本节中,我们将构建并创建一个用于创建待办事项的视图。 如果我们记住创建待办事项的规则,我们就不想创建重复的待办事项。 这可以通过唯一约束来完成。 然而,就目前而言,保持大略是有好处的。 相反,我们将利用基于通报到视图中的标题的过滤器来创建数据库。 然后我们检讨,如果没有返回结果,我们将在数据库中插入一个新的待办事项。 我们通过重构views/to_do/create.rs 文件中的代码来做到这一点。 首先,我们重新配置导入,如以下代码所示:
use crate::diesel;use diesel::prelude::;use actix_web::HttpResponse;use actix_web::HttpRequest;use crate::json_serialization::to_do_items::ToDoItems;use crate::database::establish_connection;use crate::models::item::new_item::NewItem;use crate::models::item::item::Item;use crate::schema::to_do;
在前面的代码中,我们导入必要的柴油入口以进行上一节中所述的查询。 然后,我们导入视图处理要求并定义结果所需的 actix-web 构造。 然后,我们导入数据库构造和函数以与数据库交互。 现在我们已经拥有了统统,我们可以开始创建视图了。 在我们的 pub async fn create 函数中,我们首先从要求中获取待办事项标题的两个引用:
pub async fn create(req: HttpRequest) -> HttpResponse { let title: String = req.match_info().get("title" ).unwrap().to_string(); . . .}
一旦我们从前面的代码中的 URL 中提取了标题,我们就会建立一个数据库连接,并利用该连接对我们的表进行数据库调用,如以下代码所示:
let connection = establish_connection();let items = to_do::table .filter(to_do::columns::title.eq(&title.as_str())) .order(to_do::columns::id.asc()) .load::<Item>(&connection) .unwrap();
正如我们在前面的代码中看到的,该查询与上一节中的查询险些相同。 但是,我们有一个过滤器部分引用我们的标题列,该列必须即是我们的标题。 如果正在创建的项目确实是新的,则不会创建任何项目; 因此,结果的长度将为零。 随后,如果长度为零,我们该当创建一个 NewItem 数据模型,然后将其插入数据库以返回函数末端的状态,如以下代码所示:
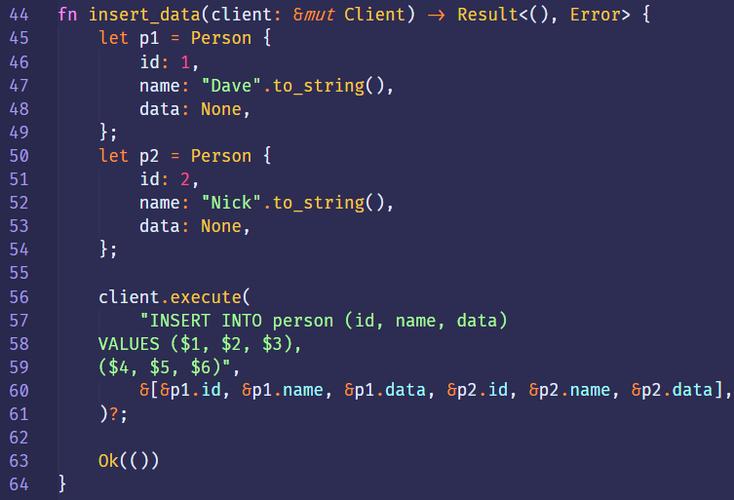
if items.len() == 0 { let new_post = NewItem::new(title); let _ = diesel::insert_into(to_do::table).values(&new_post) .execute(&connection);}return HttpResponse::Ok().json(ToDoItems::get_state())
我们可以看到 Diesel 有一个插入函数,它接管表以及对我们构建的数据模型的引用。 由于我们已经切换到数据库存储,以是我们可以删除以下不须要的导入:
use serde_json::value::Value;use serde_json::Map;use crate::state::read_file;use crate::processes::process_input;use crate::to_do::{to_do_factory, enums::TaskStatus};
现在,利用我们的运用程序,我们将能够创建待办事项,然后看到这些项目在运用程序的前端弹出。 因此,我们可以看到我们的创建和获取状态函数正在事情; 他们正在利用我们的数据库。 如果您碰着麻烦,一个常见的缺点是忘却启动我们的 docker-compose。 (把稳:请记住实行此操作,否则运用程序将无法连接到数据库,由于它未运行)。 但是,我们无法将待办事项状态编辑为“完成”。 为此,我们必须编辑数据库中的数据。
编辑数据库当我们编辑数据时,我们将从数据库获取数据模型,然后利用 Diesel 的数据库调用函数编辑条款。 为了将我们的编辑功能与数据库结合起来,我们可以在views/to_do/edit.rs 文件中编辑我们的视图。 我们首先重构导入,如以下代码所示:
use crate::diesel;use diesel::prelude::;use actix_web::{web, HttpResponse};use crate::json_serialization::{to_do_item::ToDoItem, to_do_items::ToDoItems};use crate::jwt::JwToken;use crate::database::establish_connection;use crate::schema::to_do;
正如我们在前面的代码中看到的,涌现了一种模式。 该模式是我们导入依赖项来处理身份验证、数据库连接和模式,然后构建一个实行我们想要的操作的函数。 我们之前已经先容了导入及其背后的含义。 在我们的编辑视图中,这次我们只能获取对标题的一个引用,如以下代码所示:
pub async fn edit(to_do_item: web::Json<ToDoItem>, token: JwToken) -> HttpResponse { let connection = establish_connection(); let results = to_do::table.filter(to_do::columns::title .eq(&to_do_item.title)); let _ = diesel::update(results) .set(to_do::columns::status.eq("DONE")) .execute(&connection); return HttpResponse::Ok().json(ToDoItems::get_state())}
在前面的代码中,我们可以看到我们在数据库上实行了过滤器而没有加载数据。 这意味着 results 变量是一个 UpdateStatement 构造。 然后,我们利用此 UpdateStatement 构造将数据库中的项目更新为 DONE。 由于我们不再利用 JSON 文件,我们可以删除views/to_do/edit.rs 文件中的以下导入:
use crate::processes::process_input;use crate::to_do::{to_do_factory, enums::TaskStatus};use serde_json::value::Value;use serde_json::Map;use crate::state::read_file;
在前面的代码中,我们可以看到我们调用了更新函数并用从数据库获取的结果添补它。 然后,我们将状态列设置为“完成”,然后利用对连接的引用实行。 现在我们可以利用它来编辑我们的待办事项,以便它们转移到已完成列表。 但是,我们无法删除它们。 为此,我们必须重构终极端点,以完备重构我们的运用程序以连接到数据库。
删除数据删除数据时,我们将采取与上一节编辑时相同的方法。 我们将从数据库中获取一个项目,将其通报给 Diesel 删除函数,然后返回状态。 现在,我们该当对这种方法感到满意,因此建议您考试测验在views/to_do/delete.rs 文件中自己实现它。 导入的代码如下:
use crate::diesel;use diesel::prelude::;use actix_web::{web, HttpResponse};use crate::database::establish_connection;use crate::schema::to_do;use crate::json_serialization::{to_do_item::ToDoItem, to_do_items::ToDoItems};use crate::jwt::JwToken;use crate::models::item::item::Item;
在前面的代码中,我们依赖于 Diesel crates 和 prelude,因此我们可以利用 Diesel 宏。 如果没有前奏,我们将无法利用该模式。 然后,我们导入将数据返回给客户端所需的 Actix Web 构造。 然后,我们导入为管理待办事项数据而构建的包。 对付删除功能,代码如下:
pub async fn delete(to_do_item: web::Json<ToDoItem>, token: JwToken) -> HttpResponse { let connection = establish_connection(); let items = to_do::table .filter(to_do::columns::title.eq( &to_do_item.title.as_str())) .order(to_do::columns::id.asc()) .load::<Item>(&connection) .unwrap(); let _ = diesel::delete(&items[0]).execute(&connection); return HttpResponse::Ok().json(ToDoItems::get_state())}
为了进行质量掌握,让我们实行以下步骤:
在文本输入中输入 buy canoe,然后单击“创建”按钮。
在文本输入中输入“go Dragon Boat racing”,然后单击“创建”按钮。
单击购买独木舟项目上的编辑按钮。 完成此操作后,我们该当在前端有以下输出:
图 6.6 – 预期输出
上图中,我们已经买了独木舟,但是还没有去赛龙舟。 现在我们已经看到了,我们的运用程序正在与 PostgreSQL 数据库无缝协作。 我们可以创建、编辑和删除我们的待办事项。 由于前面章节中定义的构造,删除数据库的 JSON 文件机制不须要做很多事情。 处理和返回数据的要求已经到位。 当我们现在运行我们的运用程序时,您可能已经意识到编译时我们有以下打印输出:
warning: function is never used: `read_file` --> src/state.rs:17:8 |17 | pub fn read_file(file_name: &str) -> Map<String, Value> {. . .warning: function is never used: `process_pending` --> src/processes.rs:18:4 |18 | fn process_pending(item: Pending, command: String, state: &Map<String, Value>) {
根据前面的打印输出,发生的情形是我们不再利用 src/state.rs 文件或 src/processes.rs 文件。 这些文件不再被利用,由于我们的 src/database.rs 文件现在正在利用真实数据库管理持久数据的存储、删除和编辑。 我们还利用已实现 Diesel 可查询和可识别特色的数据库模型构造将数据从数据库处理为构造。 因此,我们可以删除 src/state.rs 和 src/database.rs 文件,由于它们不再须要。 我们也不须要 src/to_do/traits 模块,因此也可以将其删除。 接下来,我们可以删除所有对特色的引用。 删除引用实质上意味着从 src/to_do/mod.rs 文件中删除特色,并在 to_do 模块的构造中删除这些特色的导入和实现。 例如,要从 src/to_do/structs/pending.rs 文件中删除特色,我们只需删除以下导入:
use super::super::traits::get::Get;use super::super::traits::edit::Edit;use super::super::traits::create::Create;
然后我们可以删除这些特色的以下实现:
impl Get for Pending {}impl Edit for Pending {}impl Create for Pending {}
我们还必须删除 src/to_do/structs/done.rs 文件中的特色。 我们现在有机会欣赏我们构造良好的隔离代码的回报。 我们可以轻松地插入不同的持久存储方法,由于我们可以通过直接删除几个文件和特色来大略地删除现有的存储方法。 然后我们删除了特色的实现。 便是这样。 我们不必深入研究函数并变动代码行。 由于我们的读取功能位于特色中,以是仅通过删除特色的实现来删除实现就完备割断了我们的运用程序。 像这样构建代码在未来确实会有回报。 过去,在重构微做事或升级或切换方法(例如存储选项)时,我必须将代码从一台做事器拉到另一台做事器中。 独立的代码使重构变得更加随意马虎、更快并且更不随意马虎出错。
我们的运用程序现在可以完备利用数据库。 但是,我们可以改进数据库的履行。 然而,在实行此操作之前,我们该当不才一节中重构我们的配置代码。
配置我们的运用程序现在,我们将数据库 URL 存储在 .env 文件中。 这很好,但我们也可以利用 yaml 配置文件。 在开拓Web做事器时,它们会运行在不同的环境中。 例如,现在我们正在本地打算机上运行 Rust 做事器。 不过,稍后我们会将做事器打包成我们自己的 Docker 镜像并支配到云端。 通过微做事根本举动步伐,我们可以利用在一个集群中构建的做事器,并将其插入具有不同数据库的不同集群中以连接。 因此,定义所有传入和传出流量的配置文件变得至关主要。 当我们支配做事器时,我们可以向文件存储(例如AWS S3)发出要求,以获取做事器的精确配置文件。
必须把稳的是,环境变量可以优先用于支配,由于它们可以通报到容器中。 我们将在第 13 章“清洁 Web 运用程序存储库的最佳实践”中先容如何利用环境变量配置 Web 运用程序。 现在,我们将重点关注利用配置文件。 我们还须要使我们的做事器能够灵巧地加载配置文件。 例如,我们不必在特定目录中具有特定名称的配置文件才能加载到我们的做事器中。 我们该当为精确的高下文精确命名我们的配置文件,以减少将缺点的配置文件加载到做事器中的风险。 我们的文件路径可以在启动做事器时通报。 由于我们利用的是 yaml 文件,以是我们须要定义 Cargo.toml 文件的 serde_yaml 依赖项,如下所示:
serde_yaml = "0.8.23"
现在我们可以读取 yaml 文件,我们可以构建自己的配置模块,它将 yaml 文件值加载到 HashMap 中。 这可以用一个构造来完成; 因此,我们该当将配置模块放入一个文件中,即 src/config.rs 文件。 首先,我们利用以下代码导入我们须要的内容:
use std::collections::HashMap;use std::env;use serde_yaml;
在前面的代码中,我们利用 env 捕获通报到程序中的环境变量,利用 HashMap 存储配置文件中的数据,并利用 serde_yaml crate 处理配置文件中的 yaml 值。 然后,我们利用以下代码定义容纳配置数据的构造:
pub struct Config { pub map: HashMap<String, serde_yaml::Value>}
在上面的代码中,我们可以看到我们的值的数据键是String,而属于这些键的值是yaml值。 然后,我们为构造体构建一个布局函数,该布局函数接管通报到程序中的末了一个参数,根据通报到程序中的文件的路径打开文件,并利用以下代码利用文件中的数据加载我们的映射字段:
impl Config { pub fn new() -> Config { let args: Vec<String> = env::args().collect(); let file_path = &args[args.len() - 1]; let file = std::fs::File::open(file_path).unwrap(); let map: HashMap<String, serde_yaml::Value> = serde_yaml:: from_reader(file).unwrap(); return Config{map} }}
现在已经定义了配置构造,我们可以利用以下代码行在 src/main.rs 文件中定义我们的配置模块:
mod config;
然后,我们必须重构 src/database.rs 文件以从 yaml 配置文件加载。 我们重构的导入采取以下形式:
use diesel::prelude::;use diesel::pg::PgConnection;use crate::config::Config;
我们可以看到所有对 env 的引用都已被删除,由于现在这是在我们的配置模块中处理的。 然后,我们加载文件,获取 DB_URL 键,并直接解包获取与 DB_URL 键关联的变量的结果,将 yaml 值转换为字符串,并直接解包该转换的结果。 我们直接解开获取和转换函数,由于如果它们失落败,我们将无法连接到数据库。 如果无法连接,我们希望尽快理解缺点,并供应清晰的缺点,显示发生缺点的位置。 现在,我们可以将数据库 URL 转移到 Rust 运用程序根目录中的 config.yml 文件中,个中包含以下内容:
DB_URL: postgres://username:password@localhost:5433/to_do
接下来,我们可以利用以下命令运行我们的运用程序:
cargo run config.yml
config.yml 文件是配置文件的路径。 如果运行 docker-compose 和前端,您将看到配置文件中的数据库 URL 正在加载,并且我们的运用程序已连接到数据库。 然而,此数据库连接有一个问题。 每次实行建立连接函数时,我们都会与数据库建立连接。 这会起浸染; 然而,这并不是最佳的。 不才一节中,我们将通过数据库连接池提高数据库连接的效率。
构建数据库连接池在本节中,我们将创建一个数据库连接池。 数据库连接池是有限数量的数据库连接。 当我们的运用程序须要数据库连接时,它会从池中取出连接,并在运用程序不再须要该连接时将其放回池中。 如果池中没有剩余连接,运用程序将等待,直到有可用连接,如下图所示:
图 6.7 – 限定三个连接的数据库连接池
在重构数据库连接之前,我们须要在 Cargo.toml 文件中安装以下依赖项:
lazy_static = "1.4.0"
然后,我们利用以下代码利用 src/database.rs 文件定义导入:
use actix_web::dev::Payload;use actix_web::error::ErrorServiceUnavailable;use actix_web::{Error, FromRequest, HttpRequest};use futures::future::{Ready, ok, err};use lazy_static::lazy_static;use diesel::{ r2d2::{Pool, ConnectionManager, PooledConnection}, pg::PgConnection,};use crate::config::Config;
根据我们在前面的代码中定义的导入,您认为当我们写出新的数据库连接时我们会做什么? 此时,是停下来思考可以用这些导入做什么的好机遇。
如果您还记得的话,第一个导入块将用于在要求到达视图之前建立数据库连接。 第二个导入块使我们能够定义数据库连接池。 末了一个 Config 参数是获取连接的数据库 URL。 现在我们的导入已经完成,我们可以利用以下代码定义连接池构造:
type PgPool = Pool<ConnectionManager<PgConnection>>;pub struct DbConnection { pub db_connection: PgPool,}
在前面的代码中,我们声明 PgPool 构造是一个连接管理器,用于管理池内的连接。 然后,我们利用以下代码构建静态引用连接:
lazy_static! { pub static ref DBCONNECTION: DbConnection = { let connection_string = Config::new().map.get("DB_URL").unwrap() .as_str().unwrap().to_string(); DbConnection { db_connection: PgPool::builder().max_size(8) .build(ConnectionManager::new(connection_string)) .expect("failed to create db connection_pool") } };}
在前面的代码中,我们从配置文件中获取 URL 并布局一个返回的连接池,从而将其分配给 DBCONNECTION 静态引用变量。 由于这是一个静态引用,以是 DBCONNECTION 变量的生命周期与做事器的生命周期相匹配。 现在,我们可以利用以下代码重构建立_连接函数以从数据库连接池中获取:
pub fn establish_connection() -> PooledConnection<ConnectionManager<PgConnection>>{ return DBCONNECTION.db_connection.get().unwrap()}
在前面的代码中,我们可以看到我们返回了一个 PooledConnection 构造。 但是,我们不想每次须要时都调用建立连接函数。 如果由于某种缘故原由无法建立连接,我们还希望在 HTTP 要求到达视图之前谢绝它,由于我们不想加载无法处理的视图。 就像我们的 JWToken 构造一样,我们可以创建一个构造来创建数据库连接并将该数据库连接通报到视图中。 我们的构造体有一个字段,它是一个池化连接,如下所示:
pub struct DB { pub connection: PooledConnection<ConnectionManager<PgConnection>>}
通过这个 DB 构造,我们可以像利用 JWToken 构造一样实现 FromRequest 特色,代码如下:
impl FromRequest for DB { type Error = Error; type Future = Ready<Result<DB, Error>>; fn from_request(_: &HttpRequest, _: &mut Payload) -> Self::Future{ match DBCONNECTION.db_connection.get() { Ok(connection) => { return ok(DB{connection}) }, Err(_) => { return err(ErrorServiceUnavailable( "could not make connection to database")) } } }}
这里我们不直接解包获取数据库连接。 相反,如果连接时涌现缺点,我们会返回缺点并附带有用的。 如果我们的连接成功,我们就会返回它。 我们可以按照我们的想法来实现这一点。 为了避免重复的代码,我们将只利用编辑视图,但我们该当将此方法运用于所有视图。 首先,我们定义以下导入:
use crate::diesel;use diesel::prelude::;use actix_web::{web, HttpResponse};use crate::json_serialization::{to_do_item::ToDoItem, to_do_items::ToDoItems};use crate::jwt::JwToken;use crate::schema::to_do;use crate::database::DB;
在前面的代码中,我们可以看到我们已经导入了DB构造。 我们的编辑视图现在应如下所示:
pub async fn edit(to_do_item: web::Json<ToDoItem>, token: JwToken, db: DB) -> HttpResponse { let results = to_do::table.filter(to_do::columns::title .eq(&to_do_item.title)); let _ = diesel::update(results) .set(to_do::columns::status.eq("DONE")) .execute(&db.connection); return HttpResponse::Ok().json(ToDoItems::get_state())}
在前面的代码中,我们可以看到我们直接引用了数据库构造的连接字段。 事实上,我们可以通过将数据库构造(如身份验证令牌)通报到视图中来大略地将池连接获取到我们的视图中。
概括在本章中,我们构建了一个开拓环境,我们的运用程序可以利用 Docker 与数据库进行交互。 完成此操作后,我们探索了容器和映像的列表,以检讨我们的系统的运行情形。 然后我们利用柴油箱创建了迁移。 之后,我们安装了diesel客户端并将数据库URL定义为环境变量,以便我们的Rust运用程序和迁移可以直接与数据库容器连接。
然后,我们运行迁移并定义在迁移运行时将触发的 SQL 脚本,然后运行它们。 完成所有这些后,我们再次检讨数据库容器以查看迁移是否确实已实行。 然后,我们在 Rust 中定义了数据模型,并重构了 API 端点,以便它们在数据库上实行获取、编辑、创建和删除操作,以跟踪待办事项。
我们在这里所做的是升级我们的数据库存储系统。 我们间隔拥有可投入生产的系统又近了一步,由于我们不再依赖 JSON 文件来存储数据。 您现在已经具备实行数据库管理任务的技能,这些任务使您能够管理变动、凭据/访问和架构。 我们还对数据库实行了运行创建、获取、更新和删除数据的运用程序所需的所有基本操作。 这些技能可以直接转移到您希望在 Rust Web 项目中进行的任何其他项目。 然后,我们通过使数据库连接受到连接池的限定来增强我们新开拓的数据库技能。 末了,通过实现 FromRequest 特色,可以轻松实现我们的数据库连接构造,因此其他开拓职员只需将构做作为参数通报到视图中即可实现我们的连接。 如果无法建立数据库连接,视图也会受到保护。
不才一章中,我们将基于这些技能来构建用户身份验证系统,以便我们可以创建用户并在访问运用程序时检讨凭据。 我们将利用数据库、从标题中提取数据、浏览器存储和路由的组合来确保用户必须登录才能访问待办事项。
问题与 JSON 文件比较,数据库有哪些优点?
如何创建迁移?
我们如何检讨迁移?
如果我们想在 Rust 中创建一个包含姓名和年事的用户数据模型,我们该当做什么?
什么是连接池,为什么要利用它?
答案该数据库在同时进行多个读写方面具有上风。 数据库还会在插入数据之前检讨数据以查看其格式是否精确,并且我们可以利用链接表进行高等查询。
我们安装diesel客户端并在.env文件中定义数据库URL。 然后,我们利用客户端创建迁移并编写迁移所需的架构。 然后我们运行迁移。
我们利用数据库的容器ID来访问容器。 然后我们列出表格; 如果我们想要的表存在,那么这便是迁移已运行的标志。 我们还可以检讨数据库中的迁移表来查看它上次运行的韶光。
我们定义一个 NewUser 构造体,名称为字符串,年事为整数。 然后,我们创建一个具有相同字段和一个额外整数字段(ID)的 User 构造。
连接池搜集了连接到数据库的有限数量的连接。 然后,我们的运用程序将这些连接通报给须要它们的线程。 这可以限定连接到数据库的连接数量,以避免数据库过载。















