学习目标:
节制mysql分库分表思想办理分库分表带来的问题根据实际项目运用处景选择适宜的分库分表策略为什么要分库分表当利用 MySQL数据库的时候,单表超出了2000万数据量就会涌现性能上的分水岭。
并且物理做事器的CPU、内存、存储、连接数等资源有限,某个时段大量连接同时实行操作,会导致数据库在处理上碰着性能瓶颈。
(图片来自网络侵删)为理解决这个问题,对大表进行分割,然后履行更好的掌握和管理,同时利用多台机器的CPU、内存、存储,供应更好的性能。
实现办法: 垂直拆分和 水平拆分。
垂直分库根据一个别系中的不同业务进行拆分
比如用户User一个库,商品Producet一个库,订单Order一个库。
切分后,一样平常要放在多个做事器上,而不是一个做事器上。
分库的紧张目的是办理单台mysql做事器性能瓶颈,放在一个做事器没有多大意义。
垂直分库如下图:
将原来的一个数据库根据业务拆分成多个数据库
垂直分库
如果把业务切割得足够独立,那把不同业务的数据放到不同的数据库做事器将是一个不错的方案。而且万一个中一个业务崩溃了也不会影响其他业务的正常进行,并且也起到了负载分流的浸染,大大提升了单机数据库的吞吐能力分区办法,也不能办理单张表数据量暴涨的问题但随着业务量的增大。
垂直分库也不能办理单库数据量暴涨的问题。比如users数据库,用户量打破千万,这时候,垂直分库的办法也就无能为力的。这时候就须要再进行水平分库,进行水平扩展。
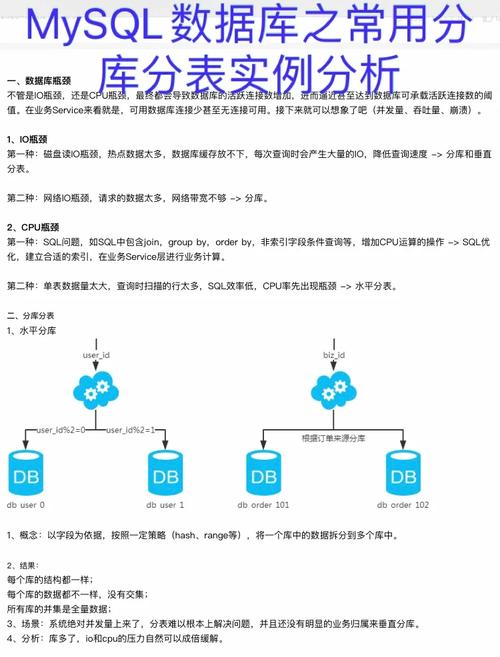
水平分库将数据库中单张表的数据切分到多个做事器上去,每个做事用具有相应的库与表,只是表中数据凑集不同。水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,打破IO、连接数、硬件资源等的瓶颈。可以水平扩展。
水平分库办法:
以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
水平分库结果:
每个库的构造都一样;每个库的数据都不一样,没有交集;所有库的并集是全量数据;比如用户库按用户id范围分库,
将用户id在1-1000000的分到数据库db_user_0,
1000001-2000000分到数据库db_user_1,
2000001-3000000分到数据库db_user_2等等
分库顺序一样平常是先根据业务细分进行垂直分库,然后再进行水平分库。
垂直分表也便是“大表拆小表”,基于列字段进行的。
一样平常是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一样平常是针对那种几百列的大表,也避免查询时,数据量太大造成的“跨页”问题。
比如常常用到的将goods表拆分成goods表和goods_details表
垂直分表同垂直分库一样,会涌现单表变大的情形,这时候须要利用水平分表策略
水平分表观点:
以 字段为依据 ,按照一定策略(hash、range等),将一个 表中的数据拆分到多个 表中。
结果:
每个表的构造都一样;每个表的数据都不一样,没有交集;所有表的并集是全量数据;场景系统绝对并发量并没有上来,只是单表的数据量太多,影响了SQL效率,加重了CPU包袱,以至于成为瓶颈。剖析表的数据量少了,单次SQL实行效率高,自然减轻了CPU的包袱。
分库分表工具分布式数据库中间件分为两种,proxy和客户端式架构。
proxy模式有 MyCat、DBProxy等
客户端式架构有TDDL、 Sharding-JDBC等。
那么proxy和客户端式架构有何差异呢?各自有什么优缺陷呢?
proxy模式
我们的select和update语句都是发送给代理,由这个代理来操作详细的底层数据库。以是必须哀求代理本身须要担保高可用,否则数据库没有宕机,proxy挂了,那就走远了。
客户端模式
常日在连接池上做了一层封装,内部与不同的库连接,sql交给smart-client进行处理。常日仅支持一种措辞,如果其他措辞要利用,须要开拓多措辞客户端。
各自的优缺陷如下:
分库分表步骤
根据容量(当前容量和增长量)评估分库或分表个数 -> 选key(均匀)-> 分表规则(hash或range等)-> 实行(一样平常双写)-> 扩容问题(只管即便减少数据的移动)
分库分表问题以及办理办法1.非partition key的查讯问题(水平分库分表,拆分策略为常用的hash法)除了partition key只有一个非partition key作为条件查询映射法
基因法
注:写入时,基因法天生user_id,如图。
关于xbit基因,例如要分8张表,2 3=8,故x取3,即3bit基因。
根据user_id查询时可直接取模路由到对应的分库或分表。
根据user_name查询时,先通过user_name_code天生函数天生user_name_code
再对其取模路由到对应的分库或分表。
id天生常用 snowflake算法。
1.除了partition key不止一个非partition key作为条件查询
映射法
冗余法
注:按照order_id或buyer_id查询时路由到db_o_buyer库中,按照seller_id查询时路由到db_o_seller库中。
2.后台除了partition key还有各种非partition key组合条件查询
NoSQL法
冗余法
分库分表总结分库分表,首先得知道瓶颈在哪里,然后才能合理地拆分
(分库还是分表?水平还是垂直?分几个?),且不可为了分库分表而拆分。
选key很主要,既要考虑到拆分均匀,也要考虑到非partition key的查询。只要能知足需求,拆分规则越大略越好。
php7进阶到架构师干系阅读https://www.kancloud.cn/gofor/gofor
末了,欢迎大家留言补充,谈论~~~