
不知道你们有没有这个觉得,看正则表达式就像看天文数字一样,什么电话号码、邮箱的正则表达式,上网复制一下粘贴下来就搞定了。完备不知道这写的是什么玩意。几个月没用创造一些不常用标识都忘了!
好了,废话不多说,开始搞事情。
标识一个正则表达式的开始和结束,用'/'或'#'或'{ }',由于语法'{ }'也可能是正则表达式的运算符,为了避免稠浊,以是不建议利用。建议的用法如下:

$pattern = '/[0-9]/'; //我喜好这个,看起来比较简洁 $pattern = '#[0-9]#';原子:#
可见原子:Unicode编码表中可用键盘输出后肉眼可见的字符,例如:标点 ; . / ? 或者英笔墨母,汉字等等可见字符不可见原子:Unicode编码表中可用键盘输出后肉眼不可见的字符,例如:换行符 \n,Tab制表符\t, 空格等等,一样平常只用这三个(换行符一样平常和其他字符一起匹配,由于只有换行符是匹配不到的)小提示:匹配运算符前面须要加'\' 例如:'+' 号,匹配的话须要写出 '\+'
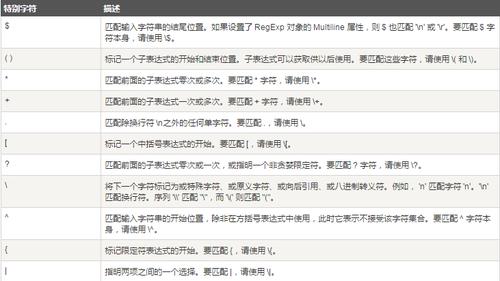
原子的筛选办法:
| 匹配两个或者多个分支选择[] 匹配方括号中的任意一个原子[^] 匹配除方括号中的原子之外的任意字符;例子:Duang|duang 或者 [Dd]uang 都可以匹配到Duang和duang区间写法:[a-z]匹配a到z的字符, [0-9]匹配0到9的字符。也可以[a-z0-9]. 匹配除换行符之外的任意字符\d 匹配任意一个十进制数字,即{0-9]\D 匹配任意一个非十进制数字[^0-9] 相称于[^\d]\s 匹配一个不可见的原子,即[\f\n\r\t\v]\S 匹配一个可见的原子,即[\f\n\r\t\v],相称于[\s]z\w 匹配任意一个数字、字母或下划线,即[0-9a-zA-Z_]\W 匹配任意一个非数字、字母或下划线,[0-9a-zA-Z_],相称于[\w]
量词#{n} 表示其前面的原子刚好涌现了n次。[n] 表示其前面的原子最少涌现n次{n,m} 最少涌现n次,最多涌现m次 匹配0次、一次或者多次,即{0,}+ 匹配一次或多次,即{1,}? 匹配0或1次,即{0,1}
边界掌握#^ 匹配字符串开始的位置$ 匹配字符串结尾的位置例:^John 可以匹配到:John 但是匹配不到:123John,由于规定了字符串以John开头
模式单元#() 匹配个中的整体为一个原子, 如: (X|x)iaomi , 可以匹配到 xiaomi
改动模式#贪婪匹配#匹配结果存在歧义时取其长(默认)
实行匹配正则表达式 preg_match ( string $pattern , string $subject [, array &$matches [, int $flags = 0 [, int $offset = 0 ]]] ) : int pattern: 要搜索的模式,字符串类型。subject:输入字符串。match: 如果供应了参数matches,它将被添补为搜索结果,数据构造为一维数组。flags: 可以设置为PREG_OFFSET_CAPTURE,利用搜索结果的第0个元素为匹配的字符串,第1个元素为对应的偏移量(位置)offset: 搜索从目标字符串的起始位置开始匹配。 返回值:匹配次数类似函数preg_match_all,参数与preg_match同等差异: preg_match:只匹配一次,搜索构造match的数据结果为一维数组preg_match_all:匹配全部,搜索结果match的数据构造为二维数组。 实行一个正则表达式搜索和更换,返回值为更换后的字符串 preg_replace ( mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count ]] ) : mixed pattern:要搜索的模式。可以是一个字符串或字符串数组。replacement:用于更换的字符串或字符串数组subject:要进行搜索和更换的字符串或字符串数组。limit:更换的最大次数。默认是 -1(无限)。count:更换次数。类似函数preg_filter,参数与preg_replace同等差异(利用数组进行匹配的时候才看得出差异):preg_replace:不管是否有更换,返回全部结果preg_filter:只返回匹配的结果。 通过一个正则表达式分隔字符串 preg_split ( string $pattern , string $subject [, int $limit = -1 [, int $flags = 0 ]] ) : array $pattrn:用于搜索的模式,字符串形式。subject:输入字符串limit:将限定分隔得到的子串最多只有limit个,返回的末了一个 子串将包含所有剩余部分。flags:有以下标记的组合:-- 1. PREG_SPLIT_NO_EMPTY: 返回分隔后的非空部分。-- 2. PREG_SPLIT_DELIM_CAPTURE: 用分隔符'()'括号把匹配的捕获并返回。-- 3. PREG_SPLIT_OFFSET_CAPTURE: 匹配返回时将会附加字符串偏移量 PREG_SPLIT_DELIM_CAPTURE这个参数可能比较难解白,举个例子看看: 输出如下: array (size=2)0 => string 'a' (length=1)1 => string 'b' (length=1)array (size=5)0 => string '1' (length=1)1 => string 'a' (length=1)2 => string '2' (length=1)3 => string '3' (length=1)4 => string 'b' (length=1) 返回匹配模式的数组条款 preg_grep ( string $pattern , array $input [, int $flags = 0 ] ) : array $pattern:要搜索的模式,字符串形式$input:输入数组flags:如果不设置则返回匹配的数目,设置PREG_GREP_INVERT则返回不匹配的数目。 转义正则表达式字符,返回为转义后的字符串 preg_quote ( string $str [, string $delimiter = NULL ] ) : string str:输入字符串delimiter:须要转义的字符串$subject = "test__123123123";preg_match('/test.+123/', $subject, $matches); //贪婪模式 var_dump($matches);preg_match('/test.+123/U', $subject, $matches); //常用函数#preg_match#$subject = "1a23b"; $a = preg_split('/[\d]/', $subject, -1, PREG_SPLIT_NO_EMPTY); var_dump($a); $a = preg_split('/([\d])/', $subject, -1, PREG_SPLIT_NO_EMPTY | PREG_SPLIT_DELIM_CAPTURE); var_dump($a);















