
mysql 优化
第一方面:30种mysql优化sql语句查询的方法
1.对查询进行优化,应只管即便避免全表扫描,首先应考虑在 where 及 order by涉及的列上建立索引。

2.应只管即便避免在 where 子句中利用 !=或<> 操作符,否则将引擎放弃利用索引而进行全表扫描。
3.应只管即便避免在 where 子句中对字段进行 null 值 判断,否则将导致引擎放弃利用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
4.应只管即便避免在 where 子句中利用 or 来连接条件,否则将导致引擎放弃利用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.下面的查询也将导致全表扫描: select id from t where name like '%abc%'
对付 like '..%' (不以 % 开头),可以运用 colunm上的index
6.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对付连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
7.如果在 where 子句中利用参数,也会导致全表扫描。由于SQL只有在运行时才会解析局部变量,但优化程序不能将访问操持的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问操持,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为逼迫查询利用索引:
select id from t with(index(索引名)) where num=@num
8.应只管即便避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃利用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=1002
9.应只管即便避免在where子句中对字段进行函数操作,这将导致引擎放弃利用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
select id from t where datediff(day,createdate,'2005-11-30')=0--'2005-11-30'天生的id
应改为:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
10.不要在 where 子句中的"="【左边】进行函数、算术运算或其他表达式运算,否则系统将可能无法精确利用索引。
11.在利用索引字段作为条件时,如果该索引是【复合索引】,那么必须利用到该索引中的【第一个字段】作为条件时才能担保系统利用该索引,否则该索引将不会被利用。并且应【尽可能】的让字段顺序与索引顺序相同等。(字段顺序也可以不与索引顺序同等,但是一定要包含【第一个字段】。)
12.不要写一些没故意义的查询,如须要天生一个空表构造:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会花费系统资源的,应改成这样:
create table #t(...)
13.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句更换:
select num from a where exists(select 1 from b where num=a.num)
14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female险些各一半,那么纵然在sex上建了索引也对查询效率起不了浸染。
15.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降落了 insert 及 update 的效率,由于 insert 或 update 时有可能会重修索引,以是若何建索引须要慎重考虑,视详细情形而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常利用到的列上建的索引是否有必要。
16.应尽可能的避免更新 clustered 索引数据列,由于 clustered 索引数据列的顺序便是表记录的物理存储顺序,一旦该列值改变将导致全体表记录的顺序的调度,会耗费相称大的资源。若运用系统须要频繁更新 clustered 索引数据列,那么须要考虑是否应将该索引建为 clustered 索引。
17.只管即便利用数字型字段,若只含数值信息的字段只管即便不要设计为字符型,这会降落查询和连接的性能,并会增加存储开销。这是由于引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对付数字型而言只须要比较一次就够了。
18.尽可能的利用 varchar/nvarchar 代替 char/nchar ,由于首先变长字段存储空间小,可以节省存储空间,其次对付查询来说,在一个相对较小的字段内搜索效率显然要高些。
19.任何地方都不要利用 select from t ,用具体的字段列表代替"",不要返回用不到的任何字段。
20.只管即便利用表变量来代替临时表。如果表变量包含大量数据,请把稳索引非常有限(只有主键索引)。
21.避免频繁创建和删除临时表,以减少系统表资源的花费。
22.临时表并不是不可利用,适当地利用它们可以使某些例程更有效,例如,当须要重复引用大型表或常用表中的某个数据集时。但是,对付一次性事宜,最好利用导出表。
23.在新建临时表时,如果一次性插入数据量很大,那么可以利用 select into 代替 create table,避免造成大量 log ,以提高速率;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24.如果利用到了临时表,在存储过程的末了务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较永劫光锁定。
25.只管即便避免利用游标,由于游标的效率较差,如果游标操作的数据超过1万行,那么就该当考虑改写。
26.利用基于游标的方法或临时表方法之前,应先探求基于集的办理方案来办理问题,基于集的方法常日更有效。
27.与临时表一样,游标并不是不可利用。对小型数据集利用 FAST_FORWARD 游标常日要优于其他逐行处理方法,尤其是在必须引用几个表才能得到所需的数据时。在结果集中包括"合计"的例程常日要比利用游标实行的速率快。如果开拓韶光许可,基于游标的方法和基于集的方法都可以考试测验一下,看哪一种方法的效果更好。
28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在实行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 。
29.只管即便避免向客户端返回大数据量,若数据量过大,该当考虑相应需求是否合理。
30.只管即便避免大事务操作,提高系统并发能力。
上面有几句写的有问题。
第二方面:
select Count ()和Select Count(1)以及Select Count(column)差异
一样平常情形下,Select Count ()和Select Count(1)两着返回结果是一样的
如果表沒有主键(Primary key), 那么count(1)比count()快,
如果有主键的話,那主键作为count的条件时候count(主键)最快
如果你的表只有一个字段的话那count()便是最快的
count() 跟 count(1) 的结果一样,都包括对NULL的统计,而count(column) 是不包括NULL的统计
第三方面:
索引列上打算引起的索引失落效及优化方法以及把稳事变
创建索引、优化查询以便达到更好的查询优化效果。但实际上,MySQL有时并不按我们设计的那样实行查询。MySQL是根据统计信息来天生实行操持的,这就涉及索引及索引的刷选率,表数据量,还有一些额外的成分。
Each table index is queried, and the best index is used unless the optimizer believes that it is more efficient to use a table scan. At one time, a scan was used based on whether the best index spanned more than 30% of the table, but a fixed percentage no longerdetermines the choice between using an index or a scan. The optimizer now is more complex and bases its estimate on additional factors such as table size, number of rows, and I/O block size.
简而言之,当MYSQL认为符合条件的记录在30%以上,它就不会再利用索引,由于mysql认为走索引的代价比不用索引代价大,以是优化器选择了自己认为代价最小的办法。事实也的确如此
是MYSQL认为记录是30%以上,而不是实际MYSQL去查完再决定的。都查完了,还用什么索引啊?!
MYSQL会先估算,然后决定是否利用索引。
----------------------------------------------------------------------------下--------------------------------------------------------
1. 如何设计一个高并发的系统
① 数据库的优化,包括合理的事务隔离级别、SQL语句优化、索引的优化
② 利用缓存,只管即便减少数据库 IO
③ 分布式数据库、分布式缓存
④ 做事器的负载均衡
2. 锁的优化策略
① 读写分离
② 分段加锁
③ 减少锁持有的韶光
④ 多个线程只管即便以相同的顺序去获取资源
等等,这些都不是绝对原则,都要根据情形,比如不能将锁的粒度过于细化,不然可能会涌现线程的加锁和开释次数过多,反而效率不如一次加一把大锁。这部分跟口试官谈了良久
3. 索引的底层实现事理和优化
B+树,经由优化的B+树
紧张是在所有的叶子结点中增加了指向下一个叶子节点的指针,因此InnoDB建议为大部分表利用默认自增的主键作为主索引。
4. 什么情形下设置了索引但无法利用
① 以"%"开头的LIKE语句,模糊匹配
② OR语句前后没有同时利用索引
③ 数据类型涌现隐式转化(如varchar不加单引号的话可能会自动转换为int型)
5. SQL语句的优化
order by要怎么处理
alter只管即便将多次合并为一次
insert和delete也须要合并
等等
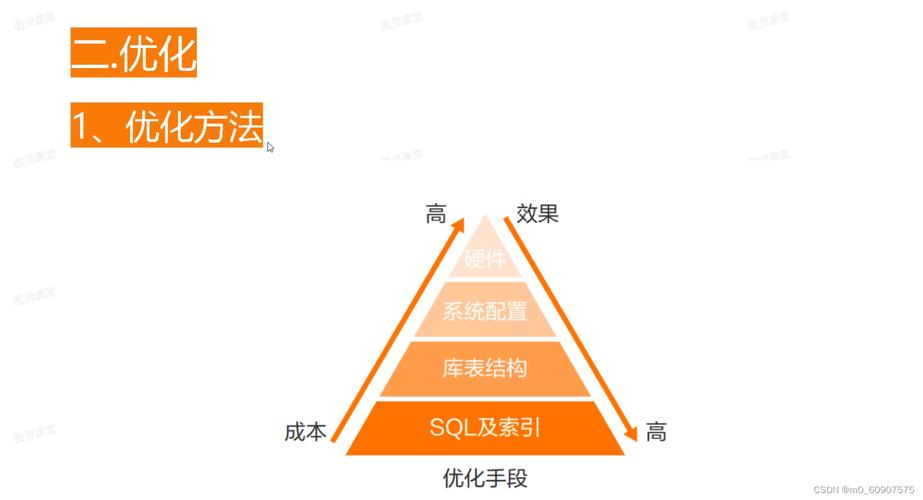
6. 实践中如何优化MySQL
我当时是按以下四条依次回答的,他们四条从效果上第一条影响最大,后面越来越小。
① SQL语句及索引的优化
② 数据库表构造的优化
③ 系统配置的优化
④ 硬件的优化
8. sql注入的紧张特点
变种极多,攻击大略,危害极大
9. sql注入的紧张危害
未经授权操作数据库的数据
恶意纂改网页
私自添加系统账号或者是数据库利用者账号
网页挂木马
11、优化数据库的方法
MySQL数据库优化的八大办法(经典必看)点击获取
· 选取最适用的字段属性,尽可能减少定义字段宽度,只管即便把字段设置NOTNULL,例如'省份'、'性别'最好适用ENUM
· 利用连接(JOIN)来代替子查询
· 适用联合(UNION)来代替手动创建的临时表
· 事务处理
· 锁定表、优化事务处理
· 适用外键,优化锁定表
· 建立索引
· 优化查询语句
19. 大略描述mysql中,索引,主键,唯一索引,联合索引的差异,对数据库的性能有什么影响(从读写两方面)(新浪网技能部)
索引是一种分外的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速率。普通索引许可被索引的数据列包含重复的值。如果能确定某个数据列将只包含彼此各不相同的值,在为这个数据列创建索引的时候就该当用关键字UNIQUE把它定义为一个唯一索引。也便是说,唯一索引可以担保数据记录的唯一性。主键,是一种分外的唯一索引,在一张表中只能定义一个主键索引,主键用于唯一标识一条记录,利用关键字 PRIMARY KEY 来创建。索引可以覆盖多个数据列,如像INDEX(columnA, columnB)索引,这便是联合索引。索引可以极大的提高数据的查询速率,但是会降落插入、删除、更新表的速率,由于在实行这些写操作时,还要操作索引文件。
20.数据库中的事务是什么?
事务(transaction)是作为一个单元的一组有序的数据库操作。如果组中的所有操作都成功,则认为事务成功,纵然只有一个操作失落败,事务也不堪利。如果所有操作完成,事务则提交,其修正将浸染于所有其他数据库进程。如果一个操作失落败,则事务将回滚,该事务所有操作的影响都将取消。ACID 四大特性,原子性、隔离性、同等性、持久性。
21.理解XSS攻击吗?如何防止?
XSS是跨站脚本攻击,首先是利用跨站脚本漏洞以一个特权模式去实行攻击者布局的脚本,然后利用不屈安的Activex控件实行恶意的行为。利用htmlspecialchars()函数对提交的内容进行过滤,使字符串里面的分外符号实体化。
22.SQL注入漏洞产生的缘故原由?如何防止?
SQL注入产生的缘故原由:程序开拓过程中不把稳规范书写sql语句和对分外字符进行过滤,导致客户端可以通过全局变量POST和GET提交一些sql语句正常实行。
防止SQL注入的办法:
开启配置文件中的magic_quotes_gpc 和 magic_quotes_runtime设置
实行sql语句时利用addslashes进行sql语句转换
Sql语句书写只管即便不要省略双引号和单引号。
过滤掉sql语句中的一些关键词:update、insert、delete、select、 。
提高数据库表和字段的命名技巧,对一些主要的字段根据程序的特点命名,取不易被猜到的。
Php配置文件中设置register_globals为off,关闭全局变量注册
掌握缺点信息,不要在浏览器上输出错误信息,将缺点信息写到日志文件中。
25、 对付关系型数据库而言,索引是相称主要的观点,请回答有关索引的几个问题:
a)、索引的目的是什么?
快速访问数据表中的特定信息,提高检索速率
创建唯一性索引,担保数据库表中每一行数据的唯一性。
加速表和表之间的连接
利用分组和排序子句进行数据检索时,可以显著减少查询等分组和排序的韶光
b)、索引对数据库系统的负面影响是什么?
负面影响:创建索引和掩护索引须要耗费韶光,这个韶光随着数据量的增加而增加;索引须要占用物理空间,不只是表须要占用数据空间,每个索引也须要占用物理空间;当对表进行增、删、改、的时候索引也要动态掩护,这样就降落了数据的掩护速率。
c)、为数据表建立索引的原则有哪些?
在最频繁利用的、用以缩小查询范围的字段上建立索引。
在频繁利用的、须要排序的字段上建立索引
d)、 什么情形下不宜建立索引?
对付查询中很少涉及的列或者重复值比较多的列,不宜建立索引。
对付一些分外的数据类型,不宜建立索引,比如文本字段(text)等
26、 简述在MySQL数据库中MyISAM和InnoDB的差异
差异于其他数据库的最主要的特点便是其插件式的表存储引擎。牢记:存储引擎是基于表的,而不是数据库。
InnoDB与MyISAM的差异:
InnoDB存储引擎: 紧张面向OLTP(Online Transaction Processing,在线事务处理)方面的运用,是第一个完全支持ACID事务的存储引擎(BDB第一个支持事务的存储引擎,已经停滞开拓)。
特点:
· 行锁设计、支持外键,支持事务,支持并发,锁粒度是支持mvcc得行级锁;
MyISAM存储引擎: 是MySQL官方供应的存储引擎,紧张面向OLAP(Online Analytical Processing,在线剖析处理)方面的运用。特点:
不支持事务,锁粒度是支持并发插入得表级锁,支持表所和全文索引。操作速率快,不能读写操作太频繁;
27、 阐明MySQL外连接、内连接与自连接的差异
先说什么是交叉连接: 交叉连接又叫笛卡尔积,它是指不该用任何条件,直接将一个表的所有记录和另一个表中的所有记录逐一匹配。
内连接 则是只有条件的交叉连接,根据某个条件筛选出符合条件的记录,不符合条件的记录不会涌如今结果集中,即内连接只连接匹配的行。外连接 其结果集中不仅包含符合连接条件的行,而且还会包括左表、右表或两个表中的所有数据行,这三种情形依次称之为左外连接,右外连接,和全外连接。
左外连接,也称左连接,左表为主表,左表中的所有记录都会涌如今结果集中,对付那些在右表中并没有匹配的记录,仍旧要显示,右边对应的那些字段值以NULL来添补。右外连接,也称右连接,右表为主表,右表中的所有记录都会涌如今结果集中。左连接和右连接可以互换,MySQL目前还不支持全外连接。
28、 写出三种以上MySQL数据库存储引擎的名称(提示:不区分大小写)
MyISAM、InnoDB、BDB(BerkeleyDB)、Merge、Memory(Heap)、Example、Federated、Archive、CSV、Blackhole、MaxDB 等等十几个引擎
33、Myql中的事务回滚机制概述
事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是一个不可分割的事情单位,事务回滚是指将该事务已经完成的对数据库的更新操作撤销。
要同时修正数据库中两个不同表时,如果它们不是一个事务的话,当第一个表修正完,可能第二个表修正过程中涌现了非常而没能修正,此时就只有第二个表依旧是未修正之前的状态,而第一个表已经被修正完毕。而当你把它们设定为一个事务的时候,当第一个表修正完,第二表修正涌现非常而没能修正,第一个表和第二个表都要回到未修正的状态,这便是所谓的事务回滚
2. SQL措辞包括哪几部分?每部分都有哪些操作关键字?
答:SQL措辞包括数据定义(DDL)、数据操纵(DML),数据掌握(DCL)和数据查询(DQL)四个部分。
数据定义:Create Table,Alter Table,Drop Table, Craete/Drop Index等
数据操纵:Select ,insert,update,delete,
数据掌握:grant,revoke
数据查询:select
3. 完全性约束包括哪些?
答:数据完全性(Data Integrity)是指数据的精确(Accuracy)和可靠性(Reliability)。
分为以下四类:
1) 实体完全性:规定表的每一行在表中是惟一的实体。
2) 域完全性:是指表中的列必须知足某种特定的数据类型约束,个中约束又包括取值范围、精度等规定。
3) 参照完全性:是指两个表的主关键字和外关键字的数据应同等,担保了表之间的数据的同等性,防止了数据丢失或无意义的数据在数据库中扩散。
4) 用户定义的完全性:不同的关系数据库系统根据其运用环境的不同,每每还须要一些分外的约束条件。用户定义的完全性即是针对某个特定关系数据库的约束条件,它反响某一详细运用必须知足的语义哀求。
与表有关的约束:包括列约束(NOT NULL(非空约束))和表约束(PRIMARY KEY、foreign key、check、UNIQUE) 。
4. 什么是事务?及其特性?
答:事务:是一系列的数据库操作,是数据库运用的基本逻辑单位。
事务特性:
(1)原子性:即不可分割性,事务要么全部被实行,要么就全部不被实行。
(2)同等性或可串性。事务的实行使得数据库从一种精确状态转换成另一种精确状态
(3)隔离性。在事务精确提交之前,不许可把该事务对数据的任何改变供应给任何其他事务,
(4) 持久性。事务精确提交后,其结果将永久保存在数据库中,纵然在事务提交后有了其他故障,事务的处理结果也会得到保存。
或者这样理解:
事务便是被绑定在一起作为一个逻辑事情单元的SQL语句分组,如果任何一个语句操作失落败那么全体操作就被失落败,往后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么实行,要么不实行,就可以利用事务。要将有组语句作为事务考虑,就须要通过ACID测试,即原子性,同等性,隔离性和持久性。
5. 什么是锁?
答:数据库是一个多用户利用的共享资源。当多个用户并发地存取数据时,在数据库中就会产生多个事务同时存取同一数据的情形。若对并发操作不加掌握就可能会读取和存储禁绝确的数据,毁坏数据库的同等性。
加锁是实现数据库并发掌握的一个非常主要的技能。当事务在对某个数据工具进行操作前,先向系统发出要求,对其加锁。加锁后事务就对该数据工具有了一定的掌握,在该事务开释锁之前,其他的事务不能对此数据工具进行更新操作。
基本锁类型:锁包括行级锁和表级锁
6. 什么叫视图?游标是什么?
答:视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,视图常日是有一个表或者多个表的行或列的子集。对视图的修正不影响基本表。它使得我们获取数据更随意马虎,比较多表查询。
游标:是对查询出来的结果集作为一个单元来有效的处理。游标可以定在该单元中的特定行,从结果集确当前行检索一行或多行。可以对结果集当前行做修正。一样平常不该用游标,但是须要逐条处理数据的时候,游标显得十分主要。
7. 什么是存储过程?用什么来调用?
答:存储过程是一个预编译的SQL语句,优点是许可模块化的设计,便是说只需创建一次,往后在该程序中就可以调用多次。如果某次操作须要实行多次SQL,利用存储过程比纯挚SQL语句实行要快。可以用一个命令工具来调用存储过程。
8. 索引的浸染?和它的优点缺陷是什么?
答:索引就一种分外的查询表,数据库的搜索引擎可以利用它加速对数据的检索。它很类似与现实生活中书的目录,不须要查询整本书内容就可以找到想要的数据。索引可以是唯一的,创建索引许可指定单个列或者是多个列。缺陷是它减慢了数据录入的速率,同时也增加了数据库的尺寸大小。
9. 如何普通地理解三个范式?
答:第一范式:1NF是对属性的原子性约束,哀求属性具有原子性,不可再分解;
第二范式:2NF是对记录的惟一性约束,哀求记录有惟一标识,即实体的惟一性;
第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它哀求字段没有冗余。。
范式化设计优缺陷:
优点:
可以只管即便得减少数据冗余,使得更新快,体积小
缺陷:对付查询须要多个表进行关联,减少写得效率增加读得效率,更难进行索引优化
反范式化:
优点:可以减少表得关联,可以更好得进行索引优化
缺陷:数据冗余以及数据非常,数据得修正须要更多的本钱
10. 什么是基本表?什么是视图?
答:基本表是本身独立存在的表,在 SQL 中一个关系就对应一个表。 视图是从一个或几个基本表导出的表。视图本身不独立存储在数据库中,是一个虚表
11. 试述视图的优点?
答:(1) 视图能够简化用户的操作 (2) 视图利用户能以多种角度看待同一数据; (3) 视图为数据库供应了一定程度的逻辑独立性; (4) 视图能够对机密数据供应安全保护。
12. NULL是什么意思
答:NULL这个值表示UNKNOWN(未知):它不表示""(空字符串)。对NULL这个值的任何比较都会生产一个NULL值。您不能把任何值与一个 NULL值进行比较,并在逻辑上希望得到一个答案。
利用IS NULL来进行NULL判断
13. 主键、外键和索引的差异?
主键、外键和索引的差异
定义:
主键--唯一标识一条记录,不能有重复的,不许可为空
外键--表的外键是另一表的主键, 外键可以有重复的, 可以是空值
索引--该字段没有重复值,但可以有一个空值
浸染:
主键--用来担保数据完全性
外键--用来和其他表建立联系用的
索引--是提高查询排序的速率
个数:
主键--主键只能有一个
外键--一个表可以有多个外键
索引--一个表可以有多个唯一索引
14. 你可以用什么来确保表格里的字段只接管特定例模里的值?
答:Check限定,它在数据库表格里被定义,用来限定输入该列的值。
触发器也可以被用来限定数据库表格里的字段能够接管的值,但是这种办法哀求触发器在表格里被定义,这可能会在某些情形下影响到性能。
15. 说说对SQL语句优化有哪些方法?(选择几条)
(1)Where子句中:where表之间的连接必须写在其他Where条件之前,那些可以过滤掉最大数量记录的条件必须写在Where子句的末端.HAVING末了。
(2)用EXISTS替代IN、用NOT EXISTS替代NOT IN。
(3) 避免在索引列上利用打算
(4)避免在索引列上利用IS NULL和IS NOT NULL
(5)对查询进行优化,应只管即便避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
(6)应只管即便避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃利用索引而进行全表扫描
(7)应只管即便避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃利用索引而进行全表扫描
16. SQL语句中'干系子查询'与'非干系子查询'有什么差异?
答:子查询:嵌套在其他查询中的查询称之。
子查询又称内部,而包含子查询的语句称之外部查询(又称主查询)。
所有的子查询可以分为两类,即干系子查询和非干系子查询
(1)非干系子查询是独立于外部查询的子查询,子查询统共实行一次,实行完毕后将值通报给外部查询。
(2)干系子查询的实行依赖于外部查询的数据,外部查询实行一行,子查询就实行一次。
故非干系子查询比干系子查询效率高
17. char和varchar的差异?
答:是一种固定长度的类型,varchar则是一种可变长度的类型,它们的差异是:
char(M)类型的数据列里,每个值都占用M个字节,如果某个长度小于M,MySQL就会在它的右边用空格字符补足.(在检索操作中那些补充出来的空格字符将被去掉)在varchar(M)类型的数据列里,每个值只占用刚好够用的字节再加上一个用来记录其长度的字节(即总长度为L+1字节).
varchar得适用场景:
字符串列得最大长度比均匀长度大很多 2.字符串很少被更新,随意马虎产生存储碎片 3.利用多字节字符集存储字符串
Char得场景:
存储具有近似得长度(md5值,身份证,手机号),长度比较短小得字符串(由于varchar须要额外空间记录字符串长度),更适宜常常更新得字符串,更新时不会涌现页分裂得情形,避免涌现存储碎片,得到更好的io性能
18. Mysql 的存储引擎,myisam和innodb的差异。
答:大略的表达:
MyISAM 是非事务的存储引擎;适宜用于频繁查询的运用;表锁,不会涌现去世锁;适宜小数据,小并发
innodb是支持事务的存储引擎;合于插入和更新操作比较多的运用;设计合理的话是行锁(最大差异就在锁的级别上);适宜大数据,大并发。
19. 数据表类型有哪些
答:MyISAM、InnoDB、HEAP、BOB,ARCHIVE,CSV等。
MyISAM:成熟、稳定、易于管理,快速读取。一些功能不支持(事务等),表级锁。
InnoDB:支持事务、外键等特性、数据行锁定。空间占用大,不支持全文索引等。
20. MySQL数据库作发布系统的存储,一天五万条以上的增量,估量运维三年,怎么优化?
a. 设计良好的数据库构造,许可部分数据冗余,只管即便避免join查询,提高效率。
b. 选择得当的表字段数据类型和存储引擎,适当的添加索引。
c. mysql库主从读写分离。
d. 找规律分表,减少单表中的数据量提高查询速率。
e。添加缓存机制,比如memcached,apc等。
f. 不常常改动的页面,天生静态页面。
g. 书写高效率的SQL。比如 SELECT FROM TABEL 改为 SELECT field_1, field_2, field_3 FROM TABLE.
21. 对付大流量的网站,您采取什么样的方法来办理各页面访问量统计问题?
答:a. 确认做事器是否能支撑当前访问量。
b. 优化数据库访问。
c. 禁止外部访问链接(盗链), 比如图片盗链。
d. 掌握文件下载。
e. 利用不同主机分流。
f. 利用浏览统计软件,理解访问量,有针对性的进行优化。
4、如何进行SQL优化?(关于后边的阐明同学们可以进行理解,到时根据自己的理解把大体意思说出来即可)
答:
(1)选择精确的存储引擎
以 MySQL为例,包括有两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。
MyISAM 适宜于一些须要大量查询的运用,但其对付有大量写操作并不是很好。乃至你只是须要update一个字段,全体表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。其余,MyISAM 对付 SELECT COUNT() 这类的打算是超快无比的。
InnoDB 的趋势会是一个非常繁芜的存储引擎,对付一些小的运用,它会比 MyISAM 还慢。但是它支持"行锁" ,于是在写操作比较多的时候,会更精良。并且,他还支持更多的高等运用,比如:事务。
(2)优化字段的数据类型
记住一个原则,越小的列会越快。如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有情由利用 INT 来做主键,利用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不须要记录韶光,利用 DATE 要比 DATETIME 好得多。当然,你也须要留够足够的扩展空间。
(3)为搜索字段添加索引
索引并不一定便是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会常常用来做搜索,那么最好是为其建立索引,除非你要搜索的字段是大的文本字段,那该当建立全文索引。
(4)避免利用Select 从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库做事器和WEB做事器是两台独立的做事器的话,这还会增加网络传输的负载。纵然你要查询数据表的所有字段,也只管即便不要用通配符,善用内置供应的字段打消定义大概能给带来更多的便利。
(5)利用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相称的完美。例如,性别、民族、部门和状态之类的这些字段的取值是有限而且固定的,那么,你该当利用 ENUM 而不是 VARCHAR。
(6)尽可能的利用 NOT NULL
除非你有一个很特殊的缘故原由去利用 NULL 值,你该当总是让你的字段保持 NOT NULL。 NULL实在须要额外的空间,并且,在你进行比较的时候,你的程序会更繁芜。 当然,这里并不是说你就不能利用NULL了,现实情形是很繁芜的,依然会有些情形下,你须要利用NULL值。
(7)固定长度的表会更快
如果表中的所有字段都是"固定长度"的,全体表会被认为是 "static" 或 "fixed-length"。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了个中一个这些字段,那么这个表就不是"固定长度静态表"了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,由于MySQL征采得会更快一些,由于这些固定的长度是很随意马虎打算下一个数据的偏移量的,以是读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,须要程序找到主键。
并且,固定长度的表也更随意马虎被缓存和重修。不过,唯一的副浸染是,固定长度的字段会摧残浪费蹂躏一些空间,由于定长的字段无论你用不用,他都是要分配那么多的空间。
22,为表中得字段选择得当得数据类型(物理设计)
字段类型优先级: 整形>date,time>enum,char>varchar>blob,text
优先考虑数字类型,其次这天期或者二进制类型,末了是字符串类型,同级别得数据类型,该当优先选择占用空间小的数据类型
23:存储期间
Datatime:以 YYYY-MM-DD HH:MM:SS 格式存储期间韶光,精确到秒,占用8个字节得存储空间,datatime类型与时区无关
Timestamp:以韶光戳格式存储,占用4个字节,范围小1970-1-1到2038-1-19,显示依赖于所指定得时区,默认在第一个列行的数据修正时可以自动得修正timestamp列得值
Date:(生日)占用得字节数比利用字符串.datatime.int储存要少,利用date只须要3个字节,存储日期月份,还可以利用日期韶光函数进行日期间得打算
Time:存储韶光部分得数据
把稳:不要利用字符串类型来存储日期韶光数据(常日比字符串占用得储存空间小,在进行查找过滤可以利用日期得函数)
利用int存储日期韶光不如利用timestamp类型















