
这份代码紧张由两部分组成:1) 能用来提交 SQL 文件的 SqlSubmit 实现。2) 用于演示的 SQL 示例、Kafka 启动停滞脚本、 一份测试数据集、Kafka 数据源天生器。
通过本实战,你将学到:

SqlSubmit 的实现
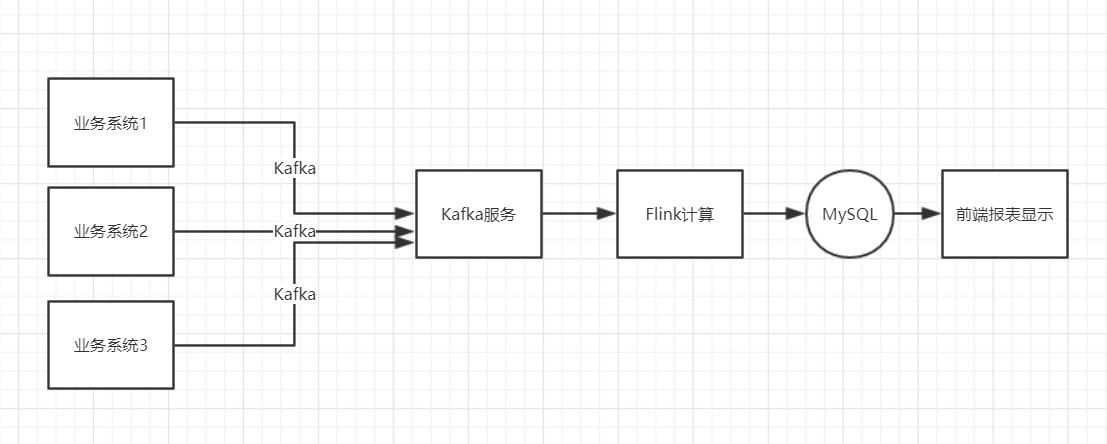
笔者一开始是想用 SQL Client 来贯穿全体演示环节,但可惜 1.9 版本 SQL CLI 还不支持处理 CREATE TABLE 语句。以是笔者就只好自己写了个大略的提交脚本。后来想想,也挺好的,可以让听众同时理解如何通过 SQL 的办法,和编程的办法利用 Flink SQL。
SqlSubmit 的紧张任务是实行和提交一个 SQL 文件,实现非常大略,便是通过正则表达式匹配每个语句块。如果是 CREATE TABLE 或 INSERT INTO 开头,则会调用 tEnv.sqlUpdate(...)。如果是 SET 开头,则会将配置设置到 TableConfig 上。其核心代码紧张如下所示:
利用 DDL 连接 Kafka 源表
在 flink-sql-submit 项目中,我们准备了一份测试数据集(来自阿里云天池公开数据集,特殊鸣谢),位于 src/main/resources/user_behavior.log。数据以 JSON 格式编码,大概长这个样子:
{\"大众user_id\公众: \公众543462\公众, \"大众item_id\"大众:\公众1715\"大众, \"大众category_id\公众: \"大众1464116\"大众, \"大众behavior\公众: \公众pv\公众, \公众ts\"大众: \公众2017-11-26T01:00:00Z\公众}{\"大众user_id\"大众: \公众662867\"大众, \公众item_id\公众:\"大众2244074\"大众, \"大众category_id\"大众: \公众1575622\"大众, \"大众behavior\"大众: \"大众pv\"大众, \公众ts\公众: \"大众2017-11-26T01:00:00Z\"大众}
为了仿照真实的 Kafka 数据源,笔者还特地写了一个 source-generator.sh 脚本(感兴趣的可以看下源码),会自动读取 user_behavior.log 的数据并以默认每毫秒1条的速率灌到 Kafka 的 user_behavior topic 中。
有了数据源后,我们就可以用 DDL 去创建并连接这个 Kafka 中的 topic(详见 src/main/resources/q1.sql)。
注:可能有用户会以为个中的 connector.properties.0.key 等参数比较奇怪,社区操持将不才一个版本中改进并简化 connector 的参数配置。
利用 DDL 连接 MySQL 结果表
连接 MySQL 可以利用 Flink 供应的 JDBC connector。例如
PV UV 打算
假设我们的需求是打算每小时全网的用户访问量,和独立用户数。很多用户可能会想到利用滚动窗口来打算。但这里我们先容另一种办法。即 Group Aggregation 的办法。
INSERT INTO pvuv_sinkSELECT DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt, COUNT() AS pv, COUNT(DISTINCT user_id) AS uvFROM user_logGROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00')
它利用 DATE_FORMAT 这个内置函数,将日志韶光归一化成“年月日小时”的字符串格式,并根据这个字符串进行分组,即根据每小时分组,然后通过 COUNT() 打算用户访问量(PV),通过 COUNT(DISTINCT user_id) 打算独立用户数(UV)。这种办法的实行模式是每收到一条数据,便会进行基于之前打算的值做增量打算(如+1),然后将最新结果输出。以是实时性很高,但输出量也大。
我们将这个查询的结果,通过 INSERT INTO 语句,写到了之前定义的 pvuv_sink MySQL 表中。
注:在深圳 Meetup 中,我们有对这种查询的性能调优做了深度的先容。
实战演示环境准备
本实战演示环节须要安装一些必须的做事,包括:
Flink 本地集群:用来运行 Flink SQL 任务。Kafka 本地集群:用来作为数据源。MySQL 数据库:用来作为结果表。Flink 本地集群安装1.下载 Flink 1.9.0 安装包并解压:https://www.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.11.tgz
2.下载以下依赖 jar 包,并拷贝到 flink-1.9.0/lib/ 目录下。由于我们运行时须要依赖各个 connector 实现。
flink-sql-connector-kafka_2.11-1.9.0.jarhttp://central.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.9.0/flink-sql-connector-kafka_2.11-1.9.0.jarflink-json-1.9.0-sql-jar.jarhttp://central.maven.org/maven2/org/apache/flink/flink-json/1.9.0/flink-json-1.9.0-sql-jar.jarflink-jdbc_2.11-1.9.0.jarhttp://central.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.9.0/flink-jdbc_2.11-1.9.0.jarmysql-connector-java-5.1.48.jarhttps://dev.mysql.com/downloads/connector/j/5.1.html3.将 flink-1.9.0/conf/flink-conf.yaml 中的 taskmanager.numberOfTaskSlots 修正成 10,由于我们的演示任务可能会花费多于1个的 slot。
4.在 flink-1.9.0 目录下实行 ./bin/start-cluster.sh,启动集群。
运行成功的话,可以在 http://localhost:8081 访问到 Flink Web UI。
其余,还须要将 Flink 的安装路径填到 flink-sql-submit 项目的 env.sh 中,用于后面提交 SQL 任务,如我的路径是
FLINK_DIR=/Users/wuchong/dev/install/flink-1.9.0
Kafka 本地集群安装
下载 Kafka 2.2.0 安装包并解压:https://www.apache.org/dist/kafka/2.2.0/kafka_2.11-2.2.0.tgz
将安装路径填到 flink-sql-submit 项目的 env.sh 中,如我的路径是
KAFKA_DIR=/Users/wuchong/dev/install/kafka_2.11-2.2.0
在 flink-sql-submit 目录下运行 ./start-kafka.sh 启动 Kafka 集群。
在命令行实行 jps,如果看到 Kafka 进程和 QuorumPeerMain 进程即表明启动成功。
MySQL 安装
可以在官方页面下载 MySQL 并安装:
https://dev.mysql.com/downloads/mysql/
如果有 Docker 环境的话,也可以直接通过 Docker 安装
https://hub.docker.com/_/mysql
$ docker pull mysql$ docker run --name mysqldb -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql
然后在 MySQL 中创建一个 flink-test 的数据库,并按照上文的 schema 创建 pvuv_sink 表。
提交 SQL 任务
1.在 flink-sql-submit 目录下运行 ./source-generator.sh,会自动创建 user_behavior topic,并实时往里注意灌输数据。
2.在 flink-sql-submit 目录下运行 ./run.sh q1, 提交成功后,可以在 Web UI 中看到拓扑。
在 MySQL 客户端,我们也可以实时地看到每个小时的 pv uv 值在不断地变革
结尾
本文带大家搭建根本集议论况,并利用 SqlSubmit 提交纯 SQL 任务来学习理解如何连接外部系统。flink-sql-submit/src/main/resources/q1.sql 中还有一些注释掉的调优参数,感兴趣的同学可以将参数打开,不雅观察对作业的影响。关于这些调优参数的事理,可以看下我在 深圳 Meetup 上的分享《Flink SQL 1.9.0 技能底细和最佳实践》。
作者:巴蜀真人















