
要节制数据库的加锁机制,我们须要弄明白三件事:
有哪些类型的锁对什么东西加锁以什么样的办法加锁有哪些类型的锁MySQL InnoDB一共有四种锁:共享锁(读锁,S锁)、排他锁(写锁,X锁)、意向共享锁(IS锁)和意向排他锁(IX锁)。个中共享锁与排他锁属于行级锁,其余两个意向锁属于表级锁。

比如SELECT ... FROM T1 LOCK IN SHARE MODE语句,首先会对表T1加IS锁,成功加上IS锁后才会对数据加S锁。
同样,SELECT ... FROM T1 FOR UPDATE语句,首先会对表T1加IX锁,成功加上IX锁后才会对数据加X锁。
MySQL官网上有个去世锁的例子,但剖析得过于概括,这里我们详细剖析一下。
首先,会话S1以SELECT FROM t WHERE i = 1 LOCK IN SHARE MODE查询,该语句首先会对t表加IS锁,接着会对数据(i = 1)加S锁。
mysql> CREATE TABLE t (i INT) ENGINE = InnoDB; Query OK, 0 rows affected (1.07 sec) mysql> INSERT INTO t (i) VALUES(1); Query OK, 1 row affected (0.09 sec) mysql> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) mysql> SELECT FROM t WHERE i = 1 LOCK IN SHARE MODE; +------+ | i | +------+ | 1 | +------+ 1 row in set (0.10 sec)
接着,会话S2实行DELETE FROM t WHERE i = 1,该语句考试测验对t表加IX锁,由于IX锁与IS锁是兼容的,以是成功对t表加IX锁。接着连续对数据(i = 1)加X锁,但数据已经被会话S1事务加了S锁了,以是会话S2等待。
mysql> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) mysql> DELETE FROM t WHERE i = 1;
接着,会话S1也实行DELETE FROM t WHERE i = 1,该语句首先对t表加IX锁,虽然会话S2已经对t表加了IX锁,但IX锁与IX锁之间是兼容的,以是成功对t表加上IX锁。接着会话S1会对数据(i = 1)加X锁,此时创造会话S2霸占的IX锁与X锁不兼容,以是会话S1也等待。
就这样,会话S1等S2开释IX锁,而会话S2等S1开释S锁,从而去世锁发生。
mysql> DELETE FROM t WHERE i = 1; Query OK, 1 row affected (0.00 sec) mysql>
上例中会话S1虽然实行成功了,但是下面会话S2发生了去世锁。这是由于Mysql检测到去世锁后,会自动逼迫个中一个事务退出。
mysql> DELETE FROM t WHERE i = 1; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction mysql>对什么加锁
每一张InnoDB表都有且仅有一个分外的索引,聚族索引(Clustered Index),表中的数据是直接存放在聚族索引的叶子节点中,这样,根据聚族索引查询就会比普通索引更快,由于少了一次IO操作。
常日,聚族索引便是表的主键;如果表没有主键,那InnoDB会把第一个非空的唯一索引当作聚族索引;如果表既无主键,又无非空的唯一索引,那么InnoDB会创建一个隐蔽的索引作为聚族索引。表中的其它索引,都叫做第二索引(Secondary Index),第二索引中只包含自身索引列和聚族索引列的内容,以是当一个表的主键很永劫,其它的索引都会受到影响。
为什么要先讲聚族索引呢?由于这对理解InnoDB加锁机制很主要,InnoDB加锁的工具不是返回的数据记录,而是查询这些数据时所扫描过的索引。当我们实行一个锁读(select … lock in share mode或者select … for update)时,InnoDB不是对终极的返回结果加锁,而是对查询这些结果时所扫描的索引加锁,如果被扫描的索引不是聚族索引,那被扫描的索引以及它所指向的聚族索引也会被加锁。
由此可知,当一个锁读无法利用索引的话,InnoDB便是遍历全体表(遍历全体聚族索引),从而把整张表都锁住。
以什么样的办法加锁MySQL InnoDB支持三种锁定办法:
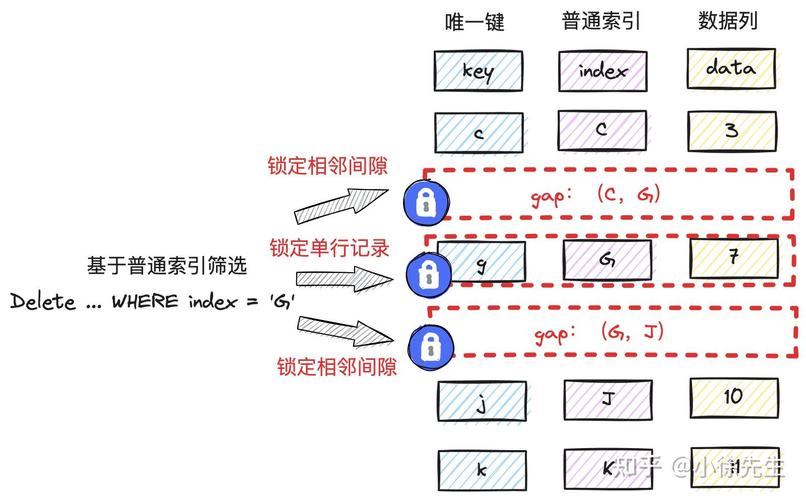
行锁(Record Lock):锁直接加在索引上。间隙锁(Gap Lock):锁加在不存在的空闲空间,可以是两个索引记录之间,也可能是第一个索引记录之前或末了一个索引之后的空间。间隙锁的浸染是防止其它事务的插入操作,以此来防止幻读的发生,以是间隙锁不区分共享锁与排它锁。Next-Key Lock:行锁与间隙锁组合起来用就叫做Next-Key Lock。默认情形下,InnoDB事情在可重复读隔离级别下,并且以Next-Key Lock的办法对数据行进行加锁,这样可以有效防止幻读的发生。Next-Key Lock是行锁与间隙锁的组合,这样,当InnoDB扫描索引记录的时候,会首先对选中的索引记录加上行锁,再对索引记录两边的间隙加上间隙锁。如果一个间隙被事务T1加了锁,其它事务是不能在这个间隙插入记录的。
还是用之前的员工表举例:
id
num
depart
name
10
1010
5100
张三
20
1020
5200
李四
30
1030
5300
王五
40
1040
5100
刘大
个中,id表示记录主键;num表示员工工号,唯一索引;depart表示员工所在的部门编号,普通索引;name表示员工姓名。测试前插入一些测试数据。
depart索引可以表示为下面一张二维表:
depart
5100
5100
5200
5300
ID
10
40
20
30
由上面的表可知,depart索引将全体间隙拆分为五个区间:
(-∞, [5100|10])([5100|10], [5100|40])([5100|40], [5200|20])([5200|20], [5300|30])([5300|30], +∞)现在我们在可重复读级别下,根据索引字段depart = 5100加锁查询的话,该当会锁定前三个间隙:
mysql> set autocommit=0;Query OK, 0 rows affected (0.01 sec)mysql> set session transaction isolation level repeatable read;Query OK, 0 rows affected (0.00 sec)mysql> select from employee where depart = 5100 lock in share mode;+----+------+--------+--------+| id | num | depart | name |+----+------+--------+--------+| 10 | 1010 | 5100 | 张三 || 40 | 1040 | 5100 | 刘大 |+----+------+--------+--------+2 rows in set (0.00 sec)
另起一个会话测试一下:
mysql> insert into employee values (1, 9999, 5000, 'xx');ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> insert into employee values (15, 9999, 5100, 'xx');ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> insert into employee values (55, 9999, 5100, 'xx');ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> insert into employee values (55, 9999, 5150, 'xx');ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> insert into employee values (15, 9999, 5200, 'xx');ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> insert into employee values (25, 9999, 5200, 'xx');Query OK, 1 row affected (0.00 sec)mysql> select from employee where id = 10 for update;ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> select from employee where id = 40 for update;ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql> select from employee where depart = 5100 for update;ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transactionmysql>
个中(5000, 1)命中第一个间隙(-∞, [5100|10]);
(5100, 15)命中第二个间隙([5100|10], [5100|40]);
(5100, 55)、(5150, 55)与(5200, 15)都是命中第三间隙([5100|40], [5200|20]);
以是前五个插入都由于锁等待超时而失落败,直到(5200, 25)才成功。
间隙锁在InnoDB的唯一浸染便是防止其它事务的插入操作,以此来达到防止幻读的发生,以是间隙锁不分什么共享锁与排它锁。
在上面的例子中,我们选择的是一个普通(非唯一)索引字段来测试的。这不是随便选的,如果InnoDB扫描的是一个主键、或是一个唯一索引的话,那InnoDB只会采取行锁办法来加锁,而不会利用Next-Key Lock的办法,也便是说不会对索引之间的间隙加锁,大家可以想想为什么?
末了把稳看上例中末了的三个查询也超时了,表示索引depart = 5100,及它所指向的聚族索引id = 10 & id = 40都被加了读锁(行锁)。
间隙锁存在的意义是为理解决幻读的问题,在读已提交级别下,InnoDB是不会利用间隙锁的,由于这个级别本身不哀求避免幻读的发生,以是在读已提交级别下,InnoDB只会以行锁的办法对索引加锁,不会利用间隙锁。
总结select from … lock in share mode对索引加共享锁;select from ... for update对索引加排他锁。update与delete对索引加排他锁。insert into … 对间隙加意向插入锁(相称于范围为1的间隙锁)。默认情形下select from ... 是非壅塞式读(Serializable除外),不会对索引加锁。在读已提交级别下,总是查询记录的最新、有效的版本;在可重复读级别下,会记住第一次查询时的版本,之后的查询会基于该版本。例外的情形是在Serializable级别,这时会以Next-Key Lock的办法对索引加锁。在可重复读级别下,InnoDB以Next-Key Lock的办法对索引加锁;在读已提交级别下,InnoDB以Index-Record Lock的办法对索引加锁。被加锁的索引如果不是聚族索引,那索引所指向的聚族索引也会被加锁(如果是索引覆盖查询,则不会对聚族索引加锁)。














