
1. 兼容性好:Protobuf支持向后兼容和向前兼容,纵然数据构造发生变革,也不会轻易毁坏现有系统的数据处理能力。
2. 编程措辞多:Protobuf拥有官方支持的多种编程措辞实现,包括C++、Java、Python等,适用于不同的开拓环境和需求。

3. 编解码速率高:比较XML和JSON,Protobuf在编码和解码过程中表现出更高的效率,这对付性能敏感的运用尤为主要。
4. 数据体积小:Protobuf通过利用变量长度整数和独特的编码技能,有效地减少了大小,使得网络传输更为高效。
5. 代码天生机制:Protobuf供应了一种自动天生数据访问类代码的机制,这简化了数据的序列化和反序列化操作,并提高了代码的可掩护性。
6. 数据构造可扩展:用户可以通过修正`.proto`文件来定义新的数据构造,而无需改动已有的代码,这为数据构造的迭代供应了便利。
为了更全面地理解Protobuf的上风,可以进一步磋商它的运用处景和履行细节:
1. 适用场景:Protobuf特殊适用于那些对性能有严格哀求的环境,例如大型分布式系统、移动设备通信等。
2. 版本管理:在利用Protobuf时,应该把稳合理方案类型的版本,以保持与旧版本做事的兼容性。
3. 工具支持:Protobuf虽然供应了代码天生工具,但在不同编程措辞间的利用可能须要额外的适配层或转换逻辑。
Protobuf以其高效的数据处理能力和跨平台特性,在数据交流和存储领域展现出显著上风。对付须要处理大量数据和/或追求高性能的运用,采取Protobuf作为数据序列化工具是一个明智的选择。
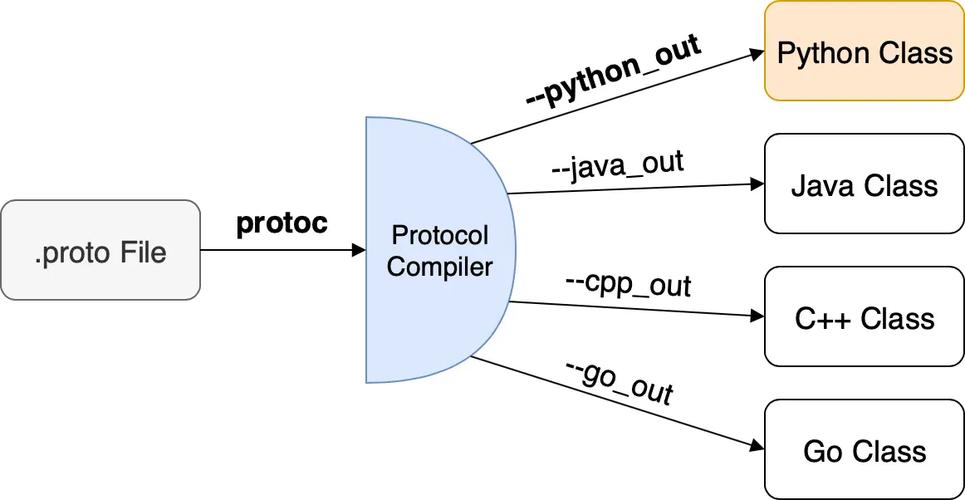
Java和前端可以利用Protocol Buffers(简称Protobuf)进行字节交互。Protobuf是一种轻量级的数据交流格式,可以在不同的措辞之间进行数据序列化和反序列化。在Java中,须要定义一个`.proto`文件来描述你的数据构造,然后利用`protoc`编译器天生对应的Java类。例如,创建一个名为`message.proto`的文件,内容如下:```syntax = "proto3";message MyMessage {string name = 1;int32 age = 2;}```然后利用`protoc`编译器天生Java类:```protoc --java_out=. message.proto```这将天生一个名为`MyMessage.java`的文件,你可以在Java代码中利用这个类来序列化和反序列化数据。在前端(JavaScript),你须要利用一个支持Protobuf的库,如`protobuf.js`。首先安装`protobuf.js`库:```npm install protobufjs```然后在前端代码中利用`protobuf.js`库加载`.proto`文件并解析数据:```javascriptconst protobuf = require("protobufjs");protobuf.load("message.proto", function (err, root) {if (err) throw err;const MyMessage = root.lookupType("MyMessage");// 创建一个MyMessage实例const message = MyMessage.create({ name: "张三", age: 30 });// 将实例序列化为字节数组const buffer = MyMessage.encode(message).finish();// 将字节数组发送给后端...});```在Java后端,你可以利用天生的`MyMessage`类来反序列化前端发送过来的字节数组:```javaimport com.example.MyMessage;// ...byte[] buffer = ...; // 从前端吸收到的字节数组MyMessage message = MyMessage.parseFrom(buffer);System.out.println("Name: " + message.getName());System.out.println("Age: " + message.getAge());```这样,Java和前端就可以通过Protobuf进行字节交互了。















