
在Python中导入数据
在开始学习Python和Pandas时,为了进行数据剖析和可视化,我们常日从实践导入数据开始。在之前的文章中,我们已经理解到我们可以直接在Python中输入值(例如,从Python字典创建Pandas dataframe)。然而,通过从可用的源导入数据来获取数据当然更为常见。这常日是通过从CSV文件或Excel文件中读取数据来完成的。例如,要从一个.csv文件导入数据,我们可以利用Pandas read_csv方法。这里有一个如何利用该方法的快速的例子,但一定要查看有关该主题的博客文章以得到更多信息。
现在,上面的方法只有在我们已经有了得当格式的数据(如csv或JSON)时才有用(请参阅关于如何利用Python和Pandas解析JSON文件的文章)。

我们大多数人会利用Wikipedia来理解我们感兴趣的主题信息。此外,这些Wikipedia文章常日包含HTML表格。
要利用pandas在Python中得到这些表格,我们可以将其剪切并粘贴到一个电子表单中,然后,例如利用read_excel将它们读入Python。现在,这个任务当然可以用更少的步骤来完成:我们可以通过web抓取来对它进行自动化。一定要查看一下什么是web抓取。
先决条件
当然,这个Pandas读取HTML教程将哀求我们安装Pandas及其依赖项。例如,我们可以利用pip来安装Python包,比如Pandas,或者安装一个Python发行版(例如,Anaconda、ActivePython)。下面是如何利用pip安装Pandas: pip install pandas。
把稳,如果涌现说有一个更新版本的pip可用,请查看这篇有关如何升级pip的文章。把稳,我们还须要安装lxml或BeautifulSoup4,当然,这些包也可以利用pip来安装: pip install lxml。
Pandas read_html 语法
下面是如何利用Pandas read_html从HTML表格中抓取数据的最大略的语法:
现在我们已经知道了利用Pandas读取HTML表格的大略语法,接下来我们可以查看一些read_html示例。
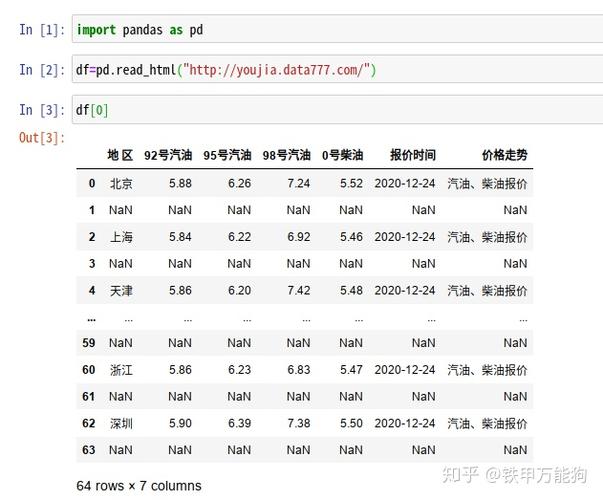
Pandas read_html 示例1:
第一个示例是关于如何利用Pandas read_html方法的,我们将从一个字符串读取HTML表格。
现在,我们得到的结果不是一个Pandas DataFrame,而是一个Python列表。也便是说,如果我们利用type函数,我们可以看到:
如果我们想得到该表格,我们可以利用列表的第一个索引(0)
Pandas read_html 示例 2:
在第二个Pandas read_html示例中,我们将从Wikipedia抓取数据。实际上,我们将得到蟒科蛇(也称为蟒蛇)的HTML表格。
现在,我们得到了一个包含7个表(len(df))的列表。如果我们去Wikipedia页面,我们可以看到第一个表是右边的那个。然而,在本例中,我们可能对第二个表更感兴趣。
Pandas read_html 示例 3:
在第三个示例中,我们将从瑞典的covid-19病例中读取HTML表。这里,我们将利用read_html方法的一些附加参数。详细来说,我们将利用match参数。在此之后,我们还须要洗濯数据,末了,我们将进行一些大略的数据可视化操作。
利用Pandas read_html和匹配参数抓取数据:
如上图所示,该表格的标题为:“瑞典各郡新增COVID-19病例”。现在,我们可以利用match参数并将其作为一个字符串输入:
通过这种办法,我们只得到这个表,但它仍旧是一个dataframes列表。现在,如上图所示,在底部,我们有三个须要删除的行。因此,我们要删除末了三行。
利用Pandas iloc删除末了的行
现在,我们将利用Pandas iloc删除末了3行。把稳,我们利用-3作为第二个参数(请确保你查看了这个Panda iloc教程,以得到更多信息)。末了,我们还创建了这个dataframe的一个副本。
不才一节中,我们将学习如何将多索引列名变动为单个索引。
将多索引变动为单个索引并删除不须要的字符
现在,我们要去掉多索引列。也便是说,我们将把2列索引(名称)变成唯一的列名。这里,我们将利用DataFrame.columns 和 DataFrame.columns,get_level_values:
末了,正如你在“date”列中所看到的,我们利用Pandas read_html从WikiPedia表格抓取了一些注释。接下来,我们将利用str.replace方法和一个正则表达式来删除它们:
利用Pandas set_index变动索引
现在,我们连续利用Pandas set_index将日期列变成索引。这样一来,我们稍后就可以很随意马虎地创建一个韶光序列图。
现在,为了能够绘制这个韶光序列图,我们须要用0添补缺失落的值,并将这些列的数据类型变动为numeric。这里我们也利用了apply方法。末了,我们利用cumsum方法来得到列中每个新值累加后的值:
来自HTML表格的韶光序列图
在末了一个示例中,我们利用Pandas read_html获取我们抓取的数据,并创建了一个韶光序列图。现在,我们还导入了matplotlib,这样我们就可以改变Pandas图例的标题的位置:
结论: 如何将HTML读取到一个 Pandas DataFrame
在这个Pandas教程中,我们学习了如何利用Pandas read_html方法从HTML中抓取数据。此外,我们利用来自一篇Wikipedia文章的数据来创建了一个韶光序列图。末了,我们也可以通过参数index_col来利用Pandas read_html将' Date '列设置为索引列。
英文原文:https://www.marsja.se/how-to-use-pandas-read_html-to-scrape-data-from-html-tables 译者:一瞬














