
现在我们有一张corpinfo单位表,里面有一个belong字段指向上级单位,首先来看一下现在表里有什么数据:
SELECTuid,ubelongFROMcorpinfo

现在是类似下面这样的一个三级菜单,uid为1的是我们的顶级菜单,ubelog为0。
现在我们想实现传入一个 uid ,把当前 uid 和其下级单位的 uid 都展示出来,当然我们可以利用代码或者网上常见的存储过程来实现,但是本日我们用一条SQL语句来实现该效果:
先来看看我们的SQL语句
SELECT DATA.uid FROM( SELECT @ids AS _ids, ( SELECT @ids := GROUP_CONCAT(uid) FROM corpinfo WHERE FIND_IN_SET(ubelong, @ids) ) AS cids, @l := @l+1 AS level FROM corpinfo, (SELECT @ids := (参数) , @l := 0 ) b WHERE @ids IS NOT NULL ) ID, corpinfo DATAWHERE FIND_IN_SET(DATA.uid, ID._ids)ORDER BY level,uid
看下实行结果:
可以看到传入 uid 为 1 后,列出了 uid 为 1 的所有下级单位,连第三级的菜单也列出来了。
比较核心的有下面几个地方:
GROUP_CONCAT()函数
序言:在有 group by 的查询语句中,select指定的字段要么就包含在 group by 语句的后面,作为分组的依据,要么就包含在聚合函数中。
假设我们有一张 user 用户表,我们想查看名字相同的用户的最小年事,可以这样写:
SELECTname,ageFROMuserGROUPBYname
实行结果为:
现在我们想查询 name 相同的用户的所熟年龄,当然我们可以这样写:
SELECTname,ageFROMuserORDERBYname
实行结果为:
但是这样同一个名字涌现多次,看上去非常不直不雅观。有没有更直不雅观的方法,既让每个名字都只涌现一次,又能够显示所有的名字相同的人的id呢?——利用 GROUP_CONCAT() 函数
功能:将 group by 产生的同一个分组中的值连接起来,返回一个字符串结果。
语法:GROUP_CONCAT( [distinct] 要连接的字段 [ORDER BY 排序字段 ASC/DESC ] [separator '分隔符'] )
SELECTname,GROUP_CONCAT(age)FROMuserGROUPBYname
实行结果为:
可以看到相同用户名的年事都放到一起了,以逗号分割。
FIND_IN_SET函数假设我们有一张 book 书本表,有书名和作者两个字段:
SELECTname,authorFROMbook
实行结果为:
现在我们想查作者包含 小A 的书本,我们来试一下:
SELECTname,authorFROMbookWHEREauthorIN('小A')
实行结果为:
实际上这样是弗成的,这样只有当 author 字段的值即是'小A'时(和IN前面的字符串完备匹配),查询才有效,否则都得不到结果。
可能你会想到用LIKE实现,我们来试试看:
SELECTname,authorFROMbookWHEREauthorLIKE'%小A%';
实行结果为:
可以看到把小AA的书本也查出来了,以是用LIKE无法实现该功能。
那么我们如何利用 FIND_IN_SET 函数来实现呢?
SELECTname,authorFROMbookWHEREFIND_IN_SET('小A',author);
实行结果为:
语法:FIND_IN_SET(str,strlist)
str :要查询的字符串strlist :字段名 参数以”,”分隔 如 (1,2,6,8)查询字段(strlist)中包含(str)的结果,返回结果为null或记录
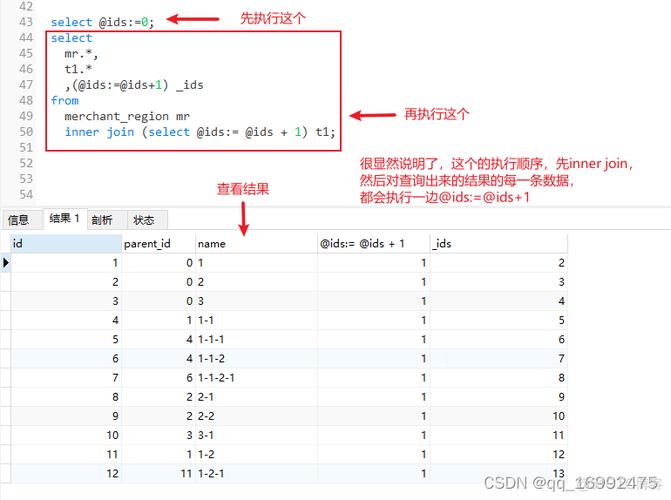
知道了这两个函数后,现在回过分来看看前面的SQL语句:
运行选中的代码后可以看到列出了高下级的关系,至于细节这里不再展开描述。
既然我们能查出当前单位的所有下级单位,那么该当也能查询所有上级单位,来看下SQL:
SELECT uid FROM( SELECT @id AS _id, ( SELECT @id := ubelong FROM corpinfo WHERE uid = @id ) AS _pid, @l := @l+1 as level FROM corpinfo, (SELECT @id := (参数), @l := 0 ) b WHERE @id > 0 ) ID, corpinfo DATA WHERE ID._id = DATA.uid ORDER BY level DESC
还是我们的corpinfo单位表,实行结果为:
可以看到当输入 uid 为 5 时,列出了当前单位及其上级所有单位,SQL和上面的差不多,这里不再细说。
末了补充一段代码,既然我们已经拿到想要的单位编号了,接下来便是要递归构建我们的单位树了,来看下代码:
/ 递归将模块树构建成JSON数组 /private JSONArray getJsonArray(List<ClCorpinfo> list) { Map<Integer, List<ClCorpinfo>> map = new HashMap<>(16); List<ClCorpinfo> sonList; for (ClCorpinfo clCorpinfo : list) { if (map.get(clCorpinfo.getUbelong()) != null) { sonList = map.get(clCorpinfo.getUbelong()); } else { sonList = new ArrayList<>(); } sonList.add(clCorpinfo); map.put(clCorpinfo.getUbelong(), sonList); } JSONArray array = new JSONArray(); if (list.size() > 0) { array = getChildrenTree(map, 0, 0); } return array;}/ 递归构建模块树的子类 /public JSONArray getChildrenTree(Map<Integer, List<ClCorpinfo>> map, Integer uparentid, Integer level) { JSONArray array = new JSONArray(); for (ClCorpinfo clCorpinfo : map.get(uparentid)) { JSONObject obj = new JSONObject(); obj.put("uid", clCorpinfo.getUid()); obj.put("ubelong", clCorpinfo.getUbelong()); obj.put("ucorpname", clCorpinfo.getUcorpname()); obj.put("uparentname", clCorpinfo.getUparentname()); if (map.get(clCorpinfo.getUid()) != null) { level++; obj.put("children", getChildrenTree(map, clCorpinfo.getUid(), level)); } else { obj.put("children", null); } array.add(obj); } return array;}
上面这段戴安只要传入单位凑集,接下来会递归来构建我们的单位树,接下来只要前端渲染上去就完事了。
总结实在网上也有很多其它的办理方案,比如用代码实现,也可以用存储过程实现,本日我们利用SQL语句来实现并不一定是最好的办法,虽然大略但是比较难懂,我这边只是给大伙供应一个可行的方案,如果有什么不对的地方请多多指教。















