
Deze Wang
引用

Wang, Deze, et al. "One adapter for all programming languages? adapter tuning for code search and summarization." 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023.
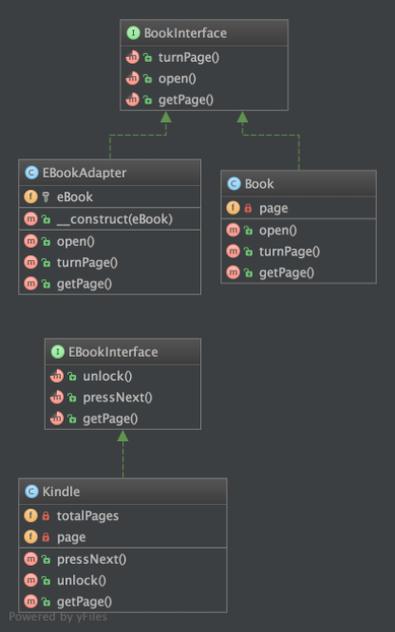
论文: One Adapter for All Programming Languages? Adapter Tuning for Code Search and Summarization
择要
这篇文章简要先容了由于预演习模型可以自动实行许多代码智能任务,因此常用的做法是在各种编程措辞的任务数据集上对模型进行微调。虽然最近研究表明,多措辞微调对多个任务和模型有益,但我们创造这会导致最新模型UniXcoder和CodeT5的性能低落。为理解决多措辞模型中的灾害性遗忘问题,我们固定所有预演习模型参数,插入高效的适配器进行微调。比较每种编程措辞的全模型微调,适配器调优仅更新0.6%的参数,在代码搜索和择要任务中实现了同等改进,达到最前辈的效果。实验还表明,这种方法在跨措辞和低资源场景下非常有效。对每种编程措辞进行200个样本的多措辞微调险些能达到对全体数据集进行代码择要微调的效果。我们的三个探测任务实验表明,适配器调优显著优于全模型调优,并有效战胜了灾害性遗忘问题。
1 弁言
深度学习模型广泛运用于各种编程措辞的任务中,如Java、Python、Ruby等,特殊是在代码搜索和总结方面。当前的标准做法是加载预演习的措辞模型,并在特定编程措辞的数据集上对其进行演习和评估。这意味着每种编程措辞都须要单独的模型,导致N种编程措辞须要N个独立模型,这些模型的演习、支配和掩护都十分繁芜。
自然措辞处理(NLP)领域的研究表明,暴露模型于多种措辞可以提高低资源措辞的性能。不同于自然措辞,多种编程措辞具有相似的语法形式,并且从同一预演习模型微调的单措辞模型将共享公共词汇表。因此,多措辞演习可能更有利于编程措辞之间的知识转移。
Ahmed和Devanbu[4]的干系研究表明,多措辞微调基于预演习代码模型CodeBERT[5]和GraphCodeBERT[6],在代码搜索和总结任务上带来了险些同等的改进。然而,我们的实验创造,这一结论不能推广到最新的预演习代码模型UniXcoder[8]和CodeT5[9]。在这些模型上,多措辞微调导致大多数编程措辞的代码搜索和总结任务的性能低落。演习一个能够同时支持多种编程措辞并保持与专用单措辞模型相称性能的模型是一个寻衅。
许多研究表明,多措辞模型可能由于灾害性遗忘预演习知识而遭受负迁移。我们通过固定预演习模型的所有参数,插入适配器并进行微调,创造它可以缓解上述问题。此外,通过探测实验剖析,我们证明了适配器调优的有效性。
我们在不同的预演习代码模型中引入适配器模块。与为每种编程措辞演习全体模型比较,适配器调优只需调度不超过0.6%的参数。新模型在代码搜索和总结任务上取得了同等的性能提升,并达到最前辈的结果。实验还表明,在代码总结任务中,每种措辞仅需200个样本的适配器调优险些能达到对全体数据集调优的效果,表明快速适应新的编程措辞是可能的。此外,我们展示了它在跨措辞任务中的有效性,并进行了措辞探测实验以解释厥后果。
本文的紧张贡献如下:
我们创造,多措辞微调在CodeBERT和GraphCodeBERT上取得显著性能提升,但在UniXcoder和CodeT5上却导致性能低落。我们通过三个探测任务展示了适配器调优可以显著战胜多措辞调优中的灾害性遗忘问题。基于预演习的UniXcoder和CodeT5,我们的模型在六种编程措辞的代码搜索和总结任务中调度不超过0.6%的参数,得到同等的性能提升并达到最前辈的结果。我们表明,每种编程措辞200个样本(原始数据集的0.02%)的适配器调优在代码总结任务中表现良好。2 实验方案先容
为了研究源代码理解和天生的多措辞任务,我们提出了一系列研究问题并设计了相应的研究方法。
2.1 RQ1:多措辞微调在不同模型和下贱任务上的表现如何?
Ahmed和Devanbu[4]创造多措辞微调可以使CodeBERT和GraphCodeBERT受益,我们研究了这一创造是否可以推广到其他预演习模型。
RQ1设计: 我们在代码搜索和代码总结任务上利用多措辞数据集对UniXcoder和CodeT5进行微调。多措辞数据集包含六种编程措辞的数据:Python、Java、JavaScript、Ruby、Go和PHP。我们评估了这些模型在多措辞数据集和单措辞数据集上的表现,并与CodeBERT、GraphCodeBERT和PLBART进行比较。
2.2 RQ2:适配器调优在跨措辞场景中的效果如何?
跨措辞任务涉及利用一种编程措辞的数据集微调预演习模型,并用另一种编程措辞进行测试。我们关注适配器调优在跨措辞任务中的有效性,通过插入适配器并调度少量参数进行实验。 RQ2设计: 我们用六个单措辞数据集对UniXcoder和CodeT5进行微调,并在所有编程措辞上进行测试。对付适配器调优,我们为每种措辞调优适配器,并在所有编程措辞上测试。我们还比较了适配器调优与全模型调优在跨措辞任务上的表现。
2.3 适配器调优在不同预演习模型上的多措辞微调效果如何?
多措辞任务须要模型在多种编程措辞上表现出色。我们研究适配器调优是否能有效办理多措辞任务。RQ3设计: 我们将适配器插入到UniXcoder和CodeT5中,并用多措辞数据集对适配器进行微调。然后在代码搜索和代码总结任务上评估适配器的性能。我们将这些多措辞模型的表现与相应的单措辞模型以及全模型微调的多措辞模型进行比较。
2.4 多措辞微调在低资源情形下的效果如何?
对付多措辞模型,我们期望它能够快速学习和推广到新的编程措辞。然而,许多编程措辞的标记数据有限。因此,我们对现有数据集进行采样,研究在低资源场景下多措辞学习的性能。RQ4设计: 我们从每种编程措辞的数据集中随机抽取100、200、500和1000个样本。然后将适配器插入到CodeT5中,并根据这些数据的组合进行模型评估。改变随机种子,重复实验多次,并对结果进行均匀,以考验多措辞学习的有效性。
2.5 为什么适配器调优在上述场景中优于全模型调优?
只管适配器调优在上述场景中显示出优胜的性能,但我们须要进一步磋商其缘故原由。我们利用探测实验来评估这一点。RQ5设计: 我们通过探测实验评估多个模型的隐蔽状态嵌入,丈量它们捕获代码干系基本特色的能力。我们采取码长预测、圈繁芜度和无效类型检测三个探测任务,这些任务分别对应源代码的表层信息、语法信息和语义信息。在对下贱任务上的模型进行微调后,我们提取探测任务上的预演习向量嵌入,以检讨模型对代码信息的理解。特殊是,我们验证适配器调优在上述场景中的有效性是否在探测实验中得到同等表示。
3 实验评估
为了在提交天生任务中验证第5节中的提案,我们做了两个实验:
(1) 比较利用所有代码修正作为输入和仅利用添加或删除的行作为输入的提交天生结果。
(2) 溶解研究多个初始模型权值,探求PL和NL在语境表征上差距最小的权值。
3.1 实验设置
从CodeXGLUE中选择数据集,该数据集结合了CodeSearchNet[18],并仔细地进行了重复数据删除。表1显示了该数据集的统计信息。该数据集包含六种编程措辞的代码片段和自然措辞描述对,包括Python、Java、JavaScript、Ruby、Go和PHP。从表中可以看出,不同编程措辞的数据大小有显著差异。特殊是Ruby和JavaScript的数据集比其他编程措辞的数据集要小得多。
代码搜索:我们利用的数据集改编自相同的CodeSearchNet数据集,并添加了郭等人[6]的候选代码。除了用于检索的额外候选代码外,该数据集与我们用于代码汇总的数据集相同。
探测任务的数据集:我们采取Karmakar和robes[14]的数据集进行探测任务。详细来说,对付LEN任务,长度标签被设置为5个class-bin(0-50、50-100等)。CPX的繁芜度标签是用metrix++工具得到的,取值范围是0 ~ 9。TYP任务的代码段根据是否包含无效类型分为两类。每个任务的数据集包含10k个样本,并且是类平衡的。
代码总结:根据前面的事情,我们利用平滑的BLEU-4[19]作为评估指标。它是一种基于精度的度量,丈量天生文本和真实文本之间的n-gram几何精度。我们还遵照之前的事情,并对编程措辞的BLEU进行均匀,以报告总体得分。
代码搜索:我们利用均匀倒数秩(MRR)作为评估指标。MRR是一组查询结果的倒数秩的均匀值。查询的倒数排名是第一个命中结果排名的倒数。
探测任务:我们利用的所有探测任务都是分类任务,我们利用分类精度作为这些任务的度量标准。
我们的代码都是在Pytorch1中实现的。我们从Huggingface2加载预演习模型,同时保持其超参数设置。由于适配器调度比全模型微调调度更少的参数,我们将UniXcoder的学习率设置为5e−5,CodeT5设置为1e−4。我们不才游任务上重现这些模型的结果,并不才面给出它们。
对付适配器设置,我们将适配器插入到编码器和解码器的自关注层和前馈层的后面。适配器的尺寸设置为128。所有实验均在4张NVIDIA Tesla V100显卡上进行,每张显卡的显存为32GB。
3.2 实验结果
A. RQ1:多措辞微调如何在不同的模型和下贱任务上实行?
a)代码汇总:在本小节中,我们比较了基于不同预演习模型的多措辞和单措辞微调对代码汇总任务的结果。单措辞微调是在每种措辞的数据集上对一个模型进行微调的原始方法,而多措辞微调只对所有编程措辞的相同大小的一个模型进行微调。预演习的模型包括CodeBERT、GraphCodeBERT、PLBART、UniXcoder和CodeT5,个中CodeT5是用于此任务的最前辈的模型。
结果见表二。我们用前缀m表示多措辞微调模型,由于mCodeBERT是基于CodeBERT微调的多措辞模型。CodeBERT和GraphCodeBERT的结果来自Ahmed和Devanbu[4]。可以清楚地看到,基于CodeBERT和GraphCodeBERT的多措辞微调结果明显优于单措辞微调,并且多措辞微调在所有六种编程措辞中都显示出其有效性。总的来说,改进也很显著,CodeBERT改进了6.90%,GraphCodeBERT改进了5.64%。
然而,在PLBART、UniXcoder和CodeT5上,结果显示出不同的趋势。PLBART、UniXcoder和CodeT5的总分反而低落了。PLBART的结果来自其开放源代码存储库3,作者在个中对多措辞代码择要和天生任务进行了探索性实验。这两个任务的结果表明,多措辞微调会导致大多数编程措辞的性能低落。在UniXcoder上,多措辞调优会导致一半编程措辞的性能低落。在CodeT5上,多措辞调优只在Ruby上得到改进。
b)代码搜索:我们还测试了多措辞微调对代码搜索的有效性,结果如表III所示。由于CodeT5不报告代码的结果搜索时,我们只比较基于CodeBERT、GraphCodeBERT和UniXcoder的结果。UniXcoder是这项任务的最前辈的模型。
从表III中可以看出,多措辞微调在CodeBERT和GraphCodeBERT上显示了有效性,在所有编程措辞上优于每种措辞单独的微调。在UniXcoder上,多措辞调优只在Ruby上得到改进,而在其他编程措辞上则有所低落。多措辞微调极大地提高了Ruby的性能,这该当归功于它的数据大小。它的数据集具有最小的数据大小,从表1可以把稳到,其他编程措辞的数据集乃至比它的数据集大两到十倍。
在这两个任务上,我们的实验反响出相似的结果。多措辞微调在UniXcoder和CodeT5上不再像在CodeBERT和GraphCodeBERT上那样有效。它只在低资源措辞中表现出上风,这与以往的研究结果[1-3]同等,即低资源措辞在多措辞学习中可以通过正向知识迁移而受益。而在其他编程措辞中,多措辞微调的结果比单措辞微调的结果更差。缘故原由可能是由于在同一模型长进修多种编程措辞而导致的灾害性遗忘。
创造1:基于CodeBERT和GraphCodeBERT,多措辞微调在所有编程措辞中都显示出其有效性。在UniXcoder和CodeT5上,多措辞微调有利于低资源措辞,同时导致其他编程措辞的性能低落。
B. RQ2:跨措辞场景中的适配器调优效果如何?
当针对多种编程措辞对全体模型进行微调时,由于灾害性的遗忘导致性能低落,我们选择适配器调优来修复大多数预演习参数并更新少量参数。我们首先考试测验将适配器调优运用于代码择要和代码搜索的跨措辞场景。
a)代码总结:基于CodeT5,我们比较了适配器调优和全模型微调的性能关于跨措辞场景中的代码择要。我们用一种编程措辞对数据集上的模型参数进行微调,并用另一种编程措辞对数据集上的模型进行评估。
为了直不雅观地理解性能差异,图2显示了适配器调优相对付全模型微调的BLEU-4改进。
图2所示. 跨措辞代码择要任务上适配器调优相对付全模型调优的BLEU-4改进
纵轴为演习集的编程措辞,横轴为评估的编程措辞。图2显示,在大多数跨措辞任务上,适配器调优比全模型调优实行得更好。唯一的例外是,在Go措辞中调优的适配器在大多数编程措辞中的表现都不如全模型调优。值得把稳的是,其他编程措辞中的适配器调优在Go措辞中也没有明显的好处。对付适配器来说,Go措辞中的数据不随意马虎适应。可能须要涉及更多的数据或参数。
b)代码搜索:在代码搜索任务上,我们还测试了基于UniXcoder的适配器调优与全模型调优的相对性能,如图3所示。
图3所示. 跨措辞代码搜索任务上适配器调优相对全模型调优的MRR改进
在大多数跨措辞任务中,适配器调优在参数更新较少的情形下优于全模型调优。适配器调优不如全模型调优的任务紧张分布在图的对角线部分。这些任务是用同一种措辞进行演习和评估的,而不是跨措辞任务。在这些单措辞任务中,与适配器调优比较,全模型微调许可调度更多参数以适应任务,而不必担心灾害性的遗忘。
创造2:在大多数跨措辞场景的代码搜索和汇总任务中,适配器调优比全模型调优更有效。
C. RQ3:适配器调优在不同预演习模型上的多措辞全模型微调效果如何?
当适配器调优证明其在跨措辞场景中的有效性时,我们将进一步磋商其在多措辞任务中的性能。
a)代码汇总:代码汇总任务的比拟结果如表4所示。
前缀为m的模型是一个多措辞模型,它只须要一组参数,其他模型必须分别演习六种编程措辞的模型。与多措辞全模型调优比较,基于UniXcoder和CodeT5的适配器调优在所有编程措辞中都显示出其有效性。与最初的微调比较,madapter还在大多数编程措辞中以更少的参数更新优于各种单措辞模型。
为了验证madapter对预演习模型的改进是否优于多措辞全模型微调,我们采取单侧两两t考验进行统计剖析。对付CodeT5上的所有六种措辞和UniXcoder上的大多数措辞,零假设被谢绝。很明显,madapter在代码总结方面比多措辞演习有统计学上的显著改进。
b)代码搜索:在代码搜索上,如表5所示,适配器调优在大多数编程措辞中也优于单措辞和多措辞全模型调优。
对付Ruby和JavaScript等低资源编程措辞,这种改进尤为显著。统计剖析结果表明,除了Ruby的p值为0.004之外,madapter比多措辞演习的改进在所有编程措辞中都具有统计学意义(p <0.001)。
创造3:虽然更新的参数较少,但适配器调优在多措辞学习中比全模型调优更有效。此外,它还优于针对每种编程措辞分别进行微调的结果。
D. RQ4:在低资源情形下多措辞微调的效果如何?
多措辞模型是根据多种编程措辞的数据进行微调的。联合演习和随之而来的正迁移有利于各种编程措辞的学习。实际上,许多编程措辞缺少高质量的标记数据。因此,我们评估是否可以用非常有限的数据来学习每种编程措辞的性能良好的多措辞模型。
我们从六种编程措辞的数据集中均等地抽取演习样例,并网络大小为600、1200、3000和6000的多个多措辞数据集。我们在这些数据集上对mAdapter-CodeT5进行微调,并将结果与全体数据集上的适配器调优进行比较。结果见表六。
从表中可以看出,随着演习样本数量的增加,适配器调优的性能也在不断提高。每种编程措辞利用100个样本的演习结果与其他结果之间存在显著差异。此时,模型无法收敛由于缺少演习数据。当每种编程措辞利用200个样本进行演习时,微调度个数据集的差异小于2 BLEU-4。当每种措辞的样本数量增加到1000时,与基线的差异小于1 BLEU-4。显然,多措辞演习对付低资源代码总结任务是有效的。
可以把稳到,随着数据的增加,模型性能的增长逐渐放缓。在末了一行和倒数第二行的比拟中,纵然超过90万个样本,也只带来不超过1个BLEU-4分数的提升。这一方面表明,预演习模型具有足够的鲁棒性,可以在数据很少的情形下快速适应下贱任务。另一方面,它展示了多措辞微调的潜力,可以充分利用多措辞数据在低资源场景下快速收敛模型。
创造4:多措辞微调在低资源代码汇总任务中非常有效,以至于可以利用每种编程措辞很少的样本来靠近全体数据集的微调结果。
E. RQ5:为什么在上述场景中适配器调优优于全模型调优?
适配器调优在跨措辞、多措辞和低资源场景中通过更新很少的参数来证明其有效性。为了在细粒度级别检讨模型并检讨适配器的行为是否同等,我们运用探测实验来检讨模型是否编码了一组代码特色。我们分别采取LEN任务、CPX任务和TYP任务探测代码表面信息、构造信息和语义信息。
详细来说,我们将适配器插入BERT[20]、CodeBERT、GraphCodeBERT和UniXcoder,并在代码搜索上与原始模型一起对它们进行微调。然后,我们从这些模型的隐蔽层中提取特色向量,并演习一个大略的线性分类器将这些特色向量与不同的代码特色干系联。由于线性分类器没有隐蔽单元,它在探测任务上的性能很大程度上取决于这些模型的特色向量。
我们从这些模型的终极隐蔽层中提取特色向量进行探测,结果如表7所示。总的来说,这些模型在无效类型预测方面表现最好。Adapter-UniXcoder在这个任务上达到了92.65%的准确率,表明该模型确实编码了这样的语义。
Adapter-BERT在码长预测上表现最好,准确率为65.20%。这个任务实质上是预测输入序列中token的数量,其他模型的额外预演习任务可能会危害这个任务。这一创造也与Karmakar和robes[14]在探究式实验中得出的结论同等。在圈繁芜度任务上,Adapter-GraphCodeBERT是性能最好的模型。由于GraphCodeBERT是专门针对构造信息进行预演习的,以是这个结果并不虞外。然而,它相对付其他模型的上风并不明显,大概是由于任务本身更具寻衅性。
进一步将经由适配器微调的模型与表7中的原始模型进行比较,会创造它们的性能存在相称显著的差异,特殊是在BERT、CodeBERT和GraphCodeBERT上。在所有探测任务中,具有适配器调优的模型明显优于原始模型。
为了更清楚地比较适配器调优与原始模型,我们还提取了所有先前层的隐蔽表示作为特色向量,并评估它们在探测任务上的性能。图4显示了三个探测任务的性能随BERT、CodeBERT和graphcodebert上隐蔽层索引的变革情形图中的虚线表示带有适配器调优的模型在探测任务中的性能。所有模型的详细结果显示不才面的匿名存储库中。
相同颜色的线条代表相应的原始型号的性能。总的来说,只管每个探测任务对应于不同的代码特色进行检讨,但在这些任务的模型之间的准确性变革有很大的相似性。在前6个隐蔽层中,适配器调优和全模型微调的性能差别不大。在随后的隐蔽层中,适配器调优与原始调优之间的性能差距日益突出。
该当把稳的是,这些任务是针对代码搜索进行微调的。然而,这些探测任务所需的代码特色并不总是对下贱任务有帮助。
因此,不同模型在探测任务上的精度在末了一层隐蔽层高下降。由于适配器调优在末了一个隐蔽层中的性能明显优于全模型微调,因此具有适配器调优的模型比原始模型编码更多的信息。相反,全模型微调遭受灾害性的遗忘和丢弃这些信息。这些代码特色是低级别的信息,与下贱任务所需的信息比较,它们是跨措辞的通用信息。因此,在此信息的帮助下,适配器调优可以在跨措辞和多措辞任务上实行得更好。我们推测,这便是适配器调优可以减轻灾害性遗忘问题的缘故原由。
从精度的整体变革可以看出,LEN上的精度随着隐蔽层的深度而降落。而CPX的精度则先升高后逐渐降落。除了自然措辞预演习模型BERT外,CodeBERT和GraphCodeBERT在TYP的中间隐蔽层也达到了最好的性能。由于LEN对应于探测表面信息,CPX和TYP对应于代码的构造和语义信息,因此很明显,这些模型在较低层学习表面信息,在较深层学习构造和语义特色。这一结论与以往的研究同等。
从每个任务的角度来看,Adapter-BERT在LEN上始终保持较高的精度,而所有其他模型都丢弃了一些表面信息。这个调查任务显示了源代码和自然措辞预演习模型在处理代码下贱任务方面的差异。在CPX任务中,GraphCodeBERT在浅层隐蔽层中保持了较高的准确性,这证明了GraphCodeBERT对构造信息进行了充分的编码。然而,CPX的性能在末了隐蔽层显著低落。下贱任务可能不须要涉及圈繁芜度信息。
在TYP任务中,经由适配器调优的不同模型终极具有较高的准确性,并且该语义信息可以有效地参与下贱任务。准确度的变革在GraphCodeBERT上始终是最好的,其次是CodeBERT,然后是BERT。这也与预演习模型不才游任务中的表现相吻合。
创造5:在所有探测任务上,适配器调优明显优于全模型调优。此外,我们不雅观察到这些模型的隐蔽层从浅到深逐渐编码更高等别的信息,与之前的研究同等。
转述:韩廷旭















