
kubernetes中的统统都可以理解为是一种资源工具,pod,rc,service,都可以理解是 一种资源工具。pod的组成示意图如下,由一个叫”pause“的根容器,加上一个或多个用户自定义的容器布局。pause的状态代表了这一组容器的状态,pod里多个业务容器共享pod的Ip和数据卷。在kubernetes环境下,pod是容器的载体,所有的容器都是在pod中被管理,一个或多个容器放在pod里作为一个单元方便管理。
Pod是kubernetes可以支配和管理的最小单元,如果想要运行一个容器,先要为这个容器创建一个pod。同时一个pod也可以包含多个容器,之以是多个容器包含在一个pod里,每每是由于业务上的紧密耦合。

【须要把稳】这里说的场景都非必须把不同的容器放在同一个pod里,但是这样每每更便于管理,乃至后面会讲到的,紧密耦合的业务容器放置在同一个容器里通信效率更高。详细怎么利用还要看实际情形,综合权衡。
在Kubrenetes集群中Pod有如下两种利用办法:a)一个Pod中运行一个容器。这是最常见的用法。
在这种办法中,你可以把Pod想象成是单个容器的封装,kuberentes管理的是Pod而不是直接管理容器。b)在一个Pod中同时运行多个容器。
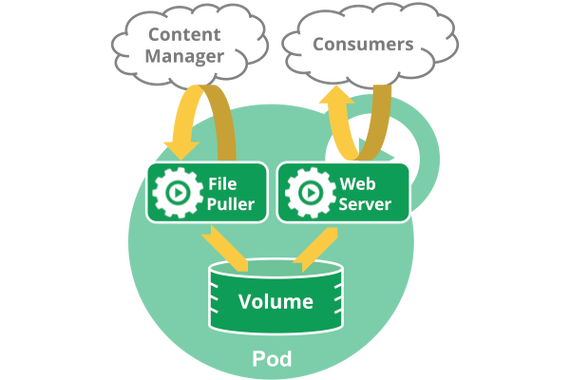
当多个运用之间是紧耦合的关系时,可以将多个运用一起放在一个Pod中,同个Pod中的多个容器之间相互访问可以通过localhost来通信(可以把Pod理解成一个虚拟机,共享网络和存储卷)。也便是说一个Pod中也可以同时封装几个须要紧密耦合相互协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以相互协作成为一个service单位 (即一个容器共享文件),另一个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理。
就像每个运用容器,pod被认为是临时实体。在Pod的生命周期中,pod被创建后,被分配一个唯一的ID(UID),调度到节点上,并同等坚持期望的状态直到被闭幕(根据重启策略)或者被删除。如果node去世掉了,分配到了这个node上的pod,在经由一个超时时间后会被重新调度到其他node节点上。一个给定的pod(如UID定义的)不会被“重新调度”到新的节点上,而是被一个同样的pod取代,如果期望的话乃至可以是相同的名字,但是会有一个新的UID(查看replication controller获取详情)。
(1)kubernetes为什么利用pod作为最小单元,而不是container
直接支配一个容器看起来更大略,但是这里也有更好的缘故原由为什么在容器根本上抽象一层呢?根本缘故原由是为了管理容器,kubernetes须要更多的信息,比如重启策略,它定义了容器终止后要采纳的策略;或者是一个可用性探针,从运用程序的角度去探测是否一个进程还存活着。基于这些缘故原由,kubernetes架构师决定利用一个新的实体,也便是pod,而不是重载容器的信息添加更多属性,用来在逻辑上包装一个或者多个容器的管理所须要的信息。
(2)kubernetes为什么许可一个pod里有多个容器
Pod里的容器运行在一个逻辑上的"主机"上,它们利用相同的网络名称空间 (即同一pod里的容器利用相同的ip和相同的端口段区间) 和相同的IPC名称空间。它们也可以共享存储卷。这些特性使它们可以更有效的通信,并且pod可以使你把紧密耦合的运用容器作为一个单元来管理。也便是说当多个运用之间是紧耦合关系时,可以将多个运用一起放在一个Pod中,同个Pod中的多个容器之间相互访问可以通过localhost来通信(可以把Pod理解成一个虚拟机,共享网络和存储卷)。
因此当一个运用如果须要多个运行在同一主机上的容器时,为什么不把它们放在同一个容器里呢?首先,这样何故违反了一个容器只卖力一个运用的原则。这点非常主要,如果我们把多个运用放在同一个容器里,这将使办理问题变得非常麻烦,由于它们的日志记录稠浊在了一起,并且它们的生命周期也很难管理。因此一个运用利用多个容器将更大略,更透明,并且使运用依赖解偶。并且粒度更小的容器更便于不同的开拓团队共享和复用。
【须要把稳】这里说到为理解偶把运用分别放在不同容器里,前面我们也强调为了便于管理管紧耦合的运用把它们的容器放在同一个pod里。一下子强调耦合,一下子强调度偶看似抵牾,实际上普遍存在,高内聚低耦合是我们的追求,然而一个运用的业务逻辑模块不可能完备完独立不存在耦合,这就须要我们从实际上来考量,做出决策。
由于,虽然可以利用一个pod来承载一个多层运用,但是更建议利用不同的pod来承载不同的层,因这这样你可以为每一个层单独扩容并且把它们分布到集群的不同节点上。
(3)Pod中如何管理多个容器Pod中可以同时运行多个进程(作为容器运行)协同事情,同一个Pod中的容器会自动地分配到同一个 node 上,同一个Pod中的容器共享资源、网络环境和依赖,它们总是被同时调度。须要把稳:一个Pod中同时运行多个容器是一种比较高等的用法。只有当你的容器须要紧密合营协作的时候才考虑用这种模式。
Pod中共享的环境包括Linux的namespace,cgroup和其他可能的隔绝环境,这一点跟Docker容器同等。在Pod的环境中,每个容器中可能还有更小的子隔离环境。Pod中的容器共享IP地址和端口号,它们之间可以通过localhost相互创造。它们之间可以通过进程间通信,须要明白的是同一个Pod下的容器是通过lo网卡进行通信。例如SystemV旗子暗记或者POSIX共享内存。不同Pod之间的容用具有不同的IP地址,不能直接通过IPC通信。Pod中的容器也有访问共享volume的权限,这些volume会被定义成pod的一部分并挂载到运用容器的文件系统中。
总而言之。Pod中可以共享两种资源:网络 和 存储1. 网络:每个Pod都会被分配一个唯一的IP地址。Pod中的所有容器共享网络空间,包括IP地址和端口。Pod内部的容器可以利用localhost相互通信。Pod中的容器与外界通信时,必须分配共享网络资源(例如利用宿主机的端口映射)。2. 存储:可以Pod指定多个共享的Volume。Pod中的所有容器都可以访问共享的volume。Volume也可以用来持久化Pod中的存储资源,以防容看重启后文件丢失。
容器的依赖关系和启动顺序当前,同一个pod里的所有容器都是并行启动并且没有办法确定哪一个容器必须早于哪一个容器启动。如果要想确保第一个容器早于第二个容器启动,那么就要利用到"init container"了。
同一pod的容器间网络通信同一pod下的容器利用相同的网络名称空间,这就意味着他们可以通过"localhost"来进行通信,它们共享同一个Ip和相同的端口空间。
同一个pod暴露多个容器常日pod里的容器监听不同的端口,想要被外部访问都须要暴露出去.你可以通过在一个做事里暴露多个端口或者利用不同的做事来暴露不同的端口来实现。
Pod的yaml格式定义配置文件解释YAML格式的Pod定义文件的完全内容如下:
apiVersion: v1 # 必选,版本号kind: Pod # 必选,Podmetadata: # 必选,元数据 name: String # 必选,Pod名称 namespace: String # 必选,Pod所属的命名空间 labels: # 自定义标签,Map格式 Key: Value # 键值对 annotations: # 自定义表明 Key: Value # 键值对spec: # 必选,Pod中容器的详细属性 containers: # 必选,Pod中容器列表 - name: String # 必选,容器名称 image: String # 必选,容器的镜像地址和名称 imagePullPolicy: {Always | Never | IfNotPresent} # 获取镜像的策略,Always表示下载镜像,IfnotPresent 表示优先利用本地镜像,否则下载镜像,Never表示仅利用本地镜像。 command: [String] # 容器的启动命令列表(覆盖),如不指定,利用打包镜像时的启动命令。 args: [String] # 容器的启动命令参数列表 workingDir: String # 容器的事情目录 volumeMounts: # 挂载到容器内部的存储卷配置 - name: String # 引用Pod定义的共享存储卷的名,需用Pod.spec.volumes[]部分定义的卷名 mountPath: String # 存储卷在容器内Mount的绝对路径,应少于512字符 readOnly: boolean # 是否为只读模式 ports: # 容器须要暴露的端口库号列表 - name: String # 端口号名称 containerPort: Int # 容器须要监听的端口号 hostPort: Int # 可选,容器所在主机须要监听的端口号,默认与Container相同 env: # 容器运行前需设置的环境变量列表 - name: String # 环境变量名称 value: String # 环境变量的值 resources: # 资源限定和要求的设置 limits: # 资源限定的设置 cpu: String # Cpu的限定,单位为Core数,将用于docker run --cpu-shares参数,如果整数后跟m,表示占用权重,1Core=1000m memory: String # 内存限定,单位可以为Mib/Gib,将用于docker run --memory参数 requests: # 资源要求的设置 cpu: string # CPU要求,容器启动的初始可用数量 memory: string # 内存要求,容器启动的初始可用数量 livenessProbe: # 对Pod内容器康健检讨设置,当探测无相应几次后将自动重启该容器,检讨方法有exec、httpGet和tcpSocket,对一个容器只需设置个中一种方法即可。 exec: # 对Pod容器内检讨办法设置为exec办法 command: [String] # exec办法须要制订的命令或脚本 httpGet: # 对Pod容器内检讨办法设置为HttpGet办法,须要指定path、port path: String # 网址URL路径(去除对应的域名或IP地址的部分) port: Int # 对应端口 host: String # 域名或IP地址 schema: String # 对应的检测协议,如http HttpHeaders: # 指定报文头部信息 - name: String value: String tcpSocket: # 对Pod容器内检讨办法设置为tcpSocket办法 port: Int initialDelaySeconds: Int # 容器启动完成后首次探测的韶光,单位为秒 timeoutSeconds: Int # 对容器康健检讨探测等待相应的超时时间,单位为秒,默认为1秒 periodSeconds: Int # 对容器监控检讨的定期探测韶光设置,单位为秒,默认10秒一次 successThreshold: Int # 探测几次成功后认为成功 failureThreshold: Int # 探测几次失落败后认为失落败 securityContext: privileged: false restartPolicy: {Always | Never | OnFailure} # Pod的重启策略,Always表示一旦不管以何种办法终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码才重启,Nerver表示不再重启该Pod nodeSelector: # 设置NodeSelector表示将该Pod调度到包含这个label的node上,以Key:Value的格式指定 Key: Value # 调度到指定的标签Node上 imagePullSecrets: # Pull镜像时利用的secret名称,以Key:SecretKey格式指定 - name: String hostNetwork: false # 是否利用主机网络模式,默认为false,如果设置为true,表示利用宿主机网络 volumes: # 在该Pod上定义共享存储卷列表 - name: String # 共享存储卷名称(Volumes类型有多种) emptyDir: { } # 类型为emptyDir的存储卷,与Pod同生命周期的一个临时目录,为空值 hostPath: String # 类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录 path: String # Pod所在宿主机的目录,将被用于同期中Mount的目录 secret: # 类型为Secret的存储卷,挂载集群与定义的Secret工具到容器内部 secretname: String items: # 当仅需挂载一个Secret工具中的指定Key时利用 - key: String path: String configMap: # 类型为ConfigMap的存储卷,挂载预定义的ConfigMap工具到容器内部 name: String items: # 当仅需挂载一个ConfigMap工具中的指定Key时利用 - key: String path: String
# kubectl get pod podname -n namespace -o wide # 查看pod分布在哪些node节点上
# kubectl get pod podname -n namespace -o yaml # 查看pod的yml配置情形
2.1.4.2 如何利用Pod常日把Pod分为两类:- 自主式Pod :这种Pod本身是不能自我修复的,当Pod被创建后(不论是由你直接创建还是被其他Controller),都会被Kuberentes调度到集群的Node上。直到Pod的进程终止、被删掉、由于短缺资源而被驱逐、或者Node故障之前这个Pod都会一贯保持在那个Node上。Pod不会自愈。如果Pod运行的Node故障,或者是调度器本身故障,这个Pod就会被删除。同样的,如果Pod所在Node短缺资源或者Pod处于掩护状态,Pod也会被驱逐。- 掌握器管理的Pod:Kubernetes利用更高等的称为Controller的抽象层,来管理Pod实例。Controller可以创建和管理多个Pod,供应副本管理、滚动升级和集群级别的自愈能力。例如,如果一个Node故障,Controller就能自动将该节点上的Pod调度到其他康健的Node上。虽然可以直策应用Pod,但是在Kubernetes中常日是利用Controller来管理Pod的。如下图:
Kubernetes设计这样的Pod观点和分外组成构造有什么用意呢?缘故原由一:在一组容器作为一个单元的情形下,难以对整体的容器大略地进行判断及有效地进行行动。比如一个容器去世亡了,此时是算整体挂了么?那么引入与业务无关的Pause容器作为Pod的根容器,以它的状态代表着全体容器组的状态,这样就可以办理该问题。缘故原由二:Pod里的多个业务容器共享Pause容器的IP,共享Pause容器挂载的Volume,这样简化了业务容器之间的通信问题,也办理了容器之间的文件共享问题。
(1) Pod的持久性和终止- Pod的持久性Pod在设计上就不是作为持久化实体的。在调度失落败、节点故障、短缺资源或者节点掩护的状态下都会去世掉会被驱逐。常日,用户不须要手动直接创建Pod,而是该当利用controller(例如Deployments),纵然是在创建单个Pod的情形下。Controller可以供应集群级别的自愈功能、复制和升级管理。
- Pod的终止由于Pod作为在集群的节点上运行的进程,以是在不再须要的时候能够优雅的终止掉是十分必要的(比起利用发送KILL旗子暗记这种暴力的办法)。用户须要能够放松删除要求,并且知道它们何时会被终止,是否被精确的删除。用户想终止程序时发送删除pod的要求,在pod可以被逼迫删除前会有一个脱期日,会发送一个TERM要求到每个容器的主进程。一旦超时,将向主进程发送KILL旗子暗记并从API server中删除。如果kubelet或者container manager在等待进程终止的过程中重启,在重启后仍旧会重试完全的脱期日。
示例流程如下:- 用户发送删除pod的命令,默认脱期日是30秒;- 在Pod超过该脱期日后API server就会更新Pod的状态为"dead";- 在客户端命令行上显示的Pod状态为"terminating";- 跟第三步同时,当kubelet创造pod被标记为"terminating"状态时,开始停滞pod进程:1. 如果在pod中定义了preStop hook,在停滞pod前会被调用。如果在脱期日过后,preStop hook依然在运行,第二步会再增加2秒的脱期日;2. 向Pod中的进程发送TERM旗子暗记;- 跟第三步同时,该Pod将从该service的端点列表中删除,不再是replication controller的一部分。关闭的慢的pod将连续处理load balancer转发的流量;- 过了脱期日后,将向Pod中依然运行的进程发送SIGKILL旗子暗记而杀掉进程。- Kublete会在API server中完成Pod的的删除,通过将优雅周期设置为0(立即删除)。Pod在API中消逝,并且在客户端也不可见。
删除脱期日默认是30秒。 kubectl delete命令支持 --grace-period=<seconds> 选项,许可用户设置自己的脱期日。如果设置为0将逼迫删除pod。在kubectl>=1.5版本的命令中,你必须同时利用 --force 和 --grace-period=0 来逼迫删除pod。
Pod的逼迫删除是通过在集群和etcd中将其定义为删除状态。当实行逼迫删除命令时,API server不会等待该pod所运行在节点上的kubelet确认,就会立即将该pod从API server中移除,这时就可以创建跟原pod同名的pod了。这时,在节点上的pod会被立即设置为terminating状态,不过在被逼迫删除之前依然有一小段优雅删除周期。【须要把稳:如果删除一个pod后,再次查看创造pod还在,这是由于在deployment.yaml文件中定义了副本数量!
还须要删除deployment才行。即:"kubectl delete pod pod-name -n namespace" && "kubectl delete deployment deployment-name -n namespace"】
Pause容器,又叫Infra容器。我们检讨node节点的时候会创造每个node节点上都运行了很多的pause容器,例如如下:
[root@k8s-node01 ~]# docker ps |grep pause0cbf85d4af9e k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_myapp-848b5b879b-ksgnv_default_0af41a40-a771-11e8-84d2-000c2972dc1f_0d6e4d77960a7 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_myapp-848b5b879b-5f69p_default_09bc0ba1-a771-11e8-84d2-000c2972dc1f_05f7777c55d2a k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_kube-flannel-ds-pgpr7_kube-system_23dc27e3-a5af-11e8-84d2-000c2972dc1f_18e56ef2564c2 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_client2_default_17dad486-a769-11e8-84d2-000c2972dc1f_17815c0d69e99 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_nginx-deploy-5b595999-872c7_default_7e9df9f3-a6b6-11e8-84d2-000c2972dc1f_2b4e806fa7083 k8s.gcr.io/pause:3.1 "/pause" 7 days ago Up 7 days k8s_POD_kube-proxy-vxckf_kube-system_23dc0141-a5af-11e8-84d2-000c2972dc1f_2
kubernetes中的pause容器紧张为每个业务容器供应以下功能:- 在pod中担当Linux命名空间共享的根本;- 启用pid命名空间,开启init进程;
示例如下:
[root@k8s-node01 ~]# docker run -d --name pause -p 8880:80 k8s.gcr.io/pause:3.1 [root@k8s-node01 ~]# docker run -d --name nginx -v `pwd`/nginx.conf:/etc/nginx/nginx.conf --net=container:pause --ipc=container:pause --pid=container:pause nginx [root@k8s-node01 ~]# docker run -d --name ghost --net=container:pause --ipc=container:pause --pid=container:pause ghost
现在访问http://:8880/就可以看到ghost博客的界面了。
解析解释: pause容器将内部的80端口映射到宿主机的8880端口,pause容器在宿主机上设置好了网络namespace后,nginx容器加入到该网络namespace中,我们看到nginx容器启动的时候指定了 --net=container:pause,ghost容器同样加入到了该网络namespace中,这样三个容器就共享了网络,相互之间就可以利用localhost直接通信, --ipc=contianer:pause --pid=container:pause便是三个容器处于同一个namespace中,init进程为pause
这时我们进入到ghost容器中查看进程情形。
[root@k8s-node01 ~]# docker exec -it ghost /bin/bashroot@d3057ceb54bc:/var/lib/ghost# ps axuUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot 1 0.0 0.0 1012 4 ? Ss 03:48 0:00 /pauseroot 6 0.0 0.0 32472 780 ? Ss 03:53 0:00 nginx: master process nginx -g daemon off;systemd+ 11 0.0 0.1 32932 1700 ? S 03:53 0:00 nginx: worker processnode 12 0.4 7.5 1259816 74868 ? Ssl 04:00 0:07 node current/index.jsroot 77 0.6 0.1 20240 1896 pts/0 Ss 04:29 0:00 /bin/bashroot 82 0.0 0.1 17496 1156 pts/0 R+ 04:29 0:00 ps axu
在ghost容器中同时可以看到pause和nginx容器的进程,并且pause容器的PID是1。而在kubernetes中容器的PID=1的进程即为容器本身的业务进程。
(3) Init容器Pod 能够具有多个容器,运用运行在容器里面,但是它也可能有一个或多个先于运用容器启动的 Init 容器。init容器是一种专用的容器,在运用容器启动之前运行,可以包含普通容器映像中不存在的运用程序或安装脚本。init容器会优先启动,待里面的任务完成后容器就会退出。 init容器配置示例如下:
apiVersion: v1kind: Podmetadata: name: init-demospec: containers: - name: nginx image: nginx ports: - containerPort: 80 volumeMounts: - name: workdir mountPath: /usr/share/nginx/html # These containers are run during pod initialization initContainers: - name: install image: busybox command: - wget - "-O" - "/work-dir/index.html" - http://kubernetes.io volumeMounts: - name: workdir mountPath: "/work-dir" dnsPolicy: Default volumes: - name: workdir emptyDir: {}
1. 理解init容器- 它们总是运行到完成。- 每个都必须不才一个启动之前成功完成。- 如果 Pod 的 Init 容器失落败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。然而,如果 Pod 对应的 restartPolicy 为 Never,它不会重新启动。- Init 容器支持运用容器的全部字段和特性,但不支持 Readiness Probe,由于它们必须在 Pod 就绪之前运行完成。- 如果为一个 Pod 指定了多个 Init 容器,那些容器会按顺序一次运行一个。 每个 Init 容器必须运行成功,下一个才能够运行。- 由于 Init 容器可能会被重启、重试或者重新实行,以是 Init 容器的代码该当是幂等的。 特殊地,被写到 EmptyDirs 中文件的代码,该当对输出文件可能已经存在做好准备。- 在 Pod 上利用 activeDeadlineSeconds,在容器上利用 livenessProbe,这样能够避免 Init 容器一贯失落败。 这就为 Init 容器生动设置了一个期限。- 在 Pod 中的每个 app 和 Init 容器的名称必须唯一;与任何其它容器共享同一个名称,会在验证时抛出错误。- 对 Init 容器 spec 的修正,被限定在容器 image 字段中。 变动 Init 容器的 image 字段,等价于重启该 Pod。
一个pod可以包含多个普通容器和多个init容器,在Pod中所有容器的名称必须唯一,init容器在普通容器启动上次序实行,如果init容器失落败,则认为pod失落败,K8S会根据pod的重启策略来重启这个容器,直到成功。
Init容器须要在pod.spec中的initContainers数组中定义(与pod.spec.containers数组相似)。init容器的状态在.status.initcontainerStatus字段中作为容器状态的数组返回(与status.containerStatus字段类似)。init容器支持普通容器的所有字段和功能,除了readinessprobe。Init 容器只能修正image 字段,修正image 字段即是重启 Pod,Pod 重启所有Init 容器必须重新实行。
如果Pod的Init容器失落败,Kubernetes会不断地重启该Pod,直到Init容器成功为止。然而如果Pod对应的restartPolicy为Never,则它不会重新启动。以是在Pod上利用activeDeadlineSeconds,在容器上利用livenessProbe,相称于为Init容器生动设置了一个期限,能够避免Init容器一贯失落败。
2. Init容器与普通容器的不同之处Init 容器与普通的容器非常像,除了如下两点:- Init 容器总是运行到成功完成为止。- 每个 Init 容器都必须不才一个 Init 容器启动之前成功完成。
Init 容器支持运用容器的全部字段和特性,包括资源限定、数据卷和安全设置。 然而,Init 容器对资源要乞降限定的处理稍有不同, 而且 Init 容器不支持 Readiness Probe,由于它们必须在 Pod 就绪之前运行完成。如果为一个 Pod 指定了多个 Init 容器,那些容器会按顺序一次运行一个。 每个 Init 容器必须运行成功,下一个才能够运行。 当所有的 Init 容器运行完成时,Kubernetes 初始化 Pod 并像平常一样运行运用容器。
3. Init 容器能做什么由于 Init 容用具有与运用容器分离的单独镜像,它们的启动干系代码具有如下上风:- 它们可以包含并运行实用工具,处于安全考虑,是不建议在运用容器镜像中包含这些实用工具的。- 它们可以包含实用工具和定制化代码来安装,但不能涌如今运用镜像中。例如创建镜像没必要FROM另一个镜像,只须要在安装中利用类似sed,awk、 python 或dig这样的工具。- 运用镜像可以分离出创建和支配的角色,而没有必要联合它们构建一个单独的镜像。- 它们利用 Linux Namespace,以是对运用容用具有不同的文件系统视图。因此,它们能够具有访问 Secret 的权限,而运用容器不能够访问。- 它们在运用容器启动之前运行完成,然而运用容器并走运行,以是 Init 容器供应了一种大略的办法来壅塞或延迟运用容器的启动,直到知足了一组先决条件。
(4) 静态pod静态Pod是由kubelet进行管理,仅存在于特定Node上的Pod。它们不能通过API Server进行管理,无法与ReplicationController、Deployment或DaemonSet进行关联,并且kubelet也无法对其康健检讨。静态Pod总是由kubelet创建,并且总在kubelet所在的Node上运行。创建静态Pod的办法:利用配置文件办法 或 HTTP办法。一样平常常利用的是配置文件办法。
- 通过配置文件创建
配置文件只是特定目录中json或yaml格式的标准pod定义。它通过在kubelet守护进程中添加配置参数--pod-manifest-path=<the directory> 来运行静态Pod,kubelet常常会它定期扫描目录;例如,如何将一个大略web做事作为静态pod启动?
选择运行静态pod的节点做事器,不一定是node节点,只要有kubelet进程所在的节点都可以运行静态pod。可以在某个节点上创建一个放置一个Web做事器pod定义的描述文件文件夹,例如/etc/kubelet.d/static-web.yaml
# mkdir /etc/kubelet.d/# vim /etc/kubelet.d/static-web.yamlapiVersion: v1kind: Podmetadata: name: static-web labels: role: myrolespec: containers: - name: web image: nginx ports: - name: web containerPort: 80 protocol: TCP #ls /etc/kubelet.d/static-web.yaml
通过利用--pod-manifest-path=/etc/kubelet.d/参数运行它,在节点上配置我的kubelet守护程序以利用此目录。比如这里kubelet启动参数位/etc/systemd/system/kubelet.service.d/10-kubelet.conf, 修正配置,然后将参数加入到现有参数配置项中(安装办法不尽相同,但是道理一样)。
# vim /etc/systemd/system/kubelet.service.d/10-kubelet.conf············Environment=``"KUBELET_EXTRA_ARGS=--cluster-dns=10.96.0.10 --cluster-domain=cluster.local --pod-manifest-path=/etc/kubelet.d/"············
保存退出,reload一下systemd daeomon ,重启kubelet做事进程。
# systemctl daemon-reload# systemctl restart kubelet
前面说了,当kubelet启动时,它会自动启动在指定的目录–pod-manifest-path=或–manifest-url=参数中定义的所有pod ,即我们的static-web。接着在该节点上检讨是否创建成功:
# kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE static-web-k8s-m1 1/1 Running 0 2m 10.244.2.32 k8s-m1
上面也提到了,它不归任何支配办法来管理,纵然我们考试测验kubelet命令去删除。
# kubectl delete pod static-web-k8s-m1pod "static-web-k8s-m1" deleted # kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODEstatic-web-k8s-m1 0/1 Pending 0 2s <none> k8s-m1 <none>
可以看出静态pod通过这种办法是没法删除的
那我如何去删除或者说是动态的添加一个pod呢?这种机制已经知道,kubelet进程会定期扫描配置的目录(/etc/kubelet.d在我的示例)以进行变动,并在文件涌现/消逝在此目录中时添加/删除pod。
(5) Pod容器共享Volume同一个Pod中的多个容器可以共享Pod级别的存储卷Volume,Volume可以定义为各种类型,多个容器各自进行挂载,将Pod的Volume挂载为容器内部须要的目录。例如:Pod级别的Volume:"app-logs",用于tomcat向个中写日志文件,busybox读日志文件。
pod-volumes-applogs.yaml文件的配置内容
apiVersion: v1kind: Podmetadata: name: volume-podspec: containers: - name: tomcat image: tomcat ports: - containerPort: 8080 volumeMounts: - name: app-logs mountPath: /usr/local/tomcat/logs - name: busybox image: busybox command: ["sh","-c","tailf /logs/catalina.log"] volumeMounts: - name: app-logs mountPath: /logs volumes: - name: app-logs emptyDir: {}
查看日志
# kubectl logs <pod_name> -c <container_name>
# kubectl exec -it <pod_name> -c <container_name> – tail /usr/local/tomcat/logs/catalina.xx.log
(6) Pod的配置管理Kubernetes v1.2的版本供应统一的集群配置管理方案 – ConfigMap:容器运用的配置管理
ConfigMap利用场景:- 天生为容器内的环境变量。- 设置容器启动命令的启动参数(需设置为环境变量)。- 以Volume的形式挂载为容器内部的文件或目录。
ConfigMap以一个或多个key:value的形式保存在kubernetes系统中供应用利用,既可以表示一个变量的值(例如:apploglevel=info),也可以表示完全配置文件的内容(例如:server.xml=<?xml…>…)。可以通过yaml配置文件或者利用kubectl create configmap命令的办法创建ConfigMap。
6.1)创建ConfigMap[1] 通过yaml文件的办法cm-appvars.yaml
apiVersion: v1kind: ConfigMapmetadata: name: cm-appvarsdata: apploglevel: info appdatadir: /var/data
常用命令# kubectl create -f cm-appvars.yaml# kubectl get configmap# kubectl describe configmap cm-appvars# kubectl get configmap cm-appvars -o yaml
[2] 通过kubectl命令行办法
通过kubectl create configmap创建,利用参数–from-file或–from-literal指定内容,可以在一行中指定多个参数。
1)通过–from-file参数从文件中进行创建,可以指定key的名称,也可以在一个命令行中创建包含多个key的ConfigMap。
# kubectl create configmap NAME --from-file=[key=]source --from-file=[key=]source
2)通过–from-file参数从目录中进行创建,该目录下的每个配置文件名被设置为key,文件内容被设置为value。
# kubectl create configmap NAME --from-file=config-files-dir
3)通过–from-literal从文本中进行创建,直接将指定的key=value创建为ConfigMap的内容。
# kubectl create configmap NAME --from-literal=key1=value1 --from-literal=key2=value2
6.2)容器运用对ConfigMap的利用有两种方法:- 通过环境变量获取ConfigMap中的内容。- 通过Volume挂载的办法将ConfigMap中的内容挂载为容器内部的文件或目录。
[1] 通过环境变量的办法
ConfigMap的yaml文件: cm-appvars.yaml
apiVersion: v1kind: ConfigMapmetadata: name: cm-appvarsdata: apploglevel: info appdatadir: /var/dataPod的yaml文件:cm-test-pod.yaml
apiVersion: v1kind: Podmetadata: name: cm-test-podspec: containers: - name: cm-test image: busybox command: ["/bin/sh","-c","env|grep APP"] env: - name: APPLOGLEVEL valueFrom: configMapKeyRef: name: cm-appvars key: apploglevel - name: APPDATADIR valueFrom: configMapKeyRef: name: cm-appvars key: appdatadir创建命令:# kubectl create -f cm-test-pod.yaml# kubectl get pods --show-all# kubectl logs cm-test-pod
利用ConfigMap的限定条件- ConfigMap必须在Pod之前创建- ConfigMap也可以定义为属于某个Namespace。只有处于相同Namespace中的Pod可以引用它。- kubelet只支持可以被API Server管理的Pod利用ConfigMap。静态Pod无法引用。- 在Pod对ConfigMap进行挂载操作时,容器内只能挂载为“目录”,无法挂载为文件。
(7) Pod的生命周期[1] Pod的状态
pod从创建到末了的创建成功会分别处于不同的阶段,下面是Pod的生命周期示意图,从图中可以看到Pod状态的变革:
挂起或等待中 (Pending):API Server创建了Pod资源工具并已经存入了etcd中,但是它并未被调度完成,或者仍旧处于从仓库下载镜像的过程中。这时候Pod 已被 Kubernetes 系统接管,但有一个或者多个容器镜像尚未创建。等待韶光包括调度 Pod 的韶光和通过网络下载镜像的韶光,这可能须要花点韶光。创建pod的要求已经被k8s接管,但是容器并没有启动成功,可能处在:写数据到etcd,调度,pull镜像,启动容器这四个阶段中的任何一个阶段,pending伴随的事宜常日会有:ADDED, Modified这两个事宜的产生。运行中 (Running):该 Pod 已经被调度到了一个node节点上,Pod 中所有的容器都已被kubelet创建完成。至少有一个容器正在运行,或者正处于启动或重启状态。正常终止 (Succeeded):pod中的所有的容器已经正常的自行退出,并且k8s永久不会自动重启这些容器,一样平常会是在支配job的时候会涌现。非常停滞 (Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是由于失落败终止。也便是说,容器以非0状态退出或者被系统终止。未知状态 (Unkonwn):出于某种缘故原由,无法得到Pod的状态,常日是由于与Pod主机通信时出错。
[2] Pod的创建过程
Pod是Kubernetes的根本单元,理解其创建的过程,更有助于理解系统的运作。创建Pod的全体流程的时序图如下:
① 用户通过kubectl客户端提交Pod Spec给API Server。② API Server考试测验将Pod工具的干系信息存储到etcd中,等待写入操作完成,API Server返回确认信息到客户端。③ API Server开始反响etcd中的状态变革。④ 所有的Kubernetes组件通过"watch"机制跟踪检讨API Server上的干系信息变动。⑤ kube-scheduler(调度器)通过其"watcher"检测到API Server创建了新的Pod工具但是没有绑定到任何事情节点。⑥ kube-scheduler为Pod工具挑选一个事情节点并将结果信息更新到API Server。⑦ 调度结果新由API Server更新到etcd,并且API Server也开始反馈该Pod工具的调度结果。⑧ Pod被调度到目标事情节点上的kubelet考试测验在当前节点上调用docker engine进行启动容器,并将容器的状态结果返回到API Server。⑨ API Server将Pod信息存储到etcd系统中。⑩ 在etcd确认写入操作完成,API Server将确认信息发送到干系的kubelet。
Pod常规的排查:「链接」
一个pod的完全创建,常日会伴随着各种事宜的产生,kubernetes事宜的种类统共只有4种:
Added EventType = "ADDED"Modified EventType = "MODIFIED"Deleted EventType = "DELETED"Error EventType = "ERROR"
PodStatus 有一组PodConditions。 PodCondition中的ConditionStatus,它代表了当前pod是否处于某一个阶段(PodScheduled,Ready,Initialized,Unschedulable),"true" 表示处于,"false"表示不处于。PodCondition数组的每个元素都有一个类型字段和一个状态字段。
类型字段 PodConditionType 是一个字符串,可能的值是:PodScheduled:pod正处于调度中,刚开始调度的时候,hostip还没绑定上,持续调度之后,有得当的节点就会绑定hostip,然后更新etcd数据Ready: pod 已经可以开始做事,譬如被加到负载均衡里面Initialized:所有pod 中的初始化容器已经完成了Unschedulable:限定不能被调度,譬如现在资源不敷
状态字段 ConditionStatus 是一个字符串,可能的值为True,False和Unknown
Pod的ERROR事宜的情形大概有:CrashLoopBackOff: 容器退出,kubelet正在将它重启InvalidImageName: 无法解析镜像名称ImageInspectError: 无法校验镜像ErrImageNeverPull: 策略禁止拉取镜像ImagePullBackOff: 正在重试拉取RegistryUnavailable: 连接不到镜像中央ErrImagePull: 通用的拉取镜像出错CreateContainerConfigError: 不能创建kubelet利用的容器配置CreateContainerError: 创建容器失落败m.internalLifecycle.PreStartContainer 实行hook报错RunContainerError: 启动容器失落败PostStartHookError: 实行hook报错ContainersNotInitialized: 容器没有初始化完毕ContainersNotReady: 容器没有准备完毕ContainerCreating:容器创建中PodInitializing:pod 初始化中DockerDaemonNotReady:docker还没有完备启动NetworkPluginNotReady: 网络插件还没有完备启动
[3] Pod的重启策略
PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never。默认为 Always。 restartPolicy 适用于 Pod 中的所有容器。restartPolicy 仅指通过同一节点上的 kubelet 重新启动容器。失落败的容器由 kubelet 以五分钟为上限的指数退避延迟(10秒,20秒,40秒...)重新启动,并在成功实行十分钟后重置。pod一旦绑定到一个节点,Pod 将永久不会重新绑定到另一个节点(除非删除这个pod,或pod所在的node节点发生故障或该node从集群中退出,则pod才会被调度到其他node节点上)。
解释: 可以管理Pod的掌握器有Replication Controller,Job,DaemonSet,及kubelet(静态Pod)。- RC和DaemonSet:必须设置为Always,须要担保该容器持续运行。- Job:OnFailure或Never,确保容器实行完后不再重启。- kubelet:在Pod失落效的时候重启它,不论RestartPolicy设置为什么值,并且不会对Pod进行康健检讨。
常见的状态转换场景:
(8) Pod康健检讨 (存活性探测)
在pod生命周期中可以做的一些事情。主容器启动前可以完成初始化容器,初始化容器可以有多个,他们是串行实行的,实行完成后就退出了,在主程序刚刚启动的时候可以指定一个post start 主程序启动开始后实行一些操作,在主程序结束前可以指定一个 pre stop 表示主程序结束前实行的一些操作。Pod启动后的康健状态可以由两类探针来检测:Liveness Probe(存活性探测) 和 Readiness Probe(就绪性探测)。如下图:
[1] Liveness Probe1. 用于判断容器是否存活(running状态)。2. 如果LivenessProbe探针探测到容器非康健,则kubelet将杀掉该容器,并根据容器的重启策略做相应处理。3. 如果容器不包含LivenessProbe探针,则kubelet认为该探针的返回值永久为“success”。
livenessProbe:指示容器是否正在运行。如果存活探测失落败,则 kubelet 会杀去世容器,并且容器将受到其 重启策略 的影响。如果容器不供应存活探针,则默认状态为 Success。Kubelet利用liveness probe(存活探针)来确定何时重启容器。例如,当运用程序处于运行状态但无法做进一步操作,liveness探针将捕获到deadlock,重启处于该状态下的容器,使运用程序在存在bug的情形下依然能够连续运行下去(谁的程序还没几个bug呢)。
[2] Readiness Probe1. 用于判断容器是否启动完成(read状态),可以接管要求。2. 如果ReadnessProbe探针检测失落败,则Pod的状态将被修正。Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的Endpoint。
readinessProbe:指示容器是否准备好做事要求。如果就绪探测失落败,端点掌握器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不供应就绪探针,则默认状态为 Success。Kubelet利用readiness probe(就绪探针)来确定容器是否已经就绪可以接管流量。只有当Pod中的容器都处于就绪状态时kubelet才会认定该Pod处于就绪状态。该旗子暗记的浸染是掌握哪些Pod该当作为service的后端。如果Pod处于非就绪状态,那么它们将会被从service的load balancer中移除。
Kubelet 可以选择是否实行在容器上运行的两种探针实行和做出反应,每次探测都将得到以下三种结果之一:成功:容器通过了诊断。失落败:容器未通过诊断。未知:诊断失落败,因此不会采纳任何行动。
探针是由 kubelet 对容器实行的定期诊断。要实行诊断,kubelet 调用由容器实现的Handler。其存活性探测的方法有以下三种:- ExecAction:在容器内实行指定命令。如果命令退出时返回码为 0 则认为诊断成功。- TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检讨。如果端口打开,则诊断被认为是成功的。- HTTPGetAction:对指定的端口和路径上的容器的 IP 地址实行 HTTP Get 要求。如果相应的状态码大于即是200 且小于 400,则诊断被认为是成功的。
[3] 定义LivenessProbe命令kubelet对非主进程崩溃类的容器缺点无法感知,须要借助存活性探测livenessProbe。许多永劫光运行的运用程序终极会转换到broken状态,除非重新启动,否则无法规复。Kubernetes供应了Liveness Probe来检测息争救这种情形。LivenessProbe三种实现办法:
1)ExecAction:在一个容器内部实行一个命令,如果该命令状态返回值为0,则表明容器康健。(即定义Exec liveness探针)
apiVersion: v1kind: Podmetadata: labels: test: liveness-exec name: liveness-execspec: containers: - name: liveness-exec-demo image: busybox args: ["/bin/sh","-c","touch /tmp/healthy;sleep 60;rm -rf /tmp/healthy;sleep 600"] livenessProbe: exec: command: ["test","-e","/tmp/healthy"] initialDelaySeconds: 5 periodSeconds: 5上面的资源清单中定义了一个Pod 工具, 基于 busybox 镜像 启动 一个 运行“ touch/ tmp/ healthy; sleep 60; rm- rf/ tmp/ healthy; sleep 600” 命令 的 容器, 此 命令 在 容器 启动 时 创建/ tmp/ healthy 文件, 并于 60 秒 之后 将其 删除。 periodSeconds 规定kubelet要每隔5秒实行一次liveness probe, initialDelaySeconds 见告kubelet在第一次实行probe之前要的等待5秒钟。存活性探针探针检测命令是在容器中实行 "test -e /tmp/healthy"命令检讨/ tmp/healthy 文件的存在性。如果命令实行成功,将返回0,表示 成功 通过 测试,则kubelet就会认为该容器是活着的并且很康健。如果返回非0值,kubelet就会杀掉这个容器并重启它。
2)TCPSocketAction:通过容器IP地址和端口号实行TCP检讨,如果能够建立TCP连接,则表明容器康健。这种办法利用TCP Socket,利用此配置,kubelet将考试测验在指定端口上打开容器的套接字。 如果可以建立连接,容器被认为是康健的,如果不能就认为是失落败的。(即定义TCP liveness探针)
apiVersion: v1kind: Podmetadata: labels: test: liveness-tcp name: liveness-tcpspec: containers: - name: liveness-tcp-demo image: nginx:1.12-alpine ports: - name: http containerPort: 80 livenessProbe: tcpSocket: port: http上面的资源清单文件,向Pod IP的80/tcp端口发起连接要求,并根据连接建立的状态判断Pod存活状态。
3)HTTPGetAction:通过容器IP地址、端口号及路径调用HTTP Get方法,如果相应的状态码大于即是200且小于即是400,则认为容器康健。(即定义HTTP要求的liveness探针)
apiVersion: v1kind: Podmetadata: labels: test: liveness-http name: liveness-httpspec: containers: - name: liveness-http-demo image: nginx:1.12-alpine ports: - name: http containerPort: 80 lifecycle: postStart: exec: command: ["/bin/sh","-c","echo healthy > /usr/share/nginx/html/healthy"] livenessProbe: httpGet: path: /healthy port: http scheme: HTTP initialDelaySeconds: 3 periodSeconds: 3上面 清单 文件 中 定义 的 httpGet 测试 中, 要求 的 资源 路径 为“/ healthy”, 地址 默认 为 Pod IP, 端口 利用 了 容器 中 定义 的 端口 名称 HTTP, 这也 是 明确 为 容器 指明 要 暴露 的 端口 的 用场 之一。livenessProbe 指定kubelete须要每隔3秒实行一次liveness probe。initialDelaySeconds 指定kubelet在该实行第一次探测之前须要等待3秒钟。该探针将向容器中的server的默认http端口发送一个HTTP GET要求。如果server的/healthy路径的handler返回一个成功的返回码,kubelet就会认定该容器是活着的并且很康健。如果返回失落败的返回码,kubelet将杀掉该容器并重启它。任何大于200小于400的返回码都会认定是成功的返回码。其他返回码都会被认为是失落败的返回码。
[4] 定义ReadinessProbe命令有时,运用程序暂时无法对外部流量供应做事。 例如,运用程序可能须要在启动期间加载大量数据或配置文件。 在这种情形下,你不想杀去世运用程序,但你也不想发送要求。 Kubernetes供应了readiness probe来检测和减轻这些情形。 Pod中的容器可以报告自己还没有准备,不能处理Kubernetes做事发送过来的流量。Readiness probe的配置跟liveness probe很像。唯一的不同是利用 readinessProbe而不是livenessProbe。
apiVersion: v1kind: Podmetadata: labels: test: readiness-exec name: readiness-execspec: containers: - name: readiness-demo image: busybox args: ["/bin/sh","-c","touch /tmp/healthy;sleep 60;rm -rf /tmp/healthy;"sleep 600] readinessProbe: exec: command: ["test","-e","/tmp/healthy"] initialDelaySeconds: 5 periodSeconds: 5上面定义的是一个exec的Readiness探针,其余Readiness probe的HTTP和TCP的探测器配置跟liveness probe一样。Readiness和livenss probe可以并行用于同一容器。 利用两者可以确保流量无法到达未准备好的容器,并且容器在失落败时重新启动。
[5] 配置Probe
Probe中有很多精确和详细的配置,通过它们你能准确的掌握liveness和readiness检讨:
initialDelaySeconds:容器启动后第一次实行探测是须要等待多少秒。即启动容器后首次进行康健检讨的等待韶光,单位为秒。
periodSeconds:实行探测的频率。默认是10秒,最小1秒。
timeoutSeconds:探测超时时间。默认1秒,最小1秒。即康健检讨发送要求后等待相应的韶光,如果超时相应kubelet则认为容器非康健,重启该容器,单位为秒。
successThreshold:探测失落败后,最少连续探测成功多少次才被认定为成功。默认是1。对付liveness必须是1。最小值是1。
failureThreshold:探测成功后,最少连续探测失落败多少次才被认定为失落败。默认是3。最小值是1。
HTTP probe中可以给 httpGet设置其他配置项:
host:连接的主机名,默认连接到pod的IP。你可能想在http header中设置”Host”而不是利用IP。
scheme:连接利用的schema,默认HTTP。
path: 访问的HTTP server的path。
httpHeaders:自定义要求的header。HTTP运行重复的header。
port:访问的容器的端口名字或者端口号。端口号必须介于1和65525之间。
对付HTTP探测器,kubelet向指定的路径和端口发送HTTP要求以实行检讨。 Kubelet将probe发送到容器的IP地址,除非地址被httpGet中的可选host字段覆盖。 在大多数情形下,不想设置主机字段。 有一种情形下可以设置它, 假设容器在127.0.0.1上侦听,并且Pod的hostNetwork字段为true。 然后,在httpGet下的host该当设置为127.0.0.1。 如果你的pod依赖于虚拟主机,这可能是更常见的情形,你不应该是用host,而是该当在httpHeaders中设置Host头。
[6] Liveness Probe和Readiness Probe利用场景- 如果容器中的进程能够在碰着问题或不康健的情形下自行崩溃,则不一定须要存活探针; kubelet 将根据 Pod 的restartPolicy 自动实行精确的操作。- 如果希望容器在探测失落败时被杀去世并重新启动,那么请指定一个存活探针,并指定restartPolicy 为 Always 或 OnFailure。- 如果要仅在探测成功时才开始向 Pod 发送流量,请指定就绪探针。在这种情形下,就绪探针可能与存活探针相同,但是 spec 中的就绪探针的存在意味着 Pod 将在没有吸收到任何流量的情形下启动,并且只有在探针探测成功后才开始吸收流量。- 如果你希望容器能够自行掩护,您可以指定一个就绪探针,该探针检讨与存活探针不同的端点。
请把稳:如果你只想在 Pod 被删除时能够打消要求,则不一定须要利用就绪探针;在删除 Pod 时,Pod 会自动将自身置于未完成状态,无论就绪探针是否存在。当等待 Pod 中的容器停滞时,Pod 仍处于未完成状态。
(9) Pod调度在kubernetes集群中,Pod(container)是运用的载体,一样平常通过RC、Deployment、DaemonSet、Job等工具来完成Pod的调度与自愈功能。
1. Pod的生命一样平常来说,Pod 不会消逝,直到人为销毁它们。这可能是一个人或掌握器。这个规则的唯一例外是成功或失落败的 phase 超过一段韶光(由 master 确定)的Pod将过期并被自动销毁。有三种可用的掌握器:- 利用 Job 运行预期会终止的 Pod,例如批量打算。Job 仅适用于重启策略为 OnFailure 或 Never 的 Pod。- 对预期不会终止的 Pod 利用 ReplicationController、ReplicaSet 和 Deployment ,例如,Web做事器。 ReplicationController 仅适用于具有 restartPolicy 为 Always 的 Pod。- 供应特定于机器的系统做事,利用 DaemonSet 为每台机器运行一个 Pod 。
所有这三种类型的掌握器都包含一个 PodTemplate。建议创建适当的掌握器,让它们来创建 Pod,而不是直接自己创建 Pod。这是由于单独的 Pod 在机器故障的情形下没有办法自动复原,而掌握器却可以。如果节点去世亡或与集群的别的部分断开连接,则 Kubernetes 将运用一个策略将丢失节点上的所有 Pod 的 phase 设置为 Failed。
2. RC、Deployment:全自动调度RC的功能即保持集群中始终运行着指定个数的Pod。在调度策略上紧张有:- 系统内置调度算法 [最优Node]- NodeSelector [定向调度]- NodeAffinity [亲和性调度]
[1] NodeSelector [定向调度]kubernetes中kube-scheduler卖力实现Pod的调度,内部系统通过一系列算法终极打算出最佳的目标节点。如果须要将Pod调度到指定Node上,则可以通过Node的标签(Label)和Pod的nodeSelector属性相匹配来达到目的。
1. kubectl label nodes {node-name} {label-key}={label-value}2. nodeSelector:{label-key}:{label-value}
如果给多个Node打了相同的标签,则scheduler会根据调度算法从这组Node中选择一个可用的Node来调度。如果Pod的nodeSelector的标签在Node中没有对应的标签,则该Pod无法被调度成功。
Node标签的利用场景:对集群中不同类型的Node打上不同的标签,可掌握运用运行Node的范围。例如:role=frontend;role=backend;role=database。
[2] NodeAffinity [亲和性调度]NodeAffinity意为Node亲和性调度策略,NodeSelector为精确匹配,NodeAffinity为条件范围匹配,通过In(属于)、NotIn(不属于)、Exists(存在一个条件)、DoesNotExist(不存在)、Gt(大于)、Lt(小于)等操作符来选择Node,使调度更加灵巧。
1. RequiredDuringSchedulingRequiredDuringExecution:类似于NodeSelector,但在Node不知足条件时,系统将从该Node上移除之前调度上的Pod。2. RequiredDuringSchedulingIgnoredDuringExecution:与上一个类似,差异是在Node不知足条件时,系统不一定从该Node上移除之前调度上的Pod。3. PreferredDuringSchedulingIgnoredDuringExecution:指定在知足调度条件的Node中,哪些Node应更优先地进行调度。同时在Node不知足条件时,系统不一定从该Node上移除之前调度上的Pod。
如果同时设置了NodeSelector和NodeAffinity,则系统将须要同时知足两者的设置才能进行调度。
3. DaemonSet:特定场景调度DaemonSet是kubernetes1.2版本新增的一种资源工具,用于管理在集群中每个Node上仅运行一份Pod的副本实例。
该用法适用的运用处景:1. 在每个Node上运行一个GlusterFS存储或者Ceph存储的daemon进程。2. 在每个Node上运行一个日志采集程序:fluentd或logstach。3. 在每个Node上运行一个康健程序,采集该Node的运行性能数据,例如:Prometheus Node Exportor、collectd、New Relic agent或Ganglia gmond等。
DaemonSet的Pod调度策略与RC类似,除了利用系统内置算法在每台Node上进行调度,也可以通过NodeSelector或NodeAffinity来指定知足条件的Node范围进行调度。
4. Job:批处理调度kubernetes从1.2版本开始支持批处理类型的运用,可以通过kubernetes Job资源工具来定义并启动一个批处理任务。批处理任务常日并行(或串行)启动多个打算进程去处理一批事情项(work item),处理完后,全体批处理任务结束。
批处理的三种模式:
批处理按任务实现办法不同分为以下几种模式:1. Job Template Expansion模式一个Job工具对应一个待处理的Work item,有几个Work item就产生几个独立的Job,通过适用于Work item数量少,每个Work item要处理的数据量比较大的场景。例如有10个文件(Work item),每个文件(Work item)为100G。2. Queue with Pod Per Work Item采取一个任务行列步队存放Work item,一个Job工具作为消费者去完成这些Work item,个中Job会启动N个Pod,每个Pod对应一个Work item。3. Queue with Variable Pod Count采取一个任务行列步队存放Work item,一个Job工具作为消费者去完成这些Work item,个中Job会启动N个Pod,每个Pod对应一个Work item。但Pod的数量是可变的。
Job的三种类型1. Non-parallel Jobs常日一个Job只启动一个Pod,除非Pod非常才会重启该Pod,一旦此Pod正常结束,Job将结束。2. Parallel Jobs with a fixed completion count并行Job会启动多个Pod,此时须要设定Job的.spec.completions参数为一个正数,当正常结束的Pod数量达到该值则Job结束。3. Parallel Jobs with a work queue任务行列步队办法的并行Job须要一个独立的Queue,Work item都在一个Queue中存放,不能设置Job的.spec.completions参数。
此时Job的特性:- 每个Pod能独立判断和决定是否还有任务项须要处理;- 如果某个Pod正常结束,则Job不会再启动新的Pod;- 如果一个Pod成功结束,则此时该当不存在其他Pod还在干活的情形,它们该当都处于即将结束、退出的状态;- 如果所有的Pod都结束了,且至少一个Pod成功结束,则全体Job算是成功结束;
(10) Pod伸缩kubernetes中RC是用来保持集群中始终运行指天命目的实例,通过RC的scale机制可以完成Pod的扩容和缩容(伸缩)。
1. 手动伸缩(scale)
# kubectl scale rc redis-slave --replicas=3
2. 自动伸缩(HPA)
Horizontal Pod Autoscaler(HPA)掌握器用于实现基于CPU利用率进行自动Pod伸缩的功能。HPA掌握器基于Master的kube-controller-manager做事启动参数--horizontal-pod-autoscaler-sync-period定义是时长(默认30秒),周期性监控目标Pod的CPU利用率,并在知足条件时对ReplicationController或Deployment中的Pod副本数进行调度,以符合用户定义的均匀Pod CPU利用率。Pod CPU利用率来源于heapster组件,因此需安装该组件。
HPA可以通过kubectl autoscale命令进行快速创建或者利用yaml配置文件进行创建。创建之前需已存在一个RC或Deployment工具,并且该RC或Deployment中的Pod必须定义resources.requests.cpu的资源要求值,以便heapster采集到该Pod的CPU。
[1] 通过kubectl autoscale创建。
apiVersion: v1kind: ReplicationControllermetadata: name: php-apachespec: replicas: 1 template: metadata: name: php-apache labels: app: php-apache spec: containers: - name: php-apache image: gcr.io/google_containers/hpa-example resources: requests: cpu: 200m ports: - containerPort: 80创建php-apache的RC
kubectl create -f php-apache-rc.yamlphp-apache-svc.yaml
apiVersion: v1kind: Servicemetadata: name: php-apachespec: ports: - port: 80 selector: app: php-apache创建php-apache的Service
kubectl create -f php-apache-svc.yaml创建HPA掌握器
kubectl autoscale rc php-apache --min=1 --max=10 --cpu-percent=50[2] 通过yaml配置文件创建
hpa-php-apache.yaml
apiVersion: v1kind: HorizontalPodAutoscalermetadata: name: php-apachespec: scaleTargetRef: apiVersion: v1 kind: ReplicationController name: php-apache minReplicas: 1 maxReplicas: 10 targetCPUUtilizationPercentage: 50创建hpa
kubectl create -f hpa-php-apache.yaml查看hpa
(11) Pod滚动升级和回滚
kubectl get hpaKubernetes是一个很好的容器运用集群管理工具,尤其是采取ReplicationController这种自动掩护运用生命周期事宜的工具后,将容器运用管理的技巧发挥得淋漓尽致。在容器运用管理的诸多特性中,有一个特性是最能表示Kubernetes强大的集群运用管理能力的,那便是滚动升级。
滚动升级的精髓在于升级过程中依然能够保持做事的连续性,使外界对付升级的过程是无感知的。全体过程中会有三个状态:全部旧实例,新旧实例皆有,全部新实例。旧实例个数逐渐减少,新实例个数逐渐增加,终极达到旧实例个数为0,新实例个数达到空想的目标值。
此项内容单独一篇文章先容。
(12) 资源需求和资源限定在Docker的范畴内,我们知道可以对运行的容器进行要求或花费的资源进行限定。而在Kubernetes中也有同样的机制,容器或Pod可以进行申请和花费的打算资源便是CPU和内存,这也是目前仅有的受支持的两种类型。比较较而言,CPU属于可压缩资源,即资源额度可按需紧缩;而内存则是不可压缩型资源,对其实行紧缩操作可能会导致某种程度的问题。
资源的隔离目前是属于容器级别,CPU和内存资源的配置须要Pod中的容器spec字段下进行定义。其详细字段,可以利用"requests"进行定义要求的确保资源可用量。也便是说容器的运行可能用不到这样的资源量,但是必须确保有这么多的资源供给。而"limits"是用于限定资源可用的最大值,属于硬限定。
在Kubernetes中,1个单位的CPU相称于虚拟机的1颗虚拟CPU(vCPU)或者是物理机上一个超线程的CPU,它支持分数计量办法,一个核心(1core)相称于1000个微核心(millicores),因此500m相称于是0.5个核心,即二分之一个核心。内存的计量办法也是一样的,默认的单位是字节,也可以利用E、P、T、G、M和K作为单位后缀,或者是Ei、Pi、Ti、Gi、Mi、Ki等形式单位后缀。
- 容器的资源需求,资源限定requests:需求,最低保障;limits:限定,硬限定;
- CPU1 颗逻辑 CPU1=1000,millicores (微核心)500m=0.5CPU
- 资源需求自主式pod哀求为stress容器确保128M的内存及五分之一个cpu核心资源可用,它运行stress-ng镜像启动一个进程进行内存性能压力测试,满载测试时它也会尽可能多地占用cpu资源,其余再启动一个专用的cpu压力测试进程。stress-ng是一个多功能系统压力测试工具,master/worker模型,master为主进程,卖力天生和掌握子进程,worker是卖力实行各种特定测试的子进程。
集群中的每个节点都拥有定量的cpu和内存资源,调度pod时,仅那些被要求资源的余量可容纳当前调度的pod的要求量的节点才可作为目标节点。也便是说,kubernetes的调度器会根据容器的requests属性中定义的资源需求量来剖断仅哪些节点可接管运行干系的pod资源,而对付一个节点的资源来说,每运行一个pod工具,其requestes中定义的要求量都要被预留,直到被所有pod工具瓜分完毕为止。
资源需求配置示例:
apiVersion: v1kind: Podmetadata: name: nginx-podspec: containers: - name: nginx image: nginx resources: requests: memory: "128Mi" cpu: "200m"上面的配置清单中,nginx要求的CPU资源大小为200m,这意味着一个CPU核心足以知足nginx以最快的办法运行,个中对内存的期望可用大小为128Mi,实际运行时不一定会用到这么多的资源。考虑到内存的资源类型,在超出指定大小运行时存在会被OOM killer杀去世的可能性,于是该要求值属于空想中利用的内存上限。
- 资源限定容器的资源需求仅能达到为其担保可用的最少资源量的目的,它并不会限定容器的可用资源上限,因此对因运用程序自身存在bug等多种缘故原由而导致的系统资源被长期占用的情形则无计可施,这就须要通过limits属性定义资源的最大可用量。资源分配时,可压缩型资源cpu的掌握阈可自由调节,容器进程无法得到超出其cpu配额的可用韶光。不过,如果进程申请分配超出其limits属性定义的硬限定的内存资源时,它将被OOM killer杀去世。不过,随后可能会被其掌握进程所重启。例如,容器进程的pod工具会被杀去世并重启(重启策略为always或onfailure时),或者是容器进程的子进程被其父进程所重启。也便是说,CPU是属于可压缩资源,可进行自由地调节。内存属于硬限定性资源,当进程申请分配超过limit属性定义的内存大小时,该Pod将被OOM killer杀去世。
与requests不同的是,limits并不会影响pod的调度结果,也便是说,一个节点上的所有pod工具的limits数量之和可以大于节点所拥有的资源量,即支持资源的过载利用。不过,这么一来一旦资源耗尽,尤其是内存资源耗尽,则一定会有容器因OOMKilled而终止。其余,kubernetes仅会确保pod能够得到他们要求的cpu韶光额度,他们能否得到额外的cpu韶光,则取决于其他正在运行的作业对cpu资源的占用情形。例如,对付总数为1000m的cpu来说,容器a要求利用200m,容器b要求利用500m,在不超出它们各自的最大限额的条件下,余下的300m在双方都须要时会以2:5的办法进行配置。
资源限定配置示例:
[root@k8s-master ~]# vim memleak-pod.yamlapiVersion: v1kind: Podmetadata: name: memleak-pod labels: app: memleakspec: containers: - name: simmemleak image: saadali/simmemleak resources: requests: memory: "64Mi" cpu: "1" limits: memory: "64Mi" cpu: "1" [root@k8s-master ~]# kubectl apply -f memleak-pod.yamlpod/memleak-pod created[root@k8s-master ~]# kubectl get pods -l app=memleakNAME READY STATUS RESTARTS AGEmemleak-pod 0/1 OOMKilled 2 12s[root@k8s-master ~]# kubectl get pods -l app=memleakNAME READY STATUS RESTARTS AGEmemleak-pod 0/1 CrashLoopBackOff 2 28sPod资源默认的重启策略为Always,在上面例子中memleak由于内存限定而终止会立即重启,此时该Pod会被OOM killer杀去世,在多次重复由于内存资源耗尽重启会触发Kunernetes系统的重启延迟,每次重启的韶光会不断拉长,后面看到的Pod的状态常日为"CrashLoopBackOff"。
- 容器的可见资源对付容器中运行top等命令不雅观察资源可用量信息时,即便定义了requests和limits属性,虽然其可用资源受限于此两个属性的定义,但容器中可见资源量依然是节点级别可用总量。
- Pod的做事质量种别(QoS)这里还须要明确的是,kubernetes许可节点资源对limits的过载利用,这意味着节点无法同时知足其上的所有pod工具以资源满载的办法运行。在一个Kubernetes集群上,运行的Pod浩瀚,那么当node节点都无法知足多个Pod工具的资源利用时 (节点内存资源紧缺时),该当按照什么样的顺序去终止这些Pod工具呢?kubernetes无法自行对此做出决策,它须要借助于pod工具的优先级来剖断终止Pod的优先问题。根据pod工具的requests和limits属性,kubernetes将pod工具归类到BestEffort、Burstable和Guaranteed三个做事质量种别:Guaranteed:每个容器都为cpu资源设置了具有相同值的requests和limits属性,以及每个容器都为内存资源设置了具有相同值的requests和limits属性的pod资源会自动归属于此种别,这类pod资源具有最高优先级.Burstable:至少有一个容器设置了cpu或内存资源的requests属性,但不知足Guaranteed种别哀求的pod资源将自动归属此种别,它们具有中等优先级。BestEffort:未为任何一个容器设置requests和limits属性的pod资源将自动归属于此种别,它们的优先级为最低级别。
内存资源紧缺时,BestEfford类别的容器将首当其冲地终止,由于系统不为其供应任何级别的资源担保,但换来的好处是:它们能够在可用时做到尽可能多地占用资源。若已然不存在BestEfford类别的容器,则接下来是有着中等优先级的Burstable类别的pod被终止。Guaranteed类别的容器拥有最高优先级,它们不会被杀去世,除非其内存资源需求超限,或者OOM时没有其他更低优先级的pod资源存在。
每个运行状态的容器都有其OOM得分,得分越高越会被优先杀去世。OOM得分紧张根据两个维度进行打算:由QoS种别继续而来的默认分值和容器的可用内存资源比例。同等类别的pod资源的默认分值相同。同等级别优先级的pod资源在OOM时,与自身requests属性比较,其内存占用比例最大的pod工具将被首先杀去世。须要特殊解释的是,OOM是内存耗尽时的处理机制,它们与可压缩型资源cpu无关,因此cpu资源的需求无法得到担保时,pod仅仅是暂时获取不到相应的资源而已。
查看 Qos[root@k8s-master01 ~]# kubectl describe pod/prometheus-858989bcfb-ml5gk -n kube-system|grep "QoS Class"QoS Class: Burstable(13) Pod持久存储办法volume是kubernetes Pod中多个容器访问的共享目录。volume被定义在pod上,被这个pod的多个容器挂载到相同或不同的路径下。volume的生命周期与pod的生命周期相同,pod内的容器停滞和重启时一样平常不会影响volume中的数据。以是一样平常volume被用于持久化pod产生的数据。Kubernetes供应了浩瀚的volume类型,包括emptyDir、hostPath、nfs、glusterfs、cephfs、ceph rbd等。
1. emptyDiremptyDir类型的volume在pod分配到node上时被创建,kubernetes会在node上自动分配 一个目录,因此无需指定宿主机node上对应的目录文件。这个目录的初始内容为空,当Pod从node上移除时,emptyDir中的数据会被永久删除。emptyDir Volume紧张用于某些运用程序无需永久保存的临时目录,多个容器的共享目录等。下面是pod挂载emptyDir的示例:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: gcr.io/google_containers/test-webserver name: test-container volumeMounts: - mountPath: /cache name: cache-volume volumes: - name: cache-volume emptyDir: {}2. hostPathhostPath Volume为pod挂载宿主机上的目录或文件,使得容器可以利用宿主机的高速文件系统进行存储。缺陷是,在k8s中,pod都是动态在各node节点上调度。当一个pod在当前node节点上启动并通过hostPath存储了文件到本地往后,下次调度到另一个节点上启动时,就无法利用在之前节点上存储的文件。下面是pod挂载hostPath的示例:
apiVersion: v1kind: Podmetadata: name: test-pdspec: containers: - image: gcr.io/google_containers/test-webserver name: test-container volumeMounts: - mountPath: /test-pd name: test-volume volumes: - name: test-volume hostPath: # directory location on host path: /data3. pod持久存储
办法一: pod直接挂载nfs-server
volumes: - name: nfs nfs: server: 192.168.1.1 path:"/"静态供应:管理员手动创建多个PV,供PVC利用。动态供应:动态创建PVC特定的PV,并绑定。
办法二: 手动创建PV
Persistent Volume(持久化卷)简称PV,是一个Kubernetes资源工具,我们可以单独创建一个PV,它反面Pod直接发生关系,而是通过Persistent Volume Claim,简称PVC来实现动态绑定, 我们会在Pod定义里指定创建好的PVC, 然后PVC会根据Pod的哀求去自动绑定得当的PV给Pod利用。
[1] 持久化卷下PV和PVC观点Persistent Volume(PV)是由管理员设置的存储,它是群集的一部分。就像节点是集群中的资源一样,PV 也是集群中的资源。 PV 是 Volume 之类的卷插件,但具有独立于利用 PV 的 Pod 的生命周期。此 API 工具包含存储实现的细节,即 NFS、iSCSI 或特定于云供应商的存储系统。
PersistentVolumeClaim(PVC)是用户存储的要求。它与 Pod 相似,Pod 花费节点资源,PVC 花费 PV 资源。Pod 可以要求特定级别的资源(CPU 和内存)。PVC声明可以要求特定的大小和访问模式(例如,可以以读/写一次或只读多次模式挂载)。
[2] 它和普通Volume的差异是什么呢?普通Volume和利用它的Pod之间是一种静态绑定关系,在定义Pod的文件里,同时定义了它利用的Volume。Volume是Pod的附属品,我们无法单独创建一个Volume,由于它不是一个独立的Kubernetes资源工具。
配置示例:pv.yaml
apiVersion: v1kind: PersistentVolumemetadata: name: pv003spec: capacity: storage: 5Gi accessModes: - ReadWriteOnce nfs: path: /somepath server: 192.168.1.1查看PV
# kubectl get pvNAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGEnfs-pv-heketi 300Mi ROX Retain Bound default/nfs-pvc-heketi 7dpvc-02b8a30d-8e28-11e7-a07a-025622f1d9fa 50Gi RWX Retain Bound kube-public/jenkins-pvc heketi-storage 5dPV可以设置三种回收策略:保留(Retain),回收(Recycle)和删除(Delete)。保留策略:许可儿工处理保留的数据。删除策略:将删除pv和外部关联的存储资源,须要插件支持。回收策略:将实行打消操作,之后可以被新的pvc利用,须要插件支持。
PV的状态:Available :资源尚未被claim利用Bound :已经绑定到某个pvc上Released : 对应的pvc被删除,但是资源还没有被集群回收Failed : 自动回收失落败
PV访问权限ReadWriteOnce : 被单个节点mount为读写rw模式ReadOnlyMany : 被多个节点mount为只读ro模式ReadWriteMany : 被多个节点mount为读写rw模式
[3] 配置示例
pv的配置定义, pvc.yaml
apiVersion: v1kind: PersistentVolumeClaimmetadata: name: myclaimspec: accessModes: - ReadWriteOnce resources: requests: storage: 5Gi pod配置文件中运用pv# mypod.yamlvolumes: - name: mypod persistentVolumeClaim: claimName: myclaim[4] kubernetes 快速批量创建 PV & PVC 脚本
- 快速批量创建nfs pv
for i in {3..6}; docat <<EOF | kubectl apply -f -apiVersion: v1kind: PersistentVolumemetadata: name: pv00${i}spec: capacity: storage: 100Gi accessModes: - ReadWriteOnce #这里根据须要配置ReadWriteOnce或者ReadWriteMany persistentVolumeReclaimPolicy: Recycle nfs: path: /volume1/harbor/nfs${i} server: 192.168.2.4EOFdone- 快速批量创建nfs pvc
for i in {3..6}; docat <<EOF | kubectl delete -f -kind: PersistentVolumeClaimapiVersion: v1metadata: name: pvc00${i}-claimspec: accessModes: - ReadWriteOnce resources: requests: storage: 100GiEOFdone(14) Pod水平自动扩展(HPA)Kubernetes有一个强大的功能,它能在运行的做事上进行编码并配置弹性伸缩。如果没有弹性伸缩功能,就很难适应支配的扩展和知足SLAs。这一功能称为Horizontal Pod Autoscaler (HPA),这是kubernetes的一个很主要的资源工具。HPA是Kubernetes中弹性伸缩API组下的一个API资源。当前稳定的版本是autoscaling/v1,它只供应了对CPU自动缩放的支持。
Horizontal Pod Autoscaling,即pod的水平自动扩展。自动扩展紧张分为两种,其一为水平扩展,针对付实例数目的增减;其二为垂直扩展,即单个实例可以利用的资源的增减。HPA属于水平自动扩展。HPA的操为难刁难象是RC、RS或Deployment对应的Pod,根据不雅观察到的CPU等实际利用量与用户的期望值进行比对,做出是否须要增减实例数量的决策。
1. 为什么利用HPA利用HPA,可以根据资源的利用情形或者自定义的指标,实现支配的自动扩展和缩减,让支配的规模靠近于实际做事的负载。HPA可以为您的做事带来两个直接的帮助:- 在须要打算和内存资源时供应资源,在不须要时开释它们- 按需增加/降落性能以实现SLA
2. HPA事理它根据Pod当前系统的负载来自动水平扩容,如果系统负载超过预定值,就开始增加Pod的个数,如果低于某个值,就自动减少Pod的个数。目前Kubernetes的HPA只能根据CPU等资源利用情形去度量系统的负载。HPA会根据监测到的CPU/内存利用率(资源指标),或基于第三方指标运用程序(如Prometheus等)供应的自定义指标,自动调度副本掌握器、支配或者副本凑集的pods数量(定义最小和最大pods数)。HPA是一种掌握回路,它的周期由Kubernetes的controller manager 的--horizontal-pod-autoscaler-sync-period标志掌握(默认值是30s)。
在一样平常情形下HPA是由kubectl来供应支持的。可以利用kubectl进行创建、管理和删除:创建HPA- 带有manifest: "kubectl create -f <HPA_MANIFEST>"- 没有manifest(只支持CPU):"kubectl autoscale deployment hello-world –min=2 --max=5 –-cpu-percent=50"
获取hpa信息- 基本信息: "kubectl get hpa hello-world"- 细节描述: "kubectl describe hpa hello-world"
删除hpa# kubectl delete hpa hello-world
下面是一个HPA manifest定义的例子:
这里利用了autoscaling/v2beta1版本,用到了cpu和内存指标掌握hello-world项目支配的自动缩放定义了副本的最小值1定义了副本的最大值10当知足时调度大小:- CPU利用率超过50%- 内存利用超过100Mi
3. HPA条件HPA通过定期(定期轮询的韶光通过--horizontal-pod-autoscaler-sync-period选项来设置,默认的韶光为30秒)通过Status.PodSelector来查询pods的状态,得到pod的CPU利用率。然后,通过现有pods的CPU利用率的均匀值(打算办法是最近的pod利用量(最近一分钟的均匀值,从heapster中得到)除以设定的每个Pod的CPU利用率限额)跟目标利用率进行比较,并且在扩容时,还要遵照预先设定的副本数限定:MinReplicas <= Replicas <= MaxReplicas。
打算扩容后Pod的个数:sum(最近一分钟内某个Pod的CPU利用率的均匀值)/CPU利用上限的整数+1
4. HPA流程- 创建HPA资源,设定目标CPU利用率限额,以及最大、最小实例数- 网络一组中(PodSelector)每个Pod最近一分钟内的CPU利用率,并打算均匀值- 读取HPA中设定的CPU利用限额- 打算:均匀值之和/限额,求出目标调度的实例个数- 目标调度的实例数不能超过1中设定的最大、最小实例数,如果没有超过,则扩容;超过,则扩容至最大的实例个数- 回到2,不断循环
5. HPA例外考虑到自动扩展的决策可能须要一段韶光才会生效,乃至在短韶光内会引入一些噪声。例如当pod所须要的CPU负荷过大,从而运行一个新的pod进行分流,在创建过程中,系统的CPU利用量可能会有一个攀升的过程。以是,在每一次作出决策后的一段韶光内,将不再进行扩展决策。对付ScaleUp (纵向扩展)而言,这个韶光段为3分钟,Scaledown为5分钟。
HPA许可一定范围内的CPU利用量的不稳定,只有 avg(CurrentPodsConsumption) / Target 小于90%或者大于110%时才会触发扩容或缩容,避免频繁扩容、缩容造成颠簸。
6. 为什么HPA选择相比拟率为了简便,选用了相比拟率(90%的CPU资源)而不是0.6个CPU core来描述扩容、缩容条件。如果选择利用绝对度量,用户须要担保目标(限额)要比要求利用的低,否则,过载的Pod未必能够花费那么多,从而自动扩容永久不会被触发:假设设置CPU为1个核,那么这个pod只能利用1个核,可能Pod在过载的情形下也不能完备利用这个核,以是扩容不会发生。在修正申请资源时,还有同时调度扩容的条件,比如将1个core变为1.2core,那么扩容条件该当同步改为1.2core,这样的话,就真是太麻烦了,与自动扩容的目标相悖。
7. 安装需求在HPA可以在Kubernetes集群上利用之前,有一些元素须要在系统中安装和配置。检讨确定Kubernetes集群做事正在运行并且至少包含了这些标志:kube-api:requestheader-client-ca-filekubelet:read-only-port 在端口10255kube-controller:可选,只在须要和默认值不同时利用horizontal-pod-autoscaler-downscale-delay:”5m0s”horizontal-pod-autoscaler-upscale-delay:”3m0s”horizontal-pod-autoscaler-sync-period: “30s”
1)创建Deployment[root@k8s-master01 ~]# cat << EOF > lykops-hpa-deploy.yamlapiVersion: extensions/v1beta1kind: Deploymentmetadata: name: lykops-hpa-deploy labels: software: apache project: lykops app: hpa version: v1 spec: replicas: 1 selector: matchLabels: name: lykops-hpa-deploy software: apache project: lykops app: hpa version: v1 template: metadata: labels: name: lykops-hpa-deploy software: apache project: lykops app: hpa version: v1 spec: containers: - name: lykops-hpa-deploy image: web:apache command: [ "sh", "/etc/run.sh" ] ports: - containerPort: 80 name: http protocol: TCP resources: requests: cpu: 0.001 memory: 4Mi limits: cpu: 0.01 memory: 16MiEOF 创建这个实例[root@k8s-master01 ~]# kubectl create -f lykops-hpa-deploy.yaml --record 2)创建service[root@k8s-master01 ~]#cat << EOF > lykops-hpa-deploy-svc.yamlapiVersion: v1kind: Servicemetadata: name: lykops-hpa-svc labels: software: apache project: lykops app: hpa version: v1spec: selector: software: apache project: lykops app: hpa version: v1 name: lykops-hpa-deploy ports: - name: http port: 80 protocol: TCPEOF 创建这个service[root@k8s-master01 ~]# kubectl create -f lykops-hpa-deploy-svc.yaml 3)创建HPA[root@k8s-master01 ~]# cat << EOF > lykops-hpa.yamlapiVersion: autoscaling/v1kind: HorizontalPodAutoscalermetadata: name: lykops-hpa labels: software: apache project: lykops app: hpa version: v1spec: scaleTargetRef: apiVersion: v1 kind: Deployment name: lykops-hpa-deploy #这里只能为这三项 minReplicas: 1 maxReplicas: 10 targetCPUUtilizationPercentage: 5EOF 创建这个HPA[root@k8s-master01 ~]# kubectl create -f lykops-hpa.yaml 4)测试多台机器不断访问service的clusterIP地址,然后可以看出是否增加pod数了参考(1) 威信指南书本 https://weread.qq.com/web/reader/9fc329507191463c9fcee6dk3c5327902153c59dc0488e1
(2) yaml格式的pod定义文件完全内容
https://zhuanlan.zhihu.com/p/49567851
(3)Kubernetes中的Pod的到底是什么? http://dockone.io/article/2682
(4)Kubernetes 之Pod学习 https://www.cnblogs.com/kevingrace/p/11309409.html
(5)Kubernetes学习之路(十一)之Pod状态和生命周期管理 https://www.cnblogs.com/linuxk/p/9569618.html















