
XPath 可以用于 Xml 和 Html,在爬虫中常常利用 XPath 获取 Html 文档内容。
lxml 是 Python 措辞用 Xpath 解析 XML、Html文档功能最丰富的、最随意马虎的功能模块。

在 XPath 中有七种节点分别是元素、属性、文本、文档、命名空间、处理指令、注释,前3种节点为常用节点
请看下面的 Html 例子,(注:这个例子全文都须要利用)
<!DOCTYPE html><html> <body> <div> <!-- 这里是注释 --> <h4>手机品牌商<span style="margin-left:10px">4</span></h4> <ul> <li>小米</li> <li>华为</li> <li class='blank'> OPPO </li> <li>苹果</li> </ul> </div> <div> <h4>电脑品牌商<span style="margin-left:10px">3</span></h4> <ul class="ul" style="color:red"> <li>戴尔</li> <li>机器革命</li> <li>ThinkPad</li> </ul> </div> </body></html>
在上面的例子中
<html> 为文档节点<li>小米</li> 为元素节点class='blank' 为属性节点<!-- 这里是注释 --> 为注释节点节点关系
在 XPath中有多中节点关系分别是父节点、子节点、同胞节点、先辈节点、后代节点
在上面的例子中
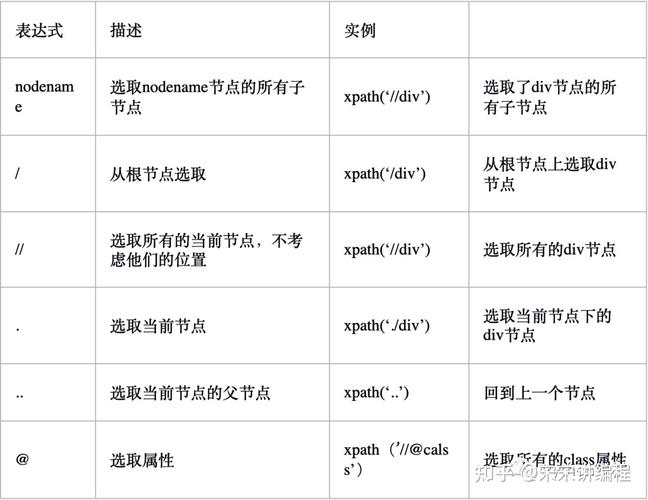
父节点:每个元素以及属性都有一个父节点,如:div 节点的父节点是 body 节点子节点:元素节点可有零个、一个或多个子节点,如:第一个 ul 节点的子节点是4个 li 节点同胞节点:拥有相同的父节点的节点,如:两个 div 节点是同胞节点先辈节点:某节点的父节点、父节点的父节点…,如:ul 节点的先辈节点有 div 节点、body 节点后代节点:某个节点的子节点,子节点的子节点…,如:body 节点的后代节点有div 节点、ul 节点、li 节点更多精彩可以点赞+关注私信我XPath 语法基本语法表达式描述nodeName选择nodeName节点的所有子节点/从根节点开始//从匹配的节点开始选择节点.选择当前节点..选择当前节点的父节点@选择元素匹配任意元素节点@匹配任意属性节点
用上面的 Html 文档举个例子
路径表达式描述body选取 body 的所有子节点/html选取 html 节点//div选取所有 div 节点//div/./h4div 节点下的 h4 节点../div选取当前节点的父节点下的所有 div 节点//@class所有带有 class 元素的节点//选择所有节点//@选择所有属性节点
常用函数表达式描述position()返回节点的 index 位置last()返回节点的个数contains(string1,string2)string1 是否包含 string2text()返回文本节点comment()返回注释节点normalize-space(string)去除首位空格,中间多个空格用一个空格代替substring(string,start,len)返回从 start 位置开始的指定长度的子字符串,第一个字符下标为1substring-before(string1,string2)返回string1中位于第一个string2之前的部分substring-after(string1,string2)返回string1中位于第一个string2之后的部分
同样用上面的Html文档举个例子
路径表达式描述//div[position()>1]选择第二个 div 节点//div[last()]选择末了一个 div 节点contains(//h4[2],’手机’)第二个 h4 标签是否包含手机字符串//li/text()li 节点中的文本内容//div/comment()div 节点下的 html 注释normalize-space(//li[@class=’blank’])li 节点下 class属性为 blank 的文本去掉空格substring(//h4[1],1,2)第一个 h4 节点的前2个字substring-before(//h4[1],’品牌商’)第一个 h4 节点的品牌商字符串之前的字符串substring-after(//h4[1],’品牌商’)第一个 h4 节点的品牌商字符串之后的字符串
谓语XPath 中的谓语便是删选表达式,相称于 SQL 中的 Where 条件,谓语被嵌在 [ ] 中
路径表达式描述//div[1]选择第一个 div 节点//div[2]/ul/li[last()]选择第二个 div 节点下的末了一个 li 节点//div[2]/ul/li[position()>3]选择第二个 div 节点下的前两个 li 节点//ul[@class]选择所有带 class 属性的 ul 节点//ul[@class=’computer’]选择 class 属性为 computer 的 ul 节点//h4[span = 4]选择 h4 节点下 span 值即是4的节点
Xpath 结语以上内容先容了 XPath 的基本语法,下面将先容 XPath 如何在 Python 中利用。
lxml 模块安装sudo pip3 install lxml==4.4.1解析 HTML 文档
lxml.etree 一个强大的 Xml 处理模块,etree 中的 ElementTree 类是一个紧张的类,用于对XPath的解析、增加、删除和修正节点。
from lxml import etree
etree.parse() 函数可以解析一个网页文件还可以解析字符串, 在网页中下载的数据一样平常都是字符串形式的,利用 parse(StringIO(str)) 将全体页面内容解析加载构建一个 ElementTree 工具,ElementTree 可以利用 XPath 语法精准找到须要的数据。
1.加载页面到内存
from lxml import etreefrom io import StringIOtest_html = '''<html> <body> <div> <!-- 这里是注释 --> <h4>手机品牌商<span style="margin-left:10px">4</span></h4> <ul> <li>小米</li> <li>华为</li> <li class='blank'> OPPO </li> <li>苹果</li> </ul> </div> <div> <h4>电脑品牌商<span style="margin-left:10px">3</span></h4> <ul class="ul" style="color:red"> <li>戴尔</li> <li>机器革命</li> <li>ThinkPad</li> </ul> </div> </body></html>'''html = etree.parse(StringIO(test_html))print(html)
结果:
<lxml.etree._ElementTree object at 0x10bd6b948>
2.获取所有 li 标签数据
li_list = html.xpath('//li')print("类型:")print(type(li_list))print("值:")print(li_list)print("个数:")print(len(li_list))for l in li_list: print("li文本为:" + l.text)
结果:
类型:<class 'list'>值:[<Element li at 0x10543c9c8>, <Element li at 0x10543ca08>, <Element li at 0x10543ca48>, <Element li at 0x10543ca88>, <Element li at 0x10543cac8>, <Element li at 0x10543cb48>, <Element li at 0x10543cb88>]个数:7li文本为:小米li文本为:华为li文本为: OPPO li文本为:苹果li文本为:戴尔li文本为:机器革命li文本为:ThinkPad
3.获取带 class=’blank’ 属性数据
blank_li_list = html.xpath('//li[@class="blank"]')print("类型:")print(type(blank_li_list))print("值:")print(blank_li_list)print("个数:")print(len(blank_li_list))for l in blank_li_list: print("li文本为:" + l.text)
结果:
类型:<class 'list'>值:[<Element li at 0x105253a48>]个数:1li文本为: OPPO
4.属性操作
ul = html.xpath('//ul')[1]#遍历属性for name, value in ul.attrib.items(): print('{0}="{1}"'.format(name, value))#添加新的属性ul.set("new_attr", "true")# 获取单个属性new_attr = ul.get('new_attr')print(new_attr)
结果:
class="ul"style="color:red"true
5.获取末了一个div标签数据
last_div = html.xpath('//div[last()]')print("TAG:")print(last_div.tag)print("值:")print(last_div.text)
结果
div值:
6.添加子节点
child = etree.Element("child")child.text = "这里是新的子元素"last_div.append(child)# 在末了一个 div 标签查找新的子元素clild_text = last_div.find("child").textprint(clild_text)
7.删除子元素
# 查找并设置第一个查询到的元素first_ul = html.find("//ul")ul_li = first_ul.xpath("li")for li in ul_li: # 删除元素 first_ul.remove(li)ul_li = first_ul.xpath("li")if len(ul_li) == 0: print("元素被删除了")
8.遍历元素后代
body = html.find("body")for sub in body.iter(): print(sub.tag) print(sub.text)
结果
body div <cyfunction Comment at 0x10c374b10> 这里是注释 h4手机品牌商span4ul...工具在 google 浏览器开拓者模式下,Elements 界面选择元素后右键 Copy,可以 Copy 元素的 XPath 路径XPath Helper 是一个 google 浏览器插件,可以验证 XPath 是否精确总结学习了 XPAth 的知识,可以快速匹配单个或多个元素节点和属性,在事情中大大加快了事情的效率。lxml 是一个 Python 中强大的 Xml 和 Html 处理模块,结合 XPath 的利用在程序中快速、便捷的剖析、修正网页内容。















