
文章目录
[+]
爬虫的事情事理实在并不繁芜,但其运作过程涉及多个步骤。让我们一起来看看。
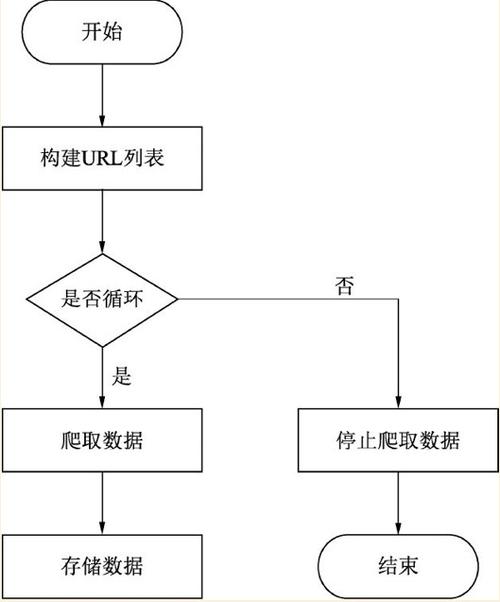
发送要求:爬虫首先向目标网站发送HTTP要求,要求获取网页的HTML内容。这个过程类似于用户在浏览器中输入网址并按下回车键。爬虫可以通过各种编程措辞和库,如Python的Requests库,来实现这一操作。

解析相应:目标网站吸收到要求后,返回包含网页内容的HTTP相应。爬虫程序解析这个相应,提取出网页的HTML代码。常用的解析库包括BeautifulSoup和lxml,这些工具可以帮助爬虫高效地处理和理解HTML构造。
(图片来自网络侵删)
数据提取:爬虫通过解析HTML代码,利用特定的规则或正则表达式,提取出所需的数据。例如,从商品页面提取商品名称、价格、图片链接等信息。这一步常日利用CSS选择器或XPath来定位和提取数据。
存储数据:提取到的数据会被存储到本地数据库或文件系统中,方便后续的数据处理和剖析。常见的存储办法包括MySQL、MongoDB、CSV文件等。
递归爬取:爬虫会连续从当前页面中提取其他链接,递归地发送要求、解析相应、提取数据,直到遍历完所有目标页面。这一过程须要有效的URL管理和去重机制,以避免重复抓取和遗漏主要数据。
爬虫数据采集是一项强大的技能,同时,711Proxy供应动态住宅IP,更适宜有爬虫需求的用户利用。如果还有疑问可以评论区进行谈论~















