
这种情形我们该当怎么办理呢?Smartbi利用高速缓存加速跨库查询,可以实现仪表盘打开速率10倍的提升!
下面我们先来看一个实际效果比拟:
在Smartbi体验中央的“体验式场景5”中,剖析某公司的雇员数据情形时,个中的雇员表(300,024条记录)与薪资表(2,844,047条记录)进行跨库关联,利用高速缓存之前刷新数据至少要20秒;当数据抽取到高速缓存库后,切换年份刷新仅需2秒,乃至更快。

未利用高速缓存加速前,仪表盘打开20秒:
未利用高速缓存加速前,仪表盘打开2秒:
那么Smartbi是如何做到呢?下面跟小麦一起学习吧!
(喜好的小伙伴也可以上岸Smartbi官网不雅观看视频学习噢~)
跨库加速事理解释
思迈特软件Smartbi通过供应跨库联合数据源来支持直接的跨库查询。跨库联合数据源是系统内置数据源,系统自动将新建的关系数据源信息添加到该跨库联合数据源中,或通过数据库关联界面将须要的数据源手动添加,进行跨库查询时利用。
当跨库数据源运用在数据集中时,一旦数据达到某个级别之后,报表性能就会涌现很大的一个瓶颈,比如很永劫光刷新不出、系统崩溃等。为了应对数据处理性能问题,Smartbi研发出高速缓存机制,它利用分布式的内存打算技能,在进行数据剖析的时候,许可将原始库数据抽取到高速缓存中再进行剖析,办理性能瓶颈,实现报表加速。并且可以根据用户的实际情形,选择不同的高速缓存方案。
高速缓存机制
高速缓存的基本事理便是将频繁访问的数据保存在相对能够快速存取的高速缓冲区域中,以避免在繁芜的数据文件中探求。由于高速缓存库中保存了数据副本,可以方便用户程序更高效地访问数据,并且减轻了数据库的事情量,增强了系统的性能和可伸缩性。目前产品支持高速缓存库的类型包括:SmartbiMPP、Presto+Hive、星环、Vertica、Infobright等。
我们在Smartbi的高速缓存库中采取了缓存技能,也叫“工具缓冲池”,用于缓存系统中用到的数据集定义及最近利用的查询结果等。产品的工具池是存储在内存中,工具缓冲池可以增强系统在并发时的性能,减少做事器的压力,提高用户报表查询速率。
数据抽取机制
Smartbi通过“数据抽取”将源数据库中的数据抽取到高速缓存库,担保秒级获取大级别量的数据结果,以提高系统性能。数据抽取功能的机制如下:
确定好数据集或剖析的结果字段。
发起数据抽取指令,从源数据库中将字段的所有数据抽取到高速缓存库,在高速缓存库的“DEFAULT”节点下天生对应的视图和字段。
再次查询当前数据集或剖析的数据时,从高速缓存库获取数据。
目前,系统支持数据抽取功能的模块有:自助数据集、可视化数据集、SQL数据集、原生SQL数据集、存储过程数据集、Java数据集、即席查询、透视剖析、加载Excel数据。
实现加速的操作步骤
接下来,小麦以体验中央的“体验式场景5”为例,演示如何在自助数据集中实现数据抽取功能。
数据抽取功能的入口可以通过即席查询、非自助数据集和自主数据集进入界面,以下将从自助数据集入口进行先容。
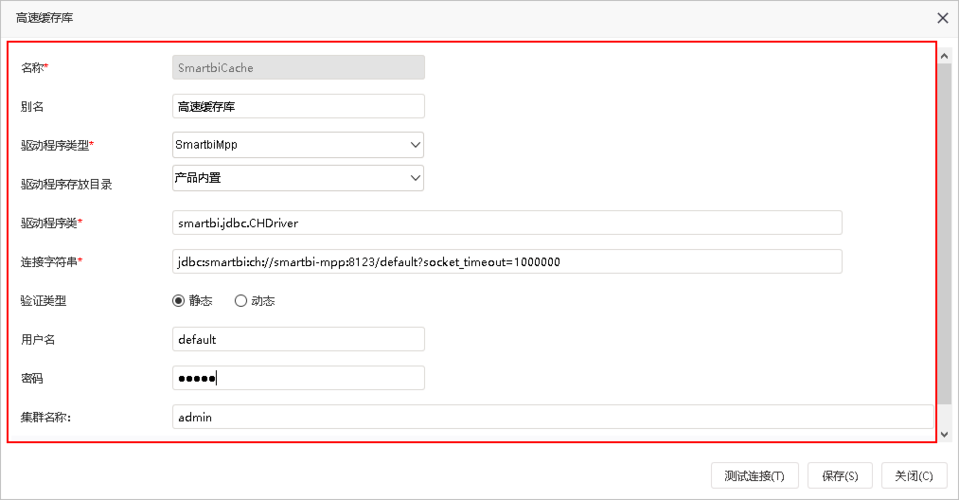
安装配置高速缓存库。
根据实际须要安装配置好高速缓存库(详细可以参考Smartbi wiki文档)。下图是我司研发的高速缓存库SmartbiMpp的连接配置界面:
创建跨库查询,并保存。
根据须要创建自助数据集,在自助数据集中跨数据源拖拽干系表进行关联查询。创建好后,我们保存自助数据集到我的空间并命名。
进行数据抽取设置,并抽取数据。
编辑自助数据集时,首先点击右上角工具栏上的 抽取 按钮,再点击 抽取设置 按钮,打开“数据抽取设置”窗口。
接着选择数据抽取的办法。数据抽取办法常日分为全量抽取和增量抽取,全量抽取是抽取所有数据,增量抽取是指与上次抽取结果中最大韶光比拟,将大于这个韶光的数据进行集中抽取。 此处我们选择全量抽取,并立即抽取数据。
创建剖析资源,进行数据预览
我们利用抽取好数据的自助数据集来创建干系资源,比如创建透视剖析。选择对应的字段到行列度量区域,再点击刷新按钮即可。
可以看到,当数据抽取到高速缓存库后,刷新数据不到1秒即可展现,利用前高速缓存之前刷新数据至少要20秒,通过高速缓存库的加速,跨库查询的速率实现了十倍提升!
除了高速缓存库,Smartbi还有多方面的手段用以提高性能,比如设置参数、分页、Web优化、运用集群等等,以便办理不同情形下的性能问题。
随着全行业数字化转型和新基建时期的到来,越来越多企业重视海量数据的网络和剖析处理活动,未来须要处理数据能力的哀求会越来越高,Smartbi将会发挥原有的上风,在BI行业连续深耕,不断创新,为用户带来更为极致的体验与做事。















