
作者:马行健
单位:中国移动聪慧家庭运营中央

互联网站点的流量一部分由人类正常访问行为产生,而高达30%-60%的流量则是由网络爬虫产生的,个中一部分包含友好网络爬虫,如搜索引擎的爬虫、广告程序、第三方互助伙伴程序、Robots协议友好程序等;而并非所有的网络爬虫都是友好的,爬虫流量中仍有约20%~30%的流量来自恶意网络爬虫。从网站业务安全的角度,例如文学博客、招聘网站、论坛网站、电商等网站均以文本为商品作为盈利点,而恶意爬虫则可以通过爬取核心文本从中谋取利益;竞品公司还可以通过利用恶意爬虫爬取商品价格和详情或者注册用户信息后进行同类产品线和价格的研究,通过推出过低价格等手段来毁坏市场秩序;对付带宽有限的中小型网站,高频、大规模的恶意爬虫可能会降落网页加载速率,影响真实用户的访问体验,增加网站带宽包袱。
由于恶意爬虫带来的不利影响,因此涌现了爬虫防御技能-即反爬虫技能,反爬虫技能可分为被动防御机制与主动防御机制。
➢ 被动防御机制:紧张是根据检测结果展开的,如利用HTTP要求头User-Agent来判断、拦截爬虫要求,或对访问频率过高的IP地址进行封禁。被动防御存在部分毛病:被动防御检测流程和机制单一,无法应对繁芜多变的恶意爬虫,检测误判率高,随意马虎造成误封、漏封。
➢ 主动防御机制:是主流的爬虫防御发展方向,通过对网页底层代码的持续动态变换,增加做事器行为的“不可预测性”,大幅提升攻击难度,从而实现了从客户端到做事器真个全方位“主动防护”。
2、网络爬虫技能基本事情流程和根本架构与正凡人类访问者利用浏览器访问网页的事情事理相同,网络爬虫也是根据HTTP协议来获取网页信息的,其流程紧张包括如下步骤:
1)对待抓取的URL进行域名解析;
2)根据HTTP协议,发送HTTP要求来获取网页内容。
网络爬虫的根本架构如图1所示。详细而言,网络爬虫首先通过种子URL延伸得到待抓取URL行列步队,接着网络爬虫从待抓取URL列表中逐个进行读取,读取URL的过程中,会将URL进行DNS解析,得到网站做事器的IP地址以及相对路径,接着再把这个地址交给网页下载器(卖力下载网页内容的一个模块)。
对付下载到本地的网页,即网页的源代码,一方面要将这个网页存储到网页库中,另一方面要从下载的网页中再次提取URL地址,新提取出来的URL地址会先在已抓取的URL列表中进行比对,检讨该网页是否已被抓取,如果网页没有被抓取过,就将新的URL地址放入到待抓取的URL列表的末端,等待被抓取,直至待抓取行列步队为空的时候,网络爬虫就算完成了抓取的全过程,末了对网页库中已下载的网页进行剖析与索引后得到收录结果。个中所谓种子URL即为最开始选定的URL地址,网站首页、频道页等丰富性内容较多的页面每每会被作为种子URL。
图1 网络爬虫的根本架构
3、基于自定义cookie的爬虫检测策略目前的爬虫检测技能紧张分为以下四类:一是基于日志剖析的检测技能,二是基于访问模式的检测技能,三是基于访问行为的检测技能,四是基于图灵测试的检测技能。
基于日志剖析的检测技能是通过比拟用户和爬虫名单库的爬虫的User-Agent关键词、IP地址等信息来检测爬虫。基于访问模式的检测技能通过探求人类用户与爬虫的不同流量特色,如查询数量、韶光间隔模式、搜索操作频率等来检测爬虫。基于访问行为的检测技能大多利用机器学习模型如神经网络、决策树等通过访问者的点击韶光、图片加载情形以及访问勾留时长等有利特色来对访问进行分类,从而判断访问是否来自爬虫。基于图灵测试的检测技能通过让访问者回答一些问题来剖析其是否为爬虫,常见的图灵测试系统有验证码测试。除了上述四类方法,蜜罐技能(隐蔽链接)也常被利用,通过在网页中隐蔽一些人眼不能创造但爬虫访问能够访问但链接来识别爬虫。
基于自定义cookie的检测技能是一种基于日志剖析的主动抵御爬虫的策略,该策略是通过在网站的接口中增加了一些加密参数来实现的,浏览器通过实行返回的JS代码得到具有时效性以及机密性的结果,并将结果添加到cookie中,再次发起要求时携带,正凡人类访问者和恶意爬虫的访问过程如图2所示。
图2 正凡人类访问者和恶意爬虫的访问流程图
详细而言,向客户端返回JS代码,并通过客户端实行JS代码的结果来主动抵御爬虫。cookie的天生过程可以领悟客户端浏览器的特性,该特性检测只有在真实的浏览器和真实用户访问行为的情形下才能完成,而无法在一些浏览器内核仿照器上或者一些假造了要求头User-Agent的情形下得到。比如,做事器返回的检测脚本用于检测浏览器是否存在某个bug,针对实际的浏览器而言,该浏览器本身是存在该bug的,但爬虫程序中假造的浏览器运行该检测脚本天生对应cookie时,则不会得到精确的cookie,因此可断定访问用户为爬虫。再如,cookie天生脚本中领悟浏览器是否具有网页翻译的功能,针对实际的浏览器而言,该浏览器本身是具有网页翻译功能的,但客户真个浏览器运行该检测脚本时,实行网页翻译功能失落败,因此也可断定访问用户为爬虫。
针对以自定义cookie为根本的爬虫检测技能,浏览器可以通过实行JS代码获取到后端认可的结果,同理,攻击者也可以通过拦截JS代码并对其剖析,从而达到同样的目的。因此返回的JS代码须要具备反拦截以及不易逆向的特点,此时将JavaScript-obfuscator稠浊技能结合到基于自定义cookie的检测技能中,担保代码安全。此处的JavaScript-obfuscator稠浊技能常日包含JS代码压缩、稠浊与加密技能。
4、JS代码压缩、稠浊与加密JS代码压缩是去除JS代码中的不必要的空格、换行等内容,使源码压缩为几行内容,降落代码可读性,同时也可以提高网站的加载速率。
JS代码稠浊是一种较为空想、实用的代码保护方案,通过利用变量稠浊、字符串稠浊、反格式化、掌握流平坦化、无用代码注入、工具键名更换、禁用掌握台输出、调试保护、域名锁定等手段,在不影响代码原有功能的根本上,使代码变得难以阅读和剖析,达到终极保护的目的。JS代码加密是通过某种手段将JS代码进行加密,转成人无法阅读或者解析的代码或将代码完备抽象化加密。
常见的JS代码加密技能有JSfuck、AAEncode、JJEncode、eval加密。JSfuck、AAEncode、JJEncode加密技能利用各自的符号库对JS代码进行编码,eval加密每每也都因此eval(p,a,c,k,e,r)或者是eval(function(p,a,c,k,e,d)作为代码开头。以上四种加密办法加密特色明显,易于解码,利用浏览器的开拓者工具均可以完备还原,与此同时eval加密技能压栈很严重,可能涌现内存溢出情形,以是只适宜核心功能加密。特殊的,JJEncode有浏览器依赖,代码不能在某种浏览器上运行。其余还有更强大的加密技能,可以直接将JS代码用C/C++实现,浏览器调用其编译后形成的文件来实行相应的功能,如Emscripten、WebAssembly。
变量稠浊是将带有含义的变量名、方法名、常量名随机变为无意义的类乱码字符串,降落代码可读性,如转成单个字符或十六进制字符串。
字符串稠浊是将字符串阵列化集中放置、并可进行MD5或Base64加密存储,使代码中不涌现明笔墨符串,这样可以避免利用全局搜索字符串的办法定位到入口点。
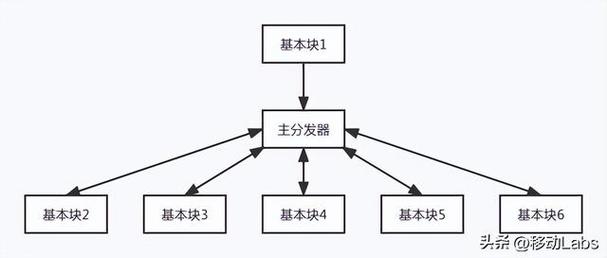
JS代码格式化的缘故原由是由于保存到本地的JS文件被压缩且不利于不雅观察,格式化即美化,反格式化即如果对JS代码进行格式化,则无法实行,导致浏览器假去世。掌握流平坦化通过打乱函数原有代码实行流程及函数调用关系,在逻辑处理块前统一加上驱动逻辑块,使代码逻变得混乱无序,大略来讲便是将代码块之间的关系打断,由一个分发器来掌握代码块的跳转,如图3和图4所示。
图3 稠浊前的代码流程图
图4 稠浊后的代码流程图
无用代码注入是随机在代码中插入不会被实行到的无用代码,进一步使代码看起来更加混乱。禁用掌握台输出是通过置空掌握台方法(console.log, console.debug, console.info, console.error, console.exception, console.trace, console.warn)的办法实现的。调试保护是基于调试器特性,对当前运行环境进行考验,加入一些逼迫调试debugger语句,使其在调试模式下难以顺利实行JS代码。域名锁定是使JS代码只能在指定域名下实行。
5、JavaScript-obfuscator稠浊在前端开拓中,作为JS稠浊主流的实现,JavaScript-obfuscator库和terser库供应了一些代码稠浊功能,也都有对应的Webpack 和Rollup打包工具的插件,从而方便实现页面的稠浊,终极输出压缩和稠浊后的JS代码,使得JS代码可读性大大降落,JavaScript-obfuscator的稠浊选项如图5所示。
图5 JavaScript-obfuscator稠浊的稠浊选项
JavaScript-obfuscator稠浊有浩瀚的参数,但JavaScript-obfuscator稠浊后代码的抽象语法树依次包含以下构造:大数组-->数组移位-->解密函数-->掌握流平坦化后的核心代码-->无限debugger自实行函数+去世代码注入。整体ob的强度险些完备取决于这四段的代码强度,个中包含加密前的逻辑。
常用稠浊工具有YUI Compressor、Google Closure Compiler、UglifyJS、JScrambler以及JavaScript-obfuscator系工具(obfuscator.io、soJSon v5.0 v6.0、JShaman)。
6、总结爬虫贡献了互联网50%的流量,它对付互联网的繁荣功不可没,但该技能同时也因“用场”而充满争议,爬虫与反爬虫一贯处于相互博弈的状态。此消彼长,在这一过程中反爬虫逐渐发展为具备智能交互、数据采集、实时打算、模型剖析以及决策判断等能力综合性安全系统,而不再是一个大略单纯工具。相信随着监管越来越严格,爬虫技能的利用边界也将更加明晰,互联网环境也将越来越清澈。















