
首先,我们打开头页,输入关键词:女装。↓↓↓

点击找一下,后会跳转到商品页面,如下图所示↓↓↓
这个时候我们就可以看到女装商品分类,和一些推举商品,
接下来我们不要急着爬这些商品数据,我们要找的是这些商品的分类目录地址。
谷歌浏览器右击检讨页面,仔细不雅观察会创造,每个分类的商品都有对应的地址,例如:连衣裙,对应的地址如下
我们进入连衣裙的href标签里面的地址,你会创造页面的标题已经从“女装”变成“女装-连衣裙”了,由于我们在这个页面看到的商品是经由淘宝分类后的,这一页内容只包含“女装-连衣裙”。
通过抓包 我们创造,创造这一页的真实的数据来源地址是:
https://s.1688.com/selloffer/rpc_async_render.jsonp?cps=1&n=y&filtOfferTags=279874&filt=y&keywords=%C5%AE%D7%B0&&categoryId=0&n=y&uniqfield=pic_tag_id&templateConfigName=marketOfferresult&pageSize=60&asyncCount=60&async=true&enableAsync=true&rpcflag=new&_pageName_=market&callback=jQuery172015741463935213496_1555383468519&beginPage=1
联系高下文,仔细不雅观察会创造,这是一个可以拼接的url,大致拼接办法如下:???
url = 'https://s.1688.com/selloffer/rpc_async_render.jsonp?cps=1&n=y&filtOfferTags=279874&filt=y&keywords='+keywords+'&categoryId='+categoryId+'&n=y&uniqfield=pic_tag_id&templateConfigName=marketOfferresult&pageSize=60&asyncCount=60&async=true&enableAsync=true&rpcflag=new&_pageName_=market&callback=jQuery172015741463935213496_1555383468519&beginPage='+str(i)
个中keywords不丢脸出是关键词,而且是进行url编码后的,而 i 这个明显是页码数字,categoryId英语好的一眼就知道是“种别ID”
这些参数是从哪来的呢?
回到前面,我们进入“女装-连衣裙”的页面,并查看源码,搜索这些关键词,
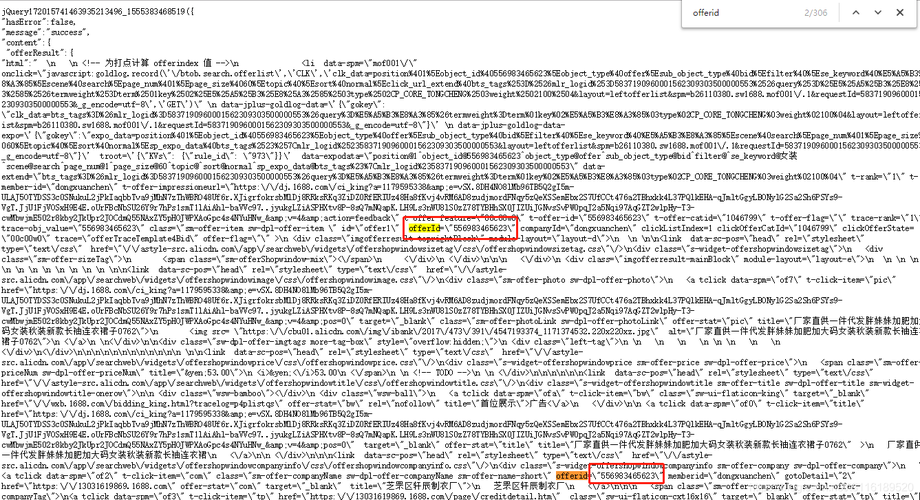
找到了:
接下来的事 就大略了,通过填参数拼接url,我们随意可以从女装-连衣裙分类下,获取几十页数据信息,或者从女装-日韩女装分类下获取数据信息。然后通过正则匹配到商品offerid。???
这些offerid代表的便是商品id,例如取出个中一个offerid:556983465623。那么这个商品的完全地址便是:
https://detail.1688.com/offer/556983465623.html
商品的名称、价格、销量、大小参数都可以从这个地址获取到。
下一篇我会教大家如何根据offerid抓取商品详情。
本篇完全代码如下:
???
# encoding: utf-8"""本脚本 用于根据关键词“女装”爬取1688全部分类商品的offerid"""import requestsimport reimport randomfrom lxml import htmlimport time """获取页面内容"""def get_html(url): html='' for x in range(5): try: resp = requests.get(url) html = resp.text if len(html) < 1000: continue else: return html except Exception as e: print('url {0}, throw exception: {1}'.format(url, e)) html = '' return html """从女装首页获取全部的分类地址"""def category_spider(): # 女装:%C5%AE%D7%B0 url = 'https://s.1688.com/selloffer/offer_search.htm?keywords=%C5%AE%D7%B0&button_click=top&earseDirect=false&n=y&netType=1%2C11' htmlstr = get_html(url) section = html.fromstring(htmlstr) links = section.xpath("//div[@class='s-widget-flatcat sm-widget-row sm-sn-items-control sm-sn-items-count-d fd-clr']/div[@class='sm-widget-items fd-clr']/ul//a/@href") return links """从数据源中正则匹配商品的offerid"""def spider(url): pid_list = list() htmlstr = get_html(url) goods_pid = re.findall(r'offerid=.?(\d+)', htmlstr) for pid in goods_pid: pid_list.append(pid) return pid_list def main(): # 获取女装商品下的所有分类目录地址:连衣裙、女式T恤、短袖T恤、外贸裙、日韩女装等等 links = category_spider() # 遍历所有分类 for link in links: sound = get_html(link) # 种别ID categoryId = re.findall(r'"categoryId":"(\d+)"', sound)[0] # 关键词 keywords = re.findall(r'"keywordsGbk":"(.?)"', sound)[0] # 每个种别商品,取10页数据 for i in range(1, 10): url = 'https://s.1688.com/selloffer/rpc_async_render.jsonp?cps=1&n=y&filtOfferTags=279874&filt=y&keywords='+keywords+'&categoryId='+categoryId+'&n=y&uniqfield=pic_tag_id&templateConfigName=marketOfferresult&pageSize=60&asyncCount=60&async=true&enableAsync=true&rpcflag=new&_pageName_=market&callback=jQuery172015741463935213496_1555383468519&beginPage='+str(i) pid_list = spider(url) print(pid_list) time.sleep(random.randint(1, 3)) if __name__ == '__main__': main()
代码输出结果展示:















