
一段大略的代码如下:
package mainimport ( "fmt")func main() { m := make(map[string]int64, 53) m["a"] = 111111111 m["b"] = 111111111 delete(m, "a") fmt.Println(m["a"], m["b"])}
为了定位到其底层实现,我们先看下go措辞的编译过程。

实在,作为一个编译型措辞,go程序会在编译阶段经由一系列处理后最终生成机器码
源码地址:cmd/compile/internal/syntax
1.词法剖析
解析成token,我们可以通过go供应的这两个package:"go/scanner"和"go/token"仿照
func TestToken(t testing.T) { src := []byte(`package main import "fmt" func main() { m := make(map[string]int64, 53) m["a"] = 111111111 fmt.Println(m["a"]) } `) var s scanner.Scanner fset := token.NewFileSet() file := fset.AddFile("", fset.Base(), len(src)) s.Init(file, src, nil, 0) for { pos, tok, lit := s.Scan() if tok == token.EOF { break } fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit) }}终极结果截取:
1:1 package "package"1:9 IDENT "main" ...7:13 IDENT "Println"7:20 ( ""7:21 IDENT "m" ...2.语法剖析
将扫描后天生的token转化为抽象语法树,每个go源码文件被布局为独立的语法树。同样,我们可以通过go供应的包:go/parser和go/ast来看下AST
func TestParser(t testing.T) { src := []byte(`package main import "fmt" func main() { m := make(map[string]int64, 53) m["a"] = 111111111 fmt.Println(m["a"]) } `) fset := token.NewFileSet() file, err := parser.ParseFile(fset, "", src, 0) if err != nil { log.Fatal(err) } ast.Print(fset, file)}输出结果截取:
0 ast.File { 1 . Package: 1:1 ... 6 . Decls: []ast.Decl (len = 2) { ...151 . } ...166 }类型检讨源码地址:cmd/compile/internal/gc
在这个阶段,会对上面天生的每个文件对应的AST进行节点遍历,对每个节点类型进行检讨,去掉声明但未利用,肃清dead code等
天生中间代码源码地址:
cmd/compile/internal/gc(AST转换成SSA)
cmd/compile/internal/ssa(SSA多轮通报及规则)
在这个阶段,AST会被转换为SSA(静态单赋值,Static Single Assignment)形式的中间代码,同时关键字,操作符会被转换成runtime函数。
如我们本日要说的map这个关键字及其操作就会在这个阶段进行转换。
我们可以通过实行下面命令产生ssa文件:
GOSSAFUNC=func go build go file 如:GOSSAFUNC=maps go build main.go
解释: 笔者当前版本为1.15.6,如果对main方法实行ssa天生会报panic
这个issue会在1.16版本进行修复
天生ssa文件内容如下,选择源码某行,可以看到对应的各阶段过程:
最终生成机器码定位
通过编译过程,我们看到map的底层实现是在编译阶段将map关键字及其操作进行了运行时转换。
而我们想要定位到这段代码map的干系实现,可以有多种办法:
1.借助go tool工具天生反汇编代码:go build -gcflags "-S" main.go或go tool compile -S main.go
2.gdb或dlv调试看反汇编代码
3.看中间代码(SSA天生)
由此我们可以定位到,map的底层实现。
数据构造:
// A header for a Go map.type hmap struct { count int // map中有效元素的个数 flags uint8 B uint8 // buckets个数为2^B,可装的元素个数为:负载因子 2^B,负载因子为6.5 noverflow uint16 // 溢出的bmap数量(近似值) hash0 uint32 // hash seed buckets unsafe.Pointer // 指向第一个bucket oldbuckets unsafe.Pointer // 在扩容的时候利用,为之前的buckets nevacuate uintptr // 迁居计数器,在扩容阶段利用 extra mapextra // optional fields}// mapextra holds fields that are not present on all maps.type mapextra struct { overflow []bmap // 存储溢出的bmap oldoverflow []bmap // 扩容阶段利用,为之前的overflow nextOverflow bmap // 下一个待利用的空闲bmap,溢出时利用}// A bucket for a Go map.type bmap struct { tophash [bucketCnt]uint8 // key的hash值高8位}须要指出的是bmap作为真正存储map数据的地方,为什么只有tophash字段,其key和value呢?实在我们知道map的key和value有多种类型,go作为强类型措辞,在定义后其类型就确定了,以是bmap的key和value字段类型就可以在编译阶段确定,避免了穷举,减少代码繁芜度。
bmap中key和value类型通过func bmap(t types.Type) types.Type确定。
bmap构造为:
type bmap struct { topbits [8]uint // key的hash高8位 keys [8]keytype // key elems [8]elemtype // value overflow uintptr // 溢出后下一个bmap}go map实现总览先上总结,大家在学习的时候根据总结来看源码,更随意马虎理解。
1.编译器会根据key类型,位数来映射不同的运行时函数,但他们实现大体是同等的。如访问运行时函数:mapaccess,mapaccess1_fast32,mapaccess2_fast64,mapaccess1_faststr等,以是大家看到不同的文章中有对不同函数的解析
2.go利用bmap数据构造来存储key和value
3.查找时先定位key属于哪个bucket,再查看位于bmap的哪个位置
4.go的map利用开放地址法来办理hash冲突,并放入bmap的overflow字段指向的bmap
回到最开始的代码,来分别看下初始化,赋值,删除,扩容过程
代码比较多,我仅贴出部分,函数我会给出链接,大家可以跳进去看源码,如果看不到,可到我的博客中看:https://www.imflybird.cn/。
初始化make(map[k]v, hint)或map[k]v{}
初始化函数家族:
func makemap_small() hmap 在 hint <= 8 或不供应hint时编译器会利用这个函数用来初始化
func makemap64(t maptype, hint int64, h hmap) hmap
func makemap(t maptype, hint int, h hmap) hmap
实在除了上面外,还有可能在汇编层面看不到makemap干系函数,实在编译器还会根据逃逸剖析结果,来确定map初始化,干系函数位置在这里
我们紧张看makemap的实现。
1.h.hash0 = fastrand() //初始化hash0
利用随机数对hash0进行初始化。内部利用xorshift64进行随机数天生,我们之前先容的分布式唯一ID天生文章中的实现也是利用这种高效的随机数天生算法。
而fastrandseed正是我们在openresty协程调度比拟go协程调度文章中提到的runtime.args初始化阶段由startupRandomData字段天生的
2.利用func overLoadFactor(count int, B uint8) bool 函数初始化h.B
B从0开始,不断增加,直到找到B使得 负载因子 2^B >= count,个中负载因子为6.5。对付我们上面这段代码,count便是53.得到的B便是4.
3.初始化h.buckets,h.extra.nextOverflow
至此,初始化完成,如下图所示:
赋值
赋值家族函数:mapassign。同样,我们结合本例,看下赋值过程。
在本例中,赋值函数为:func mapassign_faststr(t maptype, h hmap, s string) unsafe.Pointer
1.again标签内:
bucket := hash & bucketMask(h.B) // hash值的低2^h.B-1位来定位到这个key属于哪个bucket
b := (bmap)(unsafe.Pointer(uintptr(h.buckets) + bucketuintptr(t.bucketsize))) // 这个bucket内的bmap
top := tophash(hash) // hash的高8位为tophash
2.bucketloop标签内:
for { for i := uintptr(0); i < bucketCnt; i++ { if b.tophash[i] != top { if isEmpty(b.tophash[i]) && insertb == nil { insertb = b inserti = i } if b.tophash[i] == emptyRest { break bucketloop } continue } k := (stringStruct)(add(unsafe.Pointer(b), dataOffset+i2sys.PtrSize)) if k.len != key.len { continue } if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) { continue } // already have a mapping for key. Update it. inserti = i insertb = b goto done } ovf := b.overflow(t) if ovf == nil { break } b = ovf}双重for循环探求得当插入点
遍历顺序:从当前bmap开始,从前今后遍历,如果找不到,会从overflow的bmap中连续查找我们考虑两种情形:1.刚初始化完毕:此时每个bmap的tophash均为emptyRest(即0值),以是找到了当前的插入点直接跳出bucketloop标签。2.被删除过,则tophash值为emptyOne(即1值),如当前bmap的tophash为:|1|1|1|76|0|0|0|0|,则会优先插入到第一个值为1的位置。此时还要连续遍历看是否有和打算出的top值相等的tophash值没,如果有,且key值相等,则更新插入点。可以看出插入赋值是一个紧凑的过程(有空位时优先往插入前面的)
if insertb == nil { // all current buckets are full, allocate a new one. insertb = h.newoverflow(t, b) inserti = 0 // not necessary, but avoids needlessly spilling inserti}如果没找到插入点,则会创建溢出的bmap(拉链法):
1.会优先利用之前预分配的bucket(h.extra.nextOverflow)如果当前h.extra.nextOverflow不是预分配的末了一位,则把h.extra.nextOverflow今后移一位(之前先容数据构造时提到,nextOverflow便是下一个待分配的bmap)如果是末了一位,则把其overflow置为nil(初始化时我们看到末了一个bucket的overflow指向了第一个bucket),同时h.extra.nextOverflow无可用bucket,置为nil2.如果无可用的nextOverflow,则新建一个对付m[k]=v,我们看到赋值函数并没有吸收v,而是返回了v的内存指针
实在,是编译器天生的汇编指令来完成值的存储的,我们用gdb来看下反汇编代码:
0x00000000004999e0 <+160>: callq 0x4117c0 <runtime.mapassign_faststr> 0x00000000004999e5 <+165>: mov 0x20(%rsp),%rax 0x00000000004999ea <+170>: mov %rax,0x60(%rsp) 0x00000000004999ef <+175>: test %al,(%rax) 0x00000000004999f1 <+177>: movq $0x69f6bc7,(%rax) // 寄存器间接寻址,rax存储的是v的内存地址,把 111111111放入这个内存地址 0x00000000004999f8 <+184>: lea 0xe841(%rip),%rax # 0x4a8240当然在赋值过程中会涌现须要扩容的情形,我们后面说
访问访问家族函数:mapaccess。同样,我们结合本例,看下访问过程。
本例中访问函数为:func mapaccess1_faststr(t maptype, h hmap, ky string) unsafe.Pointer
上面讲了赋值过程的查找,访问也是一样的过程。访问函数中区分了只有一个bucket和多bucket情形,我们看下多bucket情形。
1.同样须要先打算key的hash值
2.利用hash值的低2^B-1位定位出key所在bucket
3.利用hash值的高8位来匹配tophash
4.依次在当前bucket所在的bmap中探求,没有的话在overflow中探求,循环探求,直到结束
删除删除家族函数:mapdelete。
本例中删除函数为:func mapdelete_faststr(t maptype, h hmap, ky string)
1.删除前同样须要先查找到该key的位置,查找过程同上面的访问过程
2.b.tophash[i] = emptyOne // 删除仅需把tophash值设为1
3.每删除一个key,须要查看当前key位置的下一位tophash值是否是emptyRest(即是否是0值),如果是0值的话,须要把下一位前的emptyOne变更为emptyRest,直到碰着非emptyOne为止。
for { b.tophash[i] = emptyRest if i == 0 { if b == bOrig { break // beginning of initial bucket, we're done. } // 从当前bucket的第一个bmap查找,直到当前bmap的前一个停滞 c := b for b = bOrig; b.overflow(t) != c; b = b.overflow(t) { } i = bucketCnt - 1 } else { i-- } if b.tophash[i] != emptyOne { break } }我们通过一个示例来看下这个过程:
扩容
由编译器确定选用哪个函数进行增量式扩容: growWork。
在赋值阶段,可能会触发扩容,触发条件为:
1.本次元素如果插入,负载将达到临界点:插入的元素数量 > 负载因子2^B;此时容量需扩大一倍
2.bmap的overflow过多,overflow数量 >= 2^(B&15)的数量。此时容量不变,目的仅是使打消删除造成的空洞,减少overflow,使数据构造更紧凑
我们看下过程:
1.扩容开始,利用func hashGrow(t maptype, h hmap)进行扩容准备:判断是否须要容量翻倍,并设置h.oldbuckets为h.buckets,新建buckets和nextOverflow
2.增量迁居:迁居家族函数为evacuate,在赋值和删除时,定位到key所属的bucket,则对该bucket内的bmap及其overflow的bmap进行迁居。 对付我们这个例子中,如果一直增加元素直至扩容,则迁居函数为 func evacuate_faststr(t maptype, h hmap, oldbucket uintptr)
3.直至迁居完毕。
迁居利用的数据构造为:
type evacDst struct { b bmap // current destination bucket i int // key/elem index into b k unsafe.Pointer // pointer to current key storage e unsafe.Pointer // pointer to current elem storage}我们可用把上面这个看作一个箱子。
我们看下迁居过程:
1.如果扩容是等量扩容,则利用一个箱子迁居;如果是双倍扩容,则利用两个箱子进行迁居。 2.从旧bucket中bmap第一个开始,顺序迁居直至overflow也迁居完毕停滞。
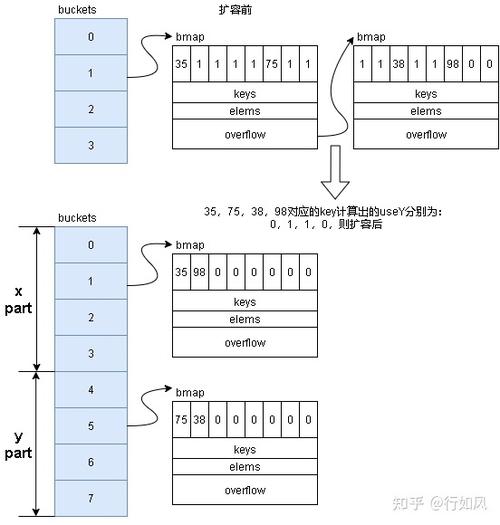
3.如果是双倍扩容,则会分为高和低两部分(两部分容量相等),并利用两个exacDst:y和x分别对应高位和低位。打算落到高位还是低位。
4.迁居过程中tophash值不变。这样在赋值和删除时,仍通过高八位定位bmap中的位置。
双倍扩容后,如何确定key所属的bucket呢,我们看到双倍扩容会利用两个exacDst进行分流,我们看到确定是利用x还是y时,打算办法为:
hash := t.hasher(k, uintptr(h.hash0))if hash&newbit != 0 { useY = 1}而定位bucket打算办法为:
bucket := hash & bucketMask(h.B)个中newbit为原来的2^B,如果得到useY=1,则解释高位为1,终极的bucket为2^h.B(原来的B)+原来的bucket。
举个例子:
扩容前:h.B为4(即100),原来的bucket为:hash&11,假设为2,即10
扩容后:8(1000),现在的bucket为:hash&111
useY=1,则解释hash值后三位为1??,现在的bucket=110,即 2^h.B(原来的B)+原来的bucket=4+2=6。
等量扩容如下图:
双倍扩容如下图:
PHP的map实现
php版本:7.4.15
其实在php中,在措辞层面,准确来说叫数组,而数组底层实现了map的功能。我们知道,map的key定位是须要hash函数来实现O(1)查询的,是无序的,而php中是如何兼顾数组的有序及hash函数的映射呢?
我们看其数据构造,定义在Zend/zend_types.h文件里:
typedef struct _Bucket { zval val; zend_ulong h; / hash value (or numeric index) / zend_string key; / string key or NULL for numerics /} Bucket;typedef struct _zend_array HashTable;struct _zend_array { zend_refcounted_h gc; // 引用计数,gc利用 union { // 赞助信息 struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar _unused, zend_uchar nIteratorsCount, zend_uchar _unused2) } v; uint32_t flags; } u; uint32_t nTableMask; // 哈希值打算掩码,即是nTableSize的负值(nTableMask = -nTableSize) Bucket arData; // 指向数组的第一个Bucket uint32_t nNumUsed; // 已利用的Buckets数量 uint32_t nNumOfElements; // 有效元素数量 uint32_t nTableSize; // 数组总容量,2^n uint32_t nInternalPointer; // 内部遍历利用指针 zend_long nNextFreeElement; // 下一个可用数字索引 dtor_func_t pDestructor; //析构函数};在php中,分为两部分:
1.数组元素表,每个数组内都是一个Buckets。容量为2^n,插入元素时顺序插入,新插入的元素索引idx为ht->nNumUsed++,nNumUsed是递增的,表示已利用的Buckets数量。
2.索引表,其和数组元素容量等长。存储每个key在数组元素中的索引idx。 如果插入时涌现了hash冲突,通过拉链法办理hash冲突,新插入的这个元素的val.u2.next为该key所在索引表内存储的索引值。
索引打算方法:nIndex = h | ht->nTableMask;
个中h为key经由times 33算法后的值,对应打算函数为:zend_inline_hash_func(const char str, size_t len)
如:一个容量为4,有两个元素的数组构造图总览如下图:
添加
对应函数:zend_hash_index_add_or_update()
zend_hash_str_add_or_update()
数组元素表顺序插入,更新索引表对应位置数据。值得把稳的是,php中并没有对hash冲突进行分外处理,而是每个key插入数组中的Bucket时,都让其val.u2.next为当前索引表中的值,然后再更新索引表中的值。这样如果没有冲突产生,则val.u2.next值就为-1。无需分外处理。
如下图,新增一个元素,且涌现了hash冲突:
查找
先在索引表中拿到数组元素的idx,然后拿到数据,如果key不等,在其val.u2.next中进行比较,直至结束。
删除先找到该元素,然后将该位置数据val.type置为IS_UNDEF,并不移动数据。
扩容在添加的过程中,如果已利用的buckets数量到达元素数组总容量,则触发扩容,对应函数为zend_hash_do_resize()。
1.如果ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5),则不变动容量,仅重新hash
2.如果ht->nTableSize < HT_MAX_SIZE,则会进行双倍扩容。此时会申请双倍容量内存,并把之前的数据全部拷贝到新地址,开释旧内存,然后重新hash
重新hash时,如果存在空洞(删除导致元素数组空洞),则须要从前今后,把删除的元素往前移,把空洞给填满(使数据更紧凑)。对应函数为zend_hash_rehash(HashTable ht)
比拟1.php利用索引表和元素数组两部分来实现map和数组的功能;而go利用元素数组部分,每个数组内最多可装8个数据,利用负载因子掌握扩容,两者的实现各有千秋。
2.两者都利用拉链法来处理hash冲突。
3.在插入时,如果涌现过空洞(删除导致),go更方向往前插入来使得构造更紧凑,而php是顺序插入,在扩容阶段来处理空洞。
4.在扩容时,go利用增量扩容,而php是全量。
参考:go源码1.15
golang-notes/map.md
php源码7.4.15















