
文章目录
[+]
山脊图(也称为Joy Plot)是一种用于可视化和比较两个或多个长尾分布或者多变量分布的数据可视化图形。它实质上是一组重叠的密度图,每个密度图代表一个数据子集。山脊图的特点和用场如下:
比较分布: 山脊图非常适宜比较不同组或种别中的分布情形。每个组的分布都是一个单独的山脊(或线),并且它们沿着共同的基线排列,使得不同组之间的分布随意马虎比较。展示密度估计: 每个山脊常日是利用核密度估计(KDE)天生的,这供应了一种平滑和连续的数据分布视图。节省空间: 由于山脊是重叠的,山脊图可以在有限的空间内展示多个分布,这使得它们非常适宜于展示大量组或类别的数据。都雅: 山脊图在视觉上很吸引人,它们的流线型和重叠性子为繁芜数据供应了一种清晰和引人瞩目的表示办法。虽然山脊图在很多情形下都很有用,但在阐明时须要小心,特殊是在处理重叠较多的情形,由于重叠可能会影响对某些组密度的视觉解读。此外,山脊图可能不适宜处理有大量类别的数据集,由于图形可能会变得拥挤和难以解读。

要利用R和ggplot2包来实现这一目标,你可以按照以下步骤操作:
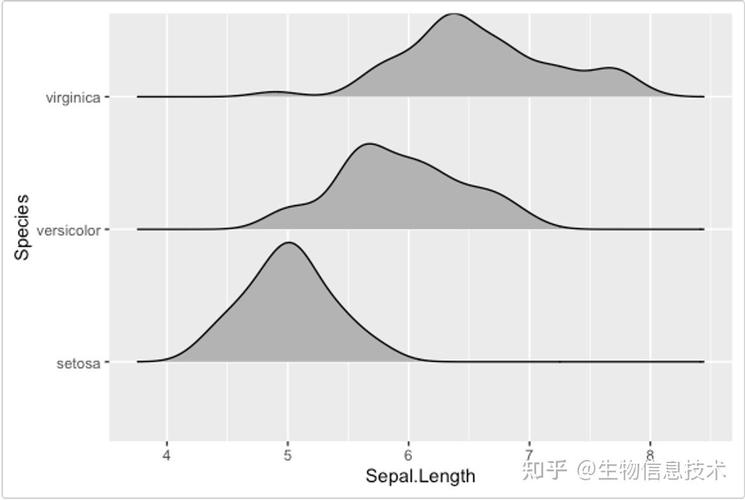
(图片来自网络侵删)
加载必要的库:
须要ggplot2用于绘图。ggridges用于创建山脊图。datasets用于加载iris数据集。加载数据:
从datasets包中加载iris数据集。绘制山脊图:
利用ggplot2和ggridges来创建山脊图。以下是全体R代码:
# 加载必要的库library(ggplot2)library(ggridges)library(datasets)# 加载数据iris<- read.csv(iris.csv) #更换为所要利用的实际文件路径,此处iris为示例数据# 绘制山脊图ggplot(iris, aes(x = Petal.Length, y = Species, fill = Species)) + geom_density_ridges(alpha = 0.7) + scale_fill_viridis_d(option = "C") + labs(title = 'Ridge Plot of Iris Petal Lengths', x = 'Petal Length', y = 'Species') + theme_ridges() + theme(legend.position = "none") # 隐蔽图例















