
什么是 OCR?
OCR 指的是光学字符识别。它用于从扫描的文档或图片中读取文本。这项技能被用来将险些任何一种包含书面文本(手写或者机器写的字)的图像转换成机器可读的文本数据。

在这里,我们将构建一个 OCR,它只读取您你望它从给定文档中读取的信息。
OCR 有两个紧张模块:
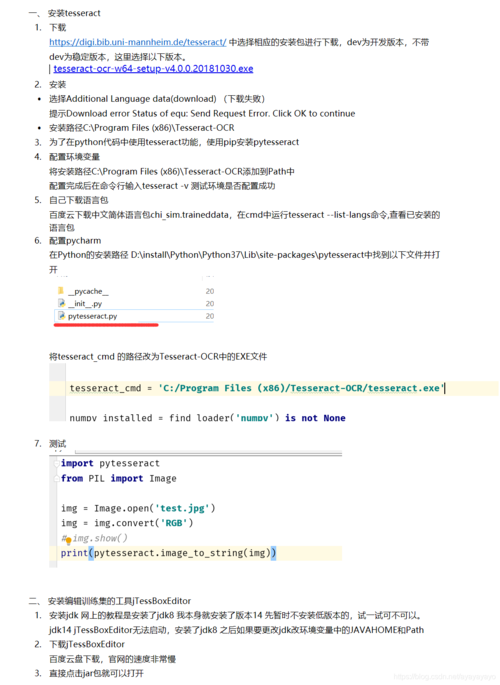
文本检测
文本识别
文本检测
我们的第一个任务是从图像/文档中检测所需的文本。常日,根据须要,你不想阅读全体文档,而只想阅读一条信息,如信用卡号、Aadhaar/PAN 卡号、姓名、账单金额和日期等。检测所需文本是一项艰巨的任务,但由于深度学习,我们将能够有选择地从图像中读取文本。
文本检测或一样平常的目标检测是随着深度学习而加速的一个密集研究领域。本日,文本检测可以通过两种方法来实现。
基于区域的检测器
单点检测器
在基于区域的方法中,第一个目标是找到所有有工具的区域,然后将这些区域通报给分类器,分类器为我们供应所需工具的位置。以是,这是个过程分为 2 步。
首先,它找到边界框,然后找到它的类。这种方法更准确,但与单点检测方法比较速率相对较慢。Faster R-CNN 和 R-FCN 等算法采取这种方法。
然而,单点检测器同时预测边界盒和类。作为一个单步过程,它要快得多。然而,必须把稳的是,单点检测器在检测较小物体时表现不佳。SSD 和 YOLO 便是单点检测器。
在选择目标检测器时,常日会在速率和精度之间进行权衡。例如,速率更快的 R-CNN 具有最高的准确性,而 YOLO 则是最快的。这是一篇很好的文章,它比较了不同的检测器,并对它们的事情事理供应了全面的见地。
决定利用哪一个,完备取决于你的诉求。在这里,我们利用 YOLOv3 紧张是由于:
在速率方面谁也比不上它
对我们的运用来说有足够的准确性
YOLOv3 具有特色金字塔网络(FPN)以更好地检测小目标
说得够多了,让我们深入理解 YOLO。
利用 YOLO 进行文本检测
YOLO 是一个最前辈的实时目标检测网络,有很多版本,YOLOv3 是最新、最快的版本。
YOLOv3 利用 Darknet-53 作为特色提取程序。它统共有 53 个卷积层,因此被命名为「Darknet-53」。它有连续的 3×3 和 1×1 卷积层,并有一些短连接。
为了分类,独立的逻辑分类器与二元交叉熵丢失函数一起利用。
利用 Darknet 框架演习 YOLO
我们将利用 Darknet 神经网络框架进行演习和测试。该框架采取多尺度演习、大量数据扩充和批量规范化。它是一个用 C 和 CUDA 编写的开源神经网络框架。它速率快,易于安装,支持 CPU 和 GPU 打算。
你可以在 GitHub 上找到源代码:https://github.com/pjreddie/darknet
下面是安装 Darknet 框架的大略方法。只有 3 行!
(如果要利用 GPU,请在 makefile 中更新 GPU=1 和 CUDNN=1。)
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
我们开始吧~
首先获取数据
在任何基于机器学习的项目中,数据都是第一步也是最主要的。以是,无论你的运用程序是什么,确保你有大约 100 个图像。如果你的图像数量较少,则利用图像增强来增加数据的大小。在图像增强中,我们紧张通过改变图像的大小、方向、光芒、颜色等来改变图像。
有许多方法可用于增强,你可以很随意马虎地选择任何你喜好的方法。我想提到一个名为 Albumentations 的图像增强库,它是由 Kaggle Masters 和 Grandmaster 构建的。
我网络了 50 互联网上的 PAN 卡图像,利用图像增强技能,创建了一个包含 100 张 PAN 卡图像的数据集。
数据标注
一旦我们网络了数据,我们就进入下一步,即标记它。有许多可用的免费数据注释工具。我利用 VoTT v1 ,由于它是一个大略的工具,事情起来很方便。按照此链接,理解数据标注的过程。
请把稳,标记要从图像数据中读取的所有文本字段非常主要。它还天生演习期间所需的数据文件夹。
标记后,请确保将导出格式设置为 YOLO。标注后,将所有天生的文件复制到存储库的数据文件夹中。
演习
为了肃清所有的困惑,Darknet 有两个存储库,一个是原作者的,另一个是分支。我们利用分支存储库,它的文档很好。
要开始演习 OCR,首先须要修正配置文件。你将在名为「yolov3.cfg」的「cfg」文件夹中得到所需的配置文件。在这里,你须要变动批大小、细分、类数和筛选器参数。按照文档中给出的配置文件中所需的变动良行操作。
我们将开始演习,预先演习 darknet-53,这将有助于我们的模型早日收敛。
用这个命令开始演习:
./darknet detector train data/obj.data yolo-obj.cfg darknet53.conv.74
最好的是它有多个 GPU 支持。当你看到均匀丢失'0.xxxxxx avg'在一定次数的迭代后不再减少时,你该当停滞演习。正如你不才面的图表中看到的,当丢失变为常数时,我停滞了 14200 次迭代。
丢失曲线
从上一个权重文件中得到最佳结果并不总是这样。我在第 8000 次迭代中得到了最好的结果。你须要根据 mAP(均匀精度)得分对它们进行评估。选择具有最高分数的权重文件。以是现在,当你在一个样本图像上运行这个检测器时,你将得到检测到的文本字段的边界框,从中你可以很随意马虎地裁剪该区域。
虚拟 PAN 卡上的文本检测
文本识别
现在我们已经实现了用于文本检测的自定义文本检测器,接下来我们将连续进行文本识别。你可以构建自己的文本识别器,也可以利用开源的文本识别器。
虽然,实现自己的文本识别器是一个很好的实践,但是获取标签数据是一个寻衅。但是,如果你已经有很多标签数据来创建自定义文本识别器,那么它的准确性可能会提高。
然而,在本文中,我们将利用 Tesseract OCR 引擎进行文本识别。只要稍加调度,Tesseract OCR 引擎就可以为我们的运用程序创造奇迹。我们将利用 Tesseract 4,这是最新版本。谢天谢地,它还支持多种措辞。
安装 Tesseract OCR 引擎
他支持 Ubuntu 14.04、16.04、17.04、17.10 版本,对付 Ubuntu 18.04 版本,跳过前两个命令。
sudo add-apt-repository ppa:alex-p/tesseract-ocr
sudo apt-get update
sudo apt install tesseract-ocr
sudo apt install libtesseract-dev
sudo pip install pytesseract
组合在一起
一旦我们实现了文本检测和文本识别的过程,就该当将它们结合起来,以实现以下流程:
从图像中检测要求的区域
把检测到的区域传给 Tesseract
将 Tesseract 的结果存储为所需的格式
从上面的图中,你可以理解到,首先 PAN 卡的图像被通报到 YOLO 中。然后,YOLO 检测到所需的文本区域并从图像中裁剪出来。稍后,我们将这些区域逐一通报给 Tesseract。Tesseract 读取它们之后,我们存储这些信息。
现在,你可以选择任何形式的来表示结果。在这里,我利用 excel 表格来显示结果。
我已经开放了全体管道。复制存储库并将数据文件夹和演习后天生的权重文件移动到此存储库目录。你须要通过以下命令在此处安装 darknet。
bash ./darknet.sh
现在用这个命令运行你的 OCR:
pan.py -d -t
祝贺你!
现在你可以在输出文件夹中以 CSV 文件的形式看到 OCR 结果。检测自定义 OCR 时,可能须要变动图像的大小。为此,请调度 locate_asset.py 文件中的 basewidth 参数。
资源
Object detection
Region-based methods
Single-shot methods
Comparison of various detectors
通过本文,我希望你能够全面理解光学字符识别中涉及的各个步骤,并在阅读本文的同时实现自己的 OCR 程序。我鼓励你在不同的图像集上考试测验这种方法,并为你的运用程序利用不同的检测器,看看什么样的方法最有效。
via:https://medium.com/saarthi-ai/how-to-build-your-own-ocr-a5bb91b622ba
雷锋网雷锋网雷锋网















