
为什么学
最近对编译器很感兴趣,为什么要学习编译事理,于我而言是由于最近须要写一个DSL,须要一个阐明器,而对付大部分程序员来说,学习编译器可能有以下三个方面:
(1)学习编译器设计,可以帮助更好的理解程序以及打算机是怎么运行的,同时编写编译器或者阐明器须要大量的打算机技巧,对技能 也是一个提升。

(2)口试须要,所谓“事情拧螺丝,口试造火箭”。学习编译器设计有助于加强打算机根本能力,提高编码素养,更好的应对口试,毕竟你不知道你的口试官是不是对这个也感兴趣。
(3)事情须要,有的时候你可能须要创造一些领域特定措辞或者发明一种新措辞(这个须要不太多),这个时候你就须要写一个编译器或者阐明器来知足你的须要了。
编译器与阐明器编译器将以某种措辞编写的程序作为输入,产生一个等价的程序作为输出,常日这个输入措辞可能便是C或者C++,等价的目标程序常日是某种处理器的指令集,然后可以直接运行该目标程序。阐明器与编译器的不同就在于它直接实行由编程措辞或者脚本编写的代码,并不会把源代码预编译成指令集,它会实时地返回结果。如下图所示
compiler.jpg
还有一种编译器,它将一种高等措辞翻译成另一种高等措辞,比如将php转为C++,这种编译器一样平常称为源到源的转换器。
目标这个博客系列的目标实在很小,便是利用Kotlin去实现一个小型的阐明器来进行正数的四则运算,由于本人目前也是学习阶段,以是只能先弄一个这样的小功能,等技能提高了再开新番。该系列只会涉及到词法剖析、语法剖析、抽象语法树等编译器前审察干的观点,至于编译器后审察干的代码优化以及代码天生不会涉及。
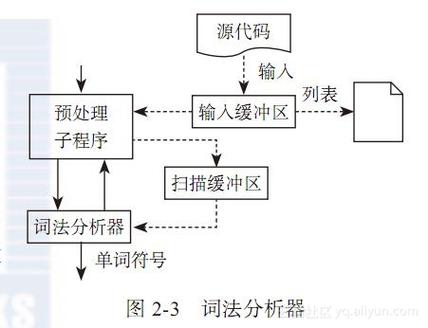
词法剖析词法剖析的任务是将字符流变换为输入措辞的单词流。每个单词都必须归类到某个语法范畴中,也叫词类。词法剖析器是编译器中唯一会打仗到程序中每个字符的一趟处理。这里有几个观点要解释,比如词类,列比我们平时的措辞,我们会说“走”是动词,“跑”也是动词,“俊秀”是形容词,“俏丽”也是形容词,这里动词和形容词,便是词类,代表着单词的分类,还有一个便是词素,前面说的“走”,“跑”,"俊秀“等实在便是词素,也便是详细的单词内容,实际的文本。词法剖析的浸染便是将源代码中的文件按字符读入,根据读入的字符识别单词组成一个词法单元,每个词法单元由词法单元名和词素组成,例如<形容词:俊秀>,个中形容词便是词法单元名,可以看做和词类相同,俊秀便是词素,而对付我们要实现的打算器来说可能便是<PLUS,+>,<NUMBER,9>这样的。
代码定义词法单元前面说过,词法单元由词法单元名和词素组成,以是我们定义一个类Token来代表词法单元,TokenType这个列举类来代表词法单元名
data class Token(val tokenType: TokenType, val value: String) { override fun toString(): String { return "Token(tokenType=${this.tokenType.value}, value= ${this.value})" }}enum class TokenType(val value: String) { NUMBER("NUMBEER"), PLUS("+"), MIN("-"), MUL(""), DIV("/"), LBRACKETS("("), RBRACKETS(")"), EOF("EOF")}
可以看到我有8个TokenType,8个TokenType代表着8个词法单元名,也便是8个词类,个中EOF代表END OF FILE及源文件扫描结束。
定义词法剖析器import java.lang.RuntimeExceptionclass Lexer(private val text: String) { private var nextPos = 0 private val tokenMap = mutableMapOf<String, TokenType>() private var nextChar: Char? = null init { TokenType.values().forEach { if(it!=TokenType.NUMBER) { tokenMap[it.value] = it } } nextChar = text.getOrNull(nextPos) } fun getNextToken(): Token { loop@ while (nextChar != null) { when (nextChar) { in '0'..'9' -> { return Token(TokenType.NUMBER, getNumber()) } ' ' -> { skipWhiteSpace() continue@loop } } if (tokenMap.containsKey(nextChar.toString())) { val tokenType = tokenMap[nextChar.toString()] if (tokenType != null) { val token = Token(tokenType, tokenType.value) advance() return token } } throw RuntimeException("Error parsing input") } return Token(TokenType.EOF, TokenType.EOF.value) } private fun getNumber(): String { var item = "" while (nextChar != null && nextChar!! in '0'..'9') { item += nextChar advance() if ('.' == nextChar) { item += nextChar advance() while (nextChar != null && nextChar!! in '0'..'9') { item += nextChar advance() } } } return item } private fun skipWhiteSpace() { var nextChar = text.getOrNull(nextPos) while (nextChar != null && ' ' == nextChar) { advance() nextChar = text.getOrNull(nextPos) } } private fun advance() { nextPos++ nextChar = if (nextPos > text.length - 1) { null } else { text.getOrNull(nextPos) } }}
先算作员变量,个中text代表的是源文件内容,nextPos代表着源代码中下一个字符的位置,nextChar代表着源代码中下一个字符,tokenMap代表着词素和词法单元是唯一对应的Map,个中key代表的是词素,TokenType代表的词法单元,可以看到在我们的定义中除了TokenType.NUMBER其他都是存在唯一对应的,由于对付数字来说,9对应的是词法单元是NUMBER,10对应的词法单元也是NUMBER,不存在唯一对应,以是须要我们单独识别。
布局方法很大略,为tokenMap和nextChar打算赋值
再看剩下的方法,实在这个词法解析器对外暴露的只有getNextToken方法用以返回Token,其他方法都是private的用以赞助返回Token,在getNextToken方法中,有一个while循环判断nextChar是否为null,如果为null代表着源文件已经处理完毕,返回Token(TokenType.EOF, TokenType.EOF.value),否则的话就判断当前字符是不是数字,如果是数字,就返回Token(TokenType.NUMBER, getNumber()),个中getNumber方法用以获取数字内容直到nextChar不再为数字为止。如果nextChar为空格,就跳过空格skipWhiteSpce,然后连续当前循环,如果既不是数字也不是空格,那么就根据tokenMap获取相应的TokenType,看看是不是运算符号或者括号,如果也不存在,解释输入中存在非数字和四则运算符号以及括号的字符,抛出错误"Error parsing input”。
测试import java.util.fun main() { while(true) { val scanner = Scanner(System.`in`) val text = scanner.nextLine() val lexer = Lexer(text) var nextToken = lexer.getNextToken() while (TokenType.EOF != nextToken.tokenType) { println(nextToken.toString()) nextToken = lexer.getNextToken() } }}
编写测试代码,打印相应的token,运行代码,在代码中输入数据并回车,查当作果
截屏2021-04-20 上午10.37.01.png
至此词法剖析器基本完成,实在词法剖析器还有很多观点可说,比如说正则表达式,然后由正则表达式天生NFA,NFA运用最小子集法天生DFA,再由DFA天生最小DFA,个中有很多观点,但是个人认为太多的观点会让人迷茫,不如先由大略的例子开始,然后逐步加深理解,熟习观点
代码已经上传到github,后续会不断更新 CompilerDemo[1]















