
数据仓库的目的是构建面向剖析的集成化数据环境,为企业供应决策支持(Decision Support)。实在数据仓库本身并不“生产”任何数据,同时自身也不须要“消费”任何的数据,数据来源于外部,并且开放给外部运用,这也是为什么叫“仓库”,而不叫“工厂”的缘故原由。因此数据仓库的基本架构紧张包含的是数据流入流出的过程,可以分为三层——源数据、数据仓库、数据运用。
数据仓库最紧张的事情是从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是 ETL(抽取Extra, 转化 Transfer, 装载 Load)的过程,ETL 是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和掩护事情的大部分精力便是保持 ETL 的正常和稳定。

随着海量数据问题的涌现,海量管理能力,多类型,变革快,高可用性,低本钱,高端可扩展性等需求给企业数据计策带来了巨大的寻衅。企业数据仓库、数据中央的技能选型变得尤其主要!
1、面向主题
是企业系统信息中的数据综合、归类并进行剖析的一个抽象,对应企业中某一个宏不雅观剖析领域所涉及的剖析工具。
比如购物是一个主题,那么购物里面包含用户、订单、支付、物流等数据综合,对这些数据要进行归类并剖析,剖析这个工具数据的一个完全性、同等性的描述,能完全、统一的划分工具所设计的各项数据。
如果此时要统计一个用户从浏览到支付完成的韶光时,在购物主题中短缺了支付数据或订单数据,那么这个工具数据的完全性和同等性就可能无法担保了。
2、数据集成
数据仓库的数据是从原有分散的数据库中的数据抽取而来的。
操作型数据和支持决策剖析型(DSS)数据差别甚大,这里须要做大量的数据洗濯与数据整理的事情。
第一:每一个主题的源数据在原有分散数据库中的有许多重复和不一致,且不同数据库的数据是和不同的运用逻辑捆绑的。
第二:数据仓库中的综合性数据不能从原有的数据库系统直接得到,因此在数据进入数据仓库之前要进过统一和综合。(字段同名异意,异名同义,长度等)
3、不可更新
数据仓库的数据紧张是供应决策剖析用,设计的数据紧张是数据查询,一样平常情形下不做修正,这些数据反响的是一段较永劫光内历史数据的内容,有一块修正了影响的是全体历史数据的过程数据。
数据仓库的查询量每每很大,以是对数据查询提出了更高的哀求,哀求采取各种繁芜的索引技能,并对数据查询的界面友好性和数据凸显性提出更高的哀求。
4、随韶光不断变革
数据仓库中的数据不可更新是针对运用来说,从数据的进入到删除的全体生命周期中,数据仓库的数据是永久不变的。
数据仓库的数据是随着韶光变革而不断增加新的数据。
数据仓库随着韶光变革不断删去久的数据内容,数据仓库的数据也有时限的,数据库的数据时限一样平常是60 ~ 90天,而数据仓库的数据一样平常是5年~10年。
数据仓库中包含大量的综合性数据,这些数据很多是跟韶光有关的,这些数据特色都包含韶光项,以标明数据的历史期间。
三、数据仓库和数据库的差异数据库的操作:一样平常称为联机事务处理OLAP(On-Line Transaction Processing),是针对详细的业务在数据库中的联机操作,具有数据量较少的特点,常日对少量的数据记录进行查询、修正。
数据仓库的操作:一样平常称为联机剖析处理OLAP(On-Line Analytical Processing),是针对某些主题(综合数据)的历史数据进行剖析,支持管理决策。
四、数据仓库--MPP架构
1、传统数据仓库
数据仓库有着如下几个特性:主题导向、集成性、韶光差异性、不变动性,而每一个特性的利用程度和趋向,将决定这个数据仓库的能力,但是也由于业务导向性的存在,也常常会占主导浸染,将数据仓库向数据集市转化,而使得数据仓库本身变的臃肿,查询效率低落,剖析细颗粒度的数据变的较为困难。
对付此,着重剖析一下它的几个特性,寻求新的变革。
1)主题导向(Subject-Oriented)
将数据仓库有别于一样平常 OLTP 系统,数据仓库的资料模型设计,着重将资料按其意义归类至相同的主题区(subject area),因此称为主题导向。举例如 Party、Arrangement、Event、Product 等。
2)集成性(Integrated)
资料来自企业各 OLTP 系统,在数据仓库中是集成过且同等的。
3)韶光差异性(Time-Variant)
资料的变动,在数据仓库中是能够被记录以及追踪变革的,有助于能反响出能随着韶光变革的资料轨迹。
4)不变动性(Nonvolatile)
资料一旦确认写入后是不会被更换或删除的,纵然资料是缺点的亦同。由此可以看出,数据仓库本身是一个不断网络数据,按相应的规则进行组合汇聚的过程,如图 所示。
图:数据仓库聚合数据面板
不雅观察上图可以知道,这个过程所损耗的,也只是仓库本身的性能和 ETL 性能,而仓库本身的性能取决于通信、I/O 能力和硬件性能,ETL 的性能也基于此。因此,在硬件性能如此强劲的本日,如何提高这三项指标,决定了仓库本身性能的利害,那么一个得当的架构去操作,将显得尤为主要,特殊是在数据量不断膨胀的本日,架构将决定企业数据仓库的支撑能力。
2、MPP架构数据仓库
在大数据遍及的本日,各种架构的数据库不断涌现,下图即是当前利用的各种构造的一个比拟图,从易用性到扩展能力的比拟。
图 :大数据技能栈比拟
对付兼顾易用性和扩展能力而言,MPP 架构的数据库霸占着比较大的上风。结合上图的结果,能处理高数据量的 MPP 架构数据库,是现在的最佳选择,那么 MPP 到底是什么呢?
MPP 即大规模并行处理(Massively Parallel Processor),在 MPP 系统中,每个SMP 节点也可以运行自己的操作系统、数据库等。换言之,每个节点内的 CPU 不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一样平常称为数据重分配(Data Redistribution)。
与传统的 SMP 架构明显不同,常日情形下,MPP 系统由于要在不同处理单元之间传送信息,以是它的效率要比 SMP 要差一点,但是这也不是绝对的,由于 MPP 系统不共享资源,因此对它而言,资源比 SMP 要多,当须要处理的事务达到一定规模时,MPP 的效率要比 SMP好。这便是看通信韶光占用打算韶光的比例而定,如果通信韶光比较多,那 MPP 系统不占上风了,相反,如果通信韶光比较少,那 MPP 系统可以充分发挥资源的上风,达到高效率。当前利用的 OTLP 程序中,用户访问一个中央数据库,如果采取 SMP 系统构造,它的效率要比采取 MPP 构造要快得多。而 MPP 系统在决策支持和数据挖掘方面显示了上风,可以这样说,如果操作相互之间没有什么关系,处理单元之间须要进行的通信比较少,那采取MPP 系统就要好,相反就不得当了。
在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和运用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络相互连接,彼此协同打算,作为整体供应数据库做事。非共享数据库集群有完备的可伸缩性、高可用、高性能、精良的性价比、资源共享等上风。
图:大规模并行处理(MPP)架构
MPP 架构数据库采取 Shared-nothing 架构(非共享集群),每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。在拥有高带宽网络的内部环境中,使得每个资源都能拥有最佳的运行环境,以得到高输出性能。
图 :Shared-nothing架构
因此,相较于传统型数据库和其他架构数据库,MPP 架构的数据库有如下上风:
1)大数据剖析需求
传统数据库无法支持大规模集群与 PB 级别数据量,且性能受限、扩展性受限,MPP架构数据支持大规模集群以及PB级别数据,性能根据扩展节点性能呈线性关系
2)软硬件一体机本钱高昂、扩展受限
高性能单机做事器的本钱十分高昂,生产扩容、测试、开拓、容灾都需新购同型号一体机(机柜),并且跨代兼容性问题目前也没有得到很好的办理。MPP架构数据库可根据须要无限扩展。
3)In-memory 技能太贵而且不成熟
内存本钱过高,TB 级别以下,不适宜大数据量;MPP架构成本可控,对付TB级数据支持精良,很适宜大数据量。
4)Hadoop 技能的先天不敷
Hive 等 sql-on-hadoop 性能太慢,SQL 兼容性与支持不敷,数据安全性无法担保。MPP架构数据库支持通用标准SQL,数据可冗余备份,具有高可用,高安全性。
五、主飘泊布式数据库选择--GreenPlum1、 根本架构
Greenplum 是基于 Hadoop 的一款分布式数据库产品,在处理海量数据方面比较传统数据库有着较大的上风。
Greenplum 整体架构如下图:
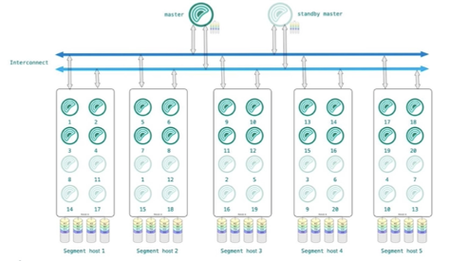
图:GreenPlum整体架构图
数据库由 Master Severs 和 Segment Severs 通过 Interconnect 互联组。
Master 主机卖力:建立与客户真个连接和管理;SQL 的解析并形成实行操持;实行操持向 Segment 的分发网络 Segment 的实行结果;Master 不存储业务数据,只存储数据字典。
Segment 主机卖力:业务数据的存储和存取;用户查询 SQL 的实行。
2、紧张特性
Greenplum 整体有如下技能特点:
1)Shared-nothing 架构
海量数据库采取最易于扩展的 Shared-nothing 架构,每个节点都有自己的操作系统、数据库、硬件资源,节点之间通过网络来通信。
2)基于 gNet Software Interconnect
数据库的内部通信通过基于超级打算的“软件 Switch”内部连接层,基于通用的 gNet(GigE, 10GigE) NICs/switches 在节点间通报和数据,采取高扩展协议,支持扩展到 1000个以上节点。
3)并行加载技能
利用并行数据流引擎,数据加载完备并行,加载数据可达到 4.5T/小时(空想配置)。并且可以直接通过 SQL 语句对外部表进行操作。
4)支持行、列压缩存储技能
海量数据库支持 ZLIB 和 QUICKLZ 办法的压缩,压缩比可到 10:1。压缩数据不一定会带来性能的低落,压缩表通过利用空闲的 CPU 资源,而减少 I/O 资源占用。海量数据库除支持主流的行存储模式外,还支持列存储模式。如果常用的查询只取表中少量字段,则列模式效率更高,如查询须要取表中的大量字段,行模式效率更高。海量数据库的多种压缩存储技能在提高数据存储能力的同时,也可根据不同运用需求提高查询的效率。
3、紧张局限
1)用户不可灵巧掌握事务的提交,用户提交的处理将被自动视作整体事务,整体提交,整体回滚。
2)数据库须要额外的空间清理掩护,给数据库掩护带来额外的事情量。
3)用户不能灵巧分配或掌握做事器资源,做事器自动分配分发。
4)对磁盘I/O有比较高的哀求。
4、 GreenPlum 比拟其他数据库
比较于其他的数据库,GreenPlum 数据库最大的上风在于其开源,极大的降落了其本钱用度,相较于以往动辄四五百万以上的用度,如今只须要不到三分之一的价格即可在企业成功利用,且能够根据自己企业的特性进行改良。
后面会分享更多关于GreenPlum方面的内容,感兴趣的朋友可以关注下~















