
本次直播视频精彩回顾,戳这里!
直播回顾:https://yq.aliyun.com/live/965

PPT分享:https://yq.aliyun.com/download/3529
本文根据演讲视频以及PPT整理而成。
本文将紧张环绕以下四个方面进行分享:
RabbitMQ特性RabbitMQ中的不可靠问题及其办理方案去世信行列步队生产环境下利用RabbitMQ应把稳的事变RabbitMQ特性对付左边的Client Publisher而言,RabbitMQ Server是的吸收者,也便是消费者;对付右边的Client Consumer而言,RabbitMQ Server是的发送者,也便是生产者。RabbitMQ Server将从Client Publisher传送给Client Consumer,扮演着中间商的角色。
RabbitMQ Server卖力将Client Publisher通报来的持久化,延后地将通报给Client Consumer.这样,纵然消费者挂掉,RabbitMQ Server也可以存储,当消费者重新事情时再将存储的通报过去,从而担保不丢失。RabbitMQ Server供应了堆积的能力。
其余,RabbitMQ Server还具有复制和广播的能力。详细来说,RabbitMQ Server可以将Client Publisher发布的分发给多个消费者,比如它能够将特定的按照特定的行列步队分发给特定的消费者。“特定”指不同具有不同的routing key属性,由上图实例,不同的生产者生产了具有不同routing key的,通过exchange路由器将不同的routing key投递到不同行列步队,从而分发给不同消费者。
RabbitMQ中的不可靠问题及其办理方案消费端不可靠问题及其办理方案
实际上,RabbitMQ Server将投递给消费者,具有不可靠的特点。详细来说,RabbitMQ Server将投递给消费者时会调用套接字的write操作,而write操作的过程是不可靠性的。在write操作的过程中,Server须要将发送到套接字的缓存中,通过网卡转发到链路上,终极到达消费者所在的机器内核的套接字缓存中,由消费者利用套接字的read操作将读出来。
纵然套接字的write操作成功也无法担保可靠,潜在的网络故障可能使消费者吸收不到。机器宕机也可能使不可靠,纵然字节流已经到达消费者所在机器,消费者所在机器的宕机也可能使无法被即时读取并处理。其余,纵然消费者即时读取消息,内存行列步队中的所有也可能由于kill-9操作发生丢失。这些可能性都直接导致了不可靠。
因此,须要额外的方法为供应可靠保障。一种可靠性保障办法是,Server投递后并不立即将从Server删除,而是等到消费者吸收、处理并返回Ack包给Server后,Server才删除该。如果消费者没有发送Ack包,那么Server将重新投递该。这个过程确保被消费者处理,担保了可靠。其余,如果消费者已处理并发送Ack包给Server,但由于网络故障等问题导致Ack包丢失时,那么Server同样会重新投递该,导致被重复处理。的重复处理常日由业务层面的技能手段来避免,比如在数据库层面添加主键约束等。另一种重复处理的避免办法是客户端对每条掩护ID, 将被处理的ID记录在列表中,同时检讨新到是否在该列表中。
RabbitMQ中的Auto Ack和Manual Ack对应着不可靠模式和可靠模式. Auto Ack即no ack,指投后即删除,对应不可靠传输。Manual Ack即手动Ack,消费者处理完后利用Ack包关照Server删除,对应可靠传输。
Auto Ack是RabbitMQ中最常用的模式,性能较好,但具有以下问题。当通过套接字write操作投递后,RabbitMQ Server立即删除该,该模式在碰着网络故障时随意马虎发生丢失。其余,如果消费者处理的速率过低,可能导致在消费者recv buffer中大量堆积,从而导致Server端send buffer也堆积大量, Server端无法连续调用套接字write操作。这样,一段韶光之后,Server可能逼迫关闭传输链接,导致不可传输。
只管Auto Ack存在一定风险,目前许多公司仍在运用Auto Ack模式。利用Auto Ack模式时,开拓者须要把稳消费者和生产者的实例数量比例,使生产者产生的速率与消费者消费的速率大致持平。
Manual Ack是RabbitMQ 中更加智能的一种模式。Manual Ack在事情时会考虑消费者的吸收能力,根据消费者的接管能力和当前吸收到的Ack包自动调节分发的速率,担保分发可靠、不壅塞。详细来说,客户端通过PrefetchCount奉告Server自身堆积的能力。
生产端不可靠问题及其办理方案
生产端同样存在的可靠性问题。从Client Publisher将通报给Server和从Server将通报给Client Consumer的过程是完备对等的,Server和Client Consumer间通报的可靠性问题在Client Publisher和Server间同样存在。
Client Publisher首先将写到套接字,再通过网络通报给Server的套接字buffer,终极由Server读取该。这一过程的潜在网络问题也可能使Server端吸收不到。
其余,Server端本身也可能导致不可靠。Server端须要持久化,但出于性能开销的考虑,Server端并不在每次持久化时都刷盘。详细来说,Server端会对文件实行write操作,将脏数据写入操作系统的缓存中,而不是立即将数据写入磁盘。一样平常情形下,Server可能每几百毫秒实行一次fsync操作,通过fsync操作将文件的脏数据写入磁盘。由于Server具有宕机风险,那么每次Server宕机时,还未被fsync操作处理的数据就可能丢失,此过程类似于Redis AOF。
RabbitMQ通过生产者事务和生产者确认两个方法办理Server产生的数据不可靠问题。
生产者事务的基本事理是采取select和commit指令包裹publish,在生产者publish数据之前实行select操作,相称于begin transaction事务开始,在实行多少个publish操作后,再实行commit操作,相称于提交事务。根据tcp包的有序性,commit包成功吸收意味着commit包之前的包也成功吸收。
因此,收到从Client Publisher通报过来的commit包意味着该commit包之前的所有publish包都已成功吸收,即所有都成功吸收。然而,commit包只有等到Server真个fsync操作实行完毕时才返回,因此生产者事务的效率较低,常日只在有批量publish操作时才利用生产者事务模式。也便是说,客户端将累计起来批量发送,以降落fsync操作带来的性能丢失。此外,在进程中累计也存在风险,累计的可能由于进程挂掉而丢失。总的来说,生产者事务由于性能缺陷不被RabbitMQ官方推举。
另一种Server带来的数据不可靠问题的办理方案是生产者确认。生产者确认类似于消费真个Ack机制,生产者可能连续发送多条,Server将这些异步地通过fsync操作写入磁盘再异步地给生产者发送Ack包,奉告生产者的吸收成功。由于Ack包异步传输,不影响生产者真个正常发送。生产者确认模式下,Ack包批量发送,并且都携带有序号,以奉告生产者该序号以前的所有都已正常落盘。
只管RabbitMQ推举用户利用生产者确认模式,目前的RabbitMQ版本还未实现的重发机制,只实现了Ack包的批量发送,以关照Client Publisher哪些吸收成功。当丢失时,Client Publisher端已publish的在进程挂掉时也可能丢失,而不是重新发送,因此生产者确认的浸染也不明显。当然,生产者确认起到了降落发布速率的浸染,减小了丢失的数量。
生产者确认中的重发可以通过以下几种方法实现。第一种办法在内存中累积还未收到Ack包的,收到Ack包后删除该,对付一段韶光内还勾留在内存中的,重发该。这种办法将未Ack存入内存,一旦生产者宕机,这些也会丢失。另一种办法将未收到Ack包存入磁盘,当收到Ack包后删除该,然而,磁盘存储依赖于fsync操作,降落了系统处理的性能。
同时,这还会提高编程的繁芜度,由于这哀求发布时掩护文件行列步队,还哀求一个异步线程将文件行列步队中的发布到Server,带来了多线程和锁问题。还有一种办法将未Ack存入Redis,但当涌现网络故障时,Redis也是不可靠的。目前供应的生产者确认中的重发方案都还存在问题,详细的方案选择依赖于实际场景和个人取舍。
去世信行列步队生产者确认中的重发可以通过以下几种方法实现。第一种办法在内存中累积还未收到Ack包的,收到Ack包后删除该,对付一段韶光内还勾留在内存中的,重发该。这种办法将未Ack存入内存,一旦生产者宕机,这些也会丢失。另一种办法将未收到Ack包存入磁盘,当收到Ack包后删除该,然而,磁盘存储依赖于fsync操作,降落了系统处理的性能。
同时,这还会提高编程的繁芜度,由于这哀求发布时掩护文件行列步队,还哀求一个异步线程将文件行列步队中的发布到Server,带来了多线程和锁问题。还有一种办法将未Ack存入Redis,但当涌现网络故障时,Redis也是不可靠的。目前供应的生产者确认中的重发方案都还存在问题,详细的方案选择依赖于实际场景和个人取舍。
三、去世信行列步队
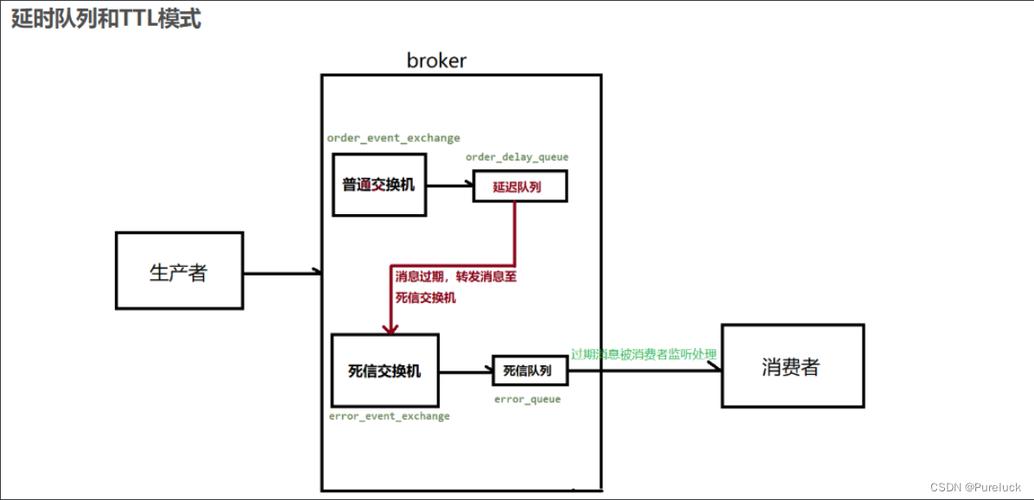
去世信行列步队利用了RabbitMQ中的一种分外行列步队属性,即x-message-ttl属性,表示行列步队中的构建韶光。如果用户在声明行列步队时定义行列步队的x-message-ttl属性,此后所有进入该行列步队的都将持有构建韶光,到达构建韶光的将被删除。如果还为行列步队配置了回收站属性,那么纵然构建韶光到达,RabbitMQ也不会立即删除这些,而是将这些过期丢入回收站,即去世信行列步队。
去世信行列步队的事情办法如上图。Client Publisher将投递给路由器,也便是exchange,再由exchange将投递给行列步队,由行列步队天生该的构建韶光,到达构建韶光的将过期,同时进入去世信行列步队。过期进入去世信行列步队的办法和进入普通行列步队的办法基本同等,即先投递给exchange路由器,再由exchange投递。消费者消费去世信行列步队,得到的是延后的,延迟的韶光长度即构建韶光。目前,去世信行列步队存在的问题是,一个行列步队只能设置一个构建韶光,的过期韶光不足灵巧,不能知足一些分外场景的需求,比如动态的重试韶光。
去世信行列步队的另一个利用场景是Retry Later,即在一段韶光后才重新处理此前处理失落败的,这时可能用到双重去世信。详细来说,去世信行列步队不仅可以吸收过期,还可以吸收被reject的,即消费端谢绝处理或处理过程发生非常的,Reject操作具有requeue参数,当requeue设为true时被reject会重新进入行列步队并被重新投递,当requeue设为false时被reject将进入去世信行列步队。如果去世信行列步队持有构建韶光,那么到达构建的将重新投递给原有行列步队,实现Retry Later。双重去世信在利用过程中需把稳处理的去世循环问题,由于可能无限循环地进入去世信行列步队。
生产环境下利用RabbitMQ应把稳的事变生产环境下,RabbitMQ通过利用集群模式。集群模式下,只有元信息分布在所有节点中。元信息指行列步队信息,路由器信息等,行列步队中的信息只存储在一个节点中,因此,单个节点宕机会导致所有节点都不可用。其余,RabbitMQ的所有节点间存在转发机制,即许可节点转发其他目标节点的处理要求,这样客户端只需连接到任意一个节点就可以实现其转发需求。
行列步队的高可用依赖于RabbitMQ的镜像行列步队,即在其他节点上备份某节点的内容。这样,本地点主节点宕机时,其他镜像节点可以替代主节点完成通报任务。
常日情形下,镜像节点是默默无闻的,客户端无需感知镜像节点的存在。只有当主节点宕机时,镜像节点才发挥浸染。镜像行列步队的配置如下:
Ha-mode具有三个选项,all指将所有行列步队的信息存入所有节点,这种模式最安全,但也最摧残浪费蹂躏存储空间;exactly指由用户精确指定每个行列步队的复制数,当ha-mode设置为exactly,ha-params设置为2时表示“一主一从”,这种模式是官方推举的;nodes指由用户指定副当地点的节点,这种模式极少被利用。x-queue-master-locator用于设置存储行列步队主节点的RabbitMQ节点。min-master指将行列步队主节点设置在行列步队数量最少的RabbitMQ节点,client-local指将行列步队主节点设置在当前客户端所在的RabbitMQ节点,random即随机选择节点。Ha-sync-mode用于镜像节点代替宕机主节点并创建新节点以填补缺失落节点时,设置新节点上数据的同步策略。automatic指自动地将新主节点上数据全部同步给新节点,manual指不同步新主节点上的老数据,只同步新产生的数据。由于节点间数据同步须要耗费韶光,永劫光的数据同步可能会影响做事的稳定性,但常日情形下RabbitMQ的节点堆积的数据量并不大,因此RabbitMQ官方推举利用Automatic进行数据同步。Ha-sync-batch-size指节点间批量同步的数据量。Ha-promote-on-shutdown表示主动停滞主节点的做事时,其他节点如何替代主节点。Always指其他节点总是能顺利地替代主节点,when-synced哀求与原主节点数据完备同等的节点才能替代主节点。Ha-promote-on-failure表示非常情形下其他节点如何替代主节点,always和when-synced的含义与Ha-promote-on-shutdown中同等。许多公司为RabbitMQ集群设置了内存模式,认为内存模式无需落盘,能够提升系统性能。但实际上,RabbitMQ官方文档指出,内存模式无法提升系统性能,它只提升了产生元信息数据的速率,即Ram Node指将元信息存入内存,可以提升元信息的创建速率,而不是数据的性能。这是利用RabbitMQ时的一个常见误区。
作者:PHP小好手















