
SELECT NVL(MAX(T1.CREATED),SYSDATE) FROM DUAL LEFT JOIN TEST11 T1ON T1.OWNER=’OUTLN’ AND OBJECT_TYPE IS NOT NULL;
SQL是TEST11表和DUAL表干系联,WHERE条件中OWNER字段有索引,SQL走了该字段索引范围扫描的实行操持,单次实行逻辑读2117。SQL实行频率非常高,一分钟数万次。实行操持如下:
2. 初步优化

WHERE条件有两个【OWNER=’OUTLN’】和【OBJECT_TYPE IS NOT NULL】,查询取出来的字段是CREATED,考虑创建OWNER+OBJECT_TYPE+CREATED三列联合索引,可以肃清回表的本钱,创建索引后逻辑读由2117降为82。实行操持如下:
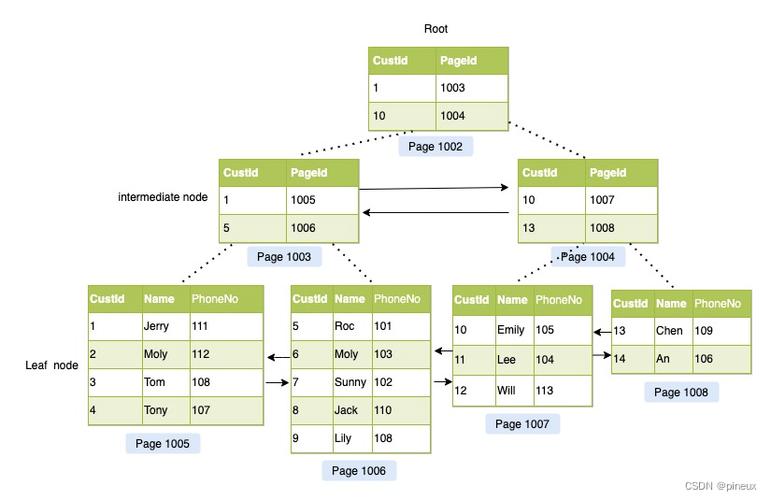
3. 极致优化探究 – 索引事理
连续剖析该SQL, 创造实在从逻辑上来说,SQL仅须要韶光列CREATED的最小值,至于其他值是什么并不主要。那么是否有一种方法可以只取出最小值,而忽略掉其他数据呢?如果可以做到那么逻辑读就会进一步降落。
考虑一下索引的构造:索引由根节点块(root block)、枝块(branch block)和叶子块(leaf block)组成,索引的数据在叶子块里是顺序排列的。也便是说最小值的数据会保存在索引块的最小那一端。理论上来说,完备可以从叶子块的个中一段取一个块,就可以得到特定索引的最小值。
4. 简化版取min/max索引优化
为了更好理解,我们把问题简化成取表里CREATED最小值(或者最大值)。
须要取得TEST11表CREATED的最大/最小值:
SELECT MAX(CREATED) FROM TEST11;
假设存在CREATED字段的索引,那么完备可以只取叶子块的最靠边的一个块,就能得到所须要的的值。
下面做一个测试,创建一个测试表:
create table test11 tablespace DATA_TS as select from dba_objects where rownum <1000;begin for i in 0..10 loopinsert /+append /into test11 select from test11;commit;end loop;end;/
创建一个CREATED的索引,然后运行之前简化的SQL。根据索引事理可以判断该当须要3-4个逻辑读:分别是Root节点开始–>找最右边的Branch(可能是0-2个,根据索引的层级)–>再找到最右边的Leaf Block。
实行如下,结果和我们之前设想的一样,实行操持走的是INDEX FULL SCAN(MIN/MAX)。
设想轻微繁芜一点场景:假设须要得到的是符合指定的条件的最大CREATED值呢?
如果我们须要取的是符合OWNER = 'OUTLN’的最大CREATED值。SQL如下:
SELECT MAX(CREATED) FROM TEST11 WHERE OWNER = 'OUTLN';
如果存在(OWNER,CREATED)组合索引,数据库就可以利用类似的方法只取个中一个叶子节点。实行操持走的是INDEX RANGE SCAN(MIN/MAX),逻辑读是3:
那么如果是SELECT MAX(CREATED) FROM TEST11 WHERE OWNER= ‘OUTLN’ AND OBJECT_TYPE =‘TABLE’ ,就须要新的索引(OWNER,OBJECT_TYPE,CREATED)来完成同样的动作。实行操持走的是INDEX RANGE SCAN(MIN/MAX),须要3个逻辑读:
也便是说,必须条件中的列和索引前导列完备匹配,然后取的索引里末了一列的MAX/MIN值,它就可以走最优的INDEX RANGE SCAN (MIN/MAX)索引。
5. 转化IS NOT NULL条件到索引中回到原始的SQL:
SELECT NVL(MAX(T1.CREATED),SYSDATE) FROM DUAL LEFT JOIN TEST11 T1ON T1.OWNER=’OUTLN’AND OBJECT_TYPE IS NOT NULL;
原始SQL中除了OWNER=’OUTLN’,还有一个OBJECT_TYPE IS NOT NULL,直接创建 (OWNER,OBJECT_TYPE,CREATED)联合索引花费逻辑读82,并不能达到最优的效果,由于OBJECT_TYPE IS NOT NULL不能对应到索引的一个特定值,实行操持如下:
我们须要把OBJECT_TYPE IS NOT NULL的条件固化成一个特定的值,这样就可以匹配索引中的特定值了。SQL须要改写一下:
1) 去掉DUAL, 并不会影响结果集:SELECT NVL(MAX(T1.CREATED),SYSDATE) FROM TEST11 T1WHERE T1.OWNER=’OUTLN’AND OBJECT_TYPE IS NOT NULL;2) 把OBJECT_TYPE IS NOT NULL变成一个特定值,这里用了CASE WHEN,SQL变成:
SELECT MAX(CREATED) FROM TEST11WHERE OWNER ='OUTLN'AND CASE WHEN OBJECT_TYPE IS NOT NULL THEN 1 END = 1;3) 创建一个函数索引。也便是说OBJECT_TYPE IS NOT NULL的记录在索引中存储为1。如下:
CREATE INDEX IDX_TEST11_MAX ON TEST11(OWNER,CASE WHEN OBJECT_TYPE IS NOT NULL THEN 1 END,CREATED) PARALLEL 4 NOLOGGING;ALTER INDEX IDX_TEST11_MAX NOPARALLEL;
此时实行操持如下,逻辑读降为3:
6. 优化结果
为生产SQL创建CASE WHEN索引并改写SQL后逻辑读降为75,并没有走上最优的INDEX RANGE SCAN (MIN/MAX)实行操持,这是由于这种写法MAX(T1.CREATED)被放在最外层,也便是说对MAX的取值是基于关联后的结果集而不是基于TEST11表。
SQL是TEST11和DUAL做关联,取NVL (MAX (T1.CREATED), SYSDATE) 的值,纵然没有数据也会返回SYSDATE的值,去掉DUAL表不影响,去掉DUAL表后SQL逻辑读降为3:
终极完成了一个高频SQL从2117到3的极致优化,提升达数百倍。
IS NULL的优化
系统中还创造另一个SQL, 脱敏后SQL如下:
UPDATE TEST TSET T.TCODE = (SELECT T1.TCODE FROM TEST1 T1 WHERE T.SCODE = T1.SCODE)WHERE T.TCODE IS NULLAND EXISTS (SELECT 1 FROM TEST1 T2 WHERE T.SCODE = T2.SCODE)
SQL走的是全表扫描的实行操持,TEST表数据量1100万,每次更新数据0条。实行操持最慢的步骤是ID=3的TEST表全表扫描步骤。WHERE条件中TCODE IS NULL可以过滤掉所有数据,但是我们知道NULL值是不存在索引中的,一样平常情形下IS NULL只能走全表,如果全表数据非常多SQL性能就会很差。和IS NOT NULL同样的思路,能不能让这部分过滤性非常好的NULL值存在索引中呢?
SElECT FROM TEST WHERE TCODE IS NULL;no rows selected
也便是换个思路,用个函数把NULL值转为一个表中该字段不存在的固定值(假设0),非NULL值的转为NULL。这样索引中存储的便是原来的NULL值,也便是经由函数转换后的0,这样可以担保索引最小化,由于原来IS NOT NULL的数据不存在个中。
转换如下:CODE IS NULL <==> CASE WHEN TCODE IS NULL THEN 0 END
利用CASE WHEN而不该用NVL(TCODE,0)函数是为了将索引最小化,由于原有的TCODE存在的值不用保存到索引中,同时也不用考虑NVL之后可能和原有的值相同的情形。
创建函数索引并修正原SQL,逻辑读由原来的80多万降为1:
CREATE INDEX IDX_YHEMTEST ON TEST(CASE WHEN TCODE IS NULL THEN 0 END);UPDATE TEST T SET T.TCODE = (SELECT T1.TCODE FROM TEST1 T1 WHERE T.SCODE = T1.SCODE) WHERE CASE WHEN T.TCODE IS NULL THEN 0 END = 0 AND EXISTS (SELECT 1 FROM TEST1 T2 WHERE T.SCODE = T2.SCODE)
经优化,该SQL性能提升数万倍。
关于作者
刘娣,云和恩墨技能顾问,多年数据库做事履历,紧张做事于移动经营商和券商,具有丰富的数据库性能优化、故障处理履历,善于SQL审核和性能优化。
墨天轮原文链接:https://www.modb.pro/db/47100















