
此架构紧张是将Logstash支配在各个节点上搜集干系日志、数据,并经由剖析、过滤后发送给远端做事器上的Elasticsearch进行存储。Elasticsearch再将数据以分片的形式压缩存储,并供应多种API供用户查询、操作。用户可以通过Kibana Web直不雅观的对日志进行查询,并根据需求天生数据报表。
此架构的优点是搭建大略,易于上手。缺陷是Logstash花费系统资源比较大,运行时占用CPU和内存资源较高。其余,由于没有行列步队缓存,可能存在数据丢失的风险,适宜于数据量小的环境利用。

2.引入Kafka的范例ELK架构
为担保日志传输数据的可靠性和稳定性,引入Kafka作为缓冲行列步队,位于各个节点上的Logstash Agent(一级Logstash,紧张用来传输数据)先将数据通报给行列步队,接着,Logstash server(二级Logstash,紧张用来拉取消息行列步队数据,过滤并剖析数据)将格式化的数据通报给Elasticsearch进行存储。末了,由Kibana将日志和数据呈现给用户。由于引入了Kafka缓冲机制,纵然远端Logstash server因故障停滞运行,数据也不会丢失,可靠性得到了大大的提升。
该架构优点在于引入了行列步队机制,提升日志数据的可靠性,但依然存在Logstash占用系统资源过多的问题,在海量数据运用处景下,可能会涌现性能瓶颈。
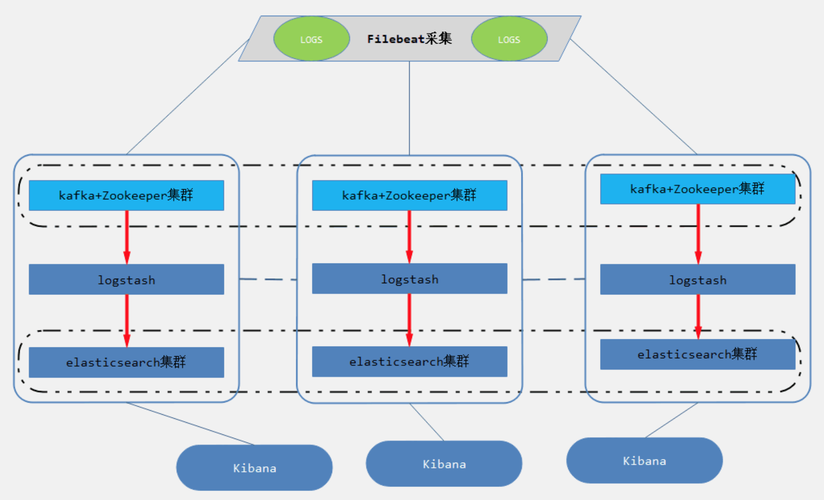
3.FileBeats+Kafka+ELK集群架构
该架构从上面架构根本上改进而来的,紧张是将前端网络数据的Logstash Agent换成了filebeat,行列步队利用了kafka集群,然后将Logstash和Elasticsearch都通过集群模式进行构建,完全架构如图所示:
日志采集器Logstash其功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会花费过多的系统资源,这将严重影响业务系统的性能,而filebeat便是一个完美的替代者,它基于Go措辞没有任何依赖,配置文件大略,格式明了,同时filebeat比logstash更加轻量级,以是占用系统资源极少,非常适宜安装在生产机器上。这便是推举利用filebeat,也是 ELK Stack 在 Agent 的第一选择。
此架构适宜大型集群、海量数据的业务场景,它通过将前端Logstash Agent更换成filebeat,有效降落了网络日志对业务系统资源的花费。同时,行列步队利用kafka集群架构,有效保障了网络数据的安全性和稳定性,而后端Logstash和Elasticsearch均采取集群模式搭建,从整体长进步了ELK系统的高效性、扩展性和吞吐量。我所在的项目组采取的便是这套架构,由于生产所需的配置较高,且涉及较多持久化操作,采取的都是性能高配的云主机搭建办法而非时下流行的容器搭建。
source: ELK运用架构先容二、FileBeat做事搭建日志采集器选择了Filebeat而不是Logstash,是由于 Logstash 是跑在 JVM 上面,资源花费比较大,后来作者用 GO 写了一个功能较少但是资源花费也小的轻量级的 Agent 叫 Logstash-forwarder,后来改名为FileBeat。关于ELK中Filebeat的事理先容和详细配置我其余写了一篇文章,戳它:《FileBeat事理与实践指南》。
1.filebeat.yml配置
最核心的部分在于FileBeat配置文件的配置,须要指定paths(日志文件路径),fileds(日志主题),hosts(kafka主机ip和端口),topic(kafka主题),version(kafka的版本),drop_fields(舍弃不必要的字段),name(本机IP)
filebeat.inputs:
- type: log
enabled: true
paths:
- /wls/applogs/rtlog/app.log
fields:
log_topic: appName
multiline:
# pattern for error log, if start with space or cause by
pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
negate: false
match: after
output.kafka:
enabled: true
hosts: [\公众kafka-1:9092\"大众,\"大众kafka-2:9092\"大众]
topic: applog
version: \"大众0.10.2.0\"大众
compression: gzip
processors:
- drop_fields:
fields: [\"大众beat\公众, \"大众input\"大众, \"大众source\"大众, \"大众offset\公众]
logging.level: error
name: app-server-ip
2.常用运维指令
终端启动(退出终端或ctrl+c会退出运行)./filebeat -e -c filebeat.yml
往后台守护进程启动启动filebeatsnohup ./filebeat -e -c filebeat.yml &
确认配置不再修正,可用如下命令//可以防止日志爆盘,将所有标准输出及标准缺点输出到/dev/null空设备,即没有任何输出信息。
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &
停滞运行FileBeat进程ps -ef | grep filebeat
Kill -9 线程号
3.FileBeat调试
当FileBeat在做事主机采集运用日志并向Kafka输出日志时可以通过两个步骤验证Filebeat的采集运送是否正常:
采集验证:终端实行命令,查看掌握台输出,如果做事有非常会直接打印出来并自动停滞做事。./filebeat -e -c filebeat.yml
吸收验证:Kafka集群掌握台直接消费,验证吸收到的日志信息。./kafka-console-consumer.sh --zookeeper zk-1:2181,zk-2:2181 --topic app.log
ElasticSearch或者Kibana验证。如果已经搭建了ELK平台,可根据上传的日志关键属性,于KB或者ES平台查看是否有日志流输入或者在search框中根据host.name/log_topic关键属性来查看是否有落库。source: FileBeat事理与实践指南三、Kafka集群搭建一个范例的Kafka集群包含多少Producer,多少broker、多少Consumer Group,以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变革时进行rebalance。Producer利用push模式将发布到broker,Consumer利用pull模式从broker订阅并消费。关于Kafka的事理和利用可以参考《Kafka学习条记》,下面就供应了一个范例的Kafka+ZooKeeper集群:
1.Kafka配置
生产环境中 Kafka 集群中节点数量建议为(2N + 1 )个,Zookeeper集群同样建议为(2N+1)个,这边就都以 3 个节点举例,修正kafka集群的配置文件,以broker1为例进行配置:
$ vim ./config/server.properties
broker.id=1
port=9092
host.name=192.168.0.1
num.replica.fetchers=1
log.dirs=/opt/kafka_logs
num.partitions=3
zookeeper.connect=zk-1:2181,zk-2:2181,zk-3:2181
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
num.io.threads=8
num.network.threads=8
queued.max.requests=16
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
delete.topic.enable=true
这里比较主要的一个参数配置便是:num.partitions
Kafka中的topic因此partition的形式存放的,每一个topic都可以设置它的partition数量,Partition的数量决定了组成topic的log的数量。推举partition的数量一定要大于同时运行的consumer的数量。其余,建议partition的数量大于集群broker的数量,这样数据就可以均匀的分布在各个broker中。
-delete.topic.enable:在0.8.2版本之后,Kafka供应了删除topic的功能,但是默认并不会直接将topic数据物理删除。如果要从物理上删除(即删除topic后,数据文件也会一同删除),就须要设置此配置项为true。
2.Kafka运维命令
这里涉及到topic主题的创建、与filebeats调试的状态,须要节制几个有用的运维指令:
查看topic状态./kafka-topics.sh --describe --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --topic app.log查看所有topic列表:sh kafka-topics.sh --zookeeper --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --list创建topicsh kafka-topics.sh --zookeeper --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --create --topic app.log --partitions 5 --replication-factor 2把稳:server.properties 设置 delete.topic.enable=true删除主题数据./bin/kafka-topics.sh --delete --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --topic app.log生产topic的./kafka-console-producer.sh --broker-list kafka-1:9092 kafka-2:9092 --topic app.log消费topic的./kafka-console-consumer.sh --zookeeper zk-1:2181,zk-2:2181,zk-3:2181 --topic app.log3.Kafka做事监控
通过以下命令启动了Kafka集群做事往后,考试测验创建主题、打印主题列表查看做事状态。
$ ./bin/kafka-server-start.sh -daemon ./config/server.properties
同时也可以登录Kafka集群中任意两台broker主机,分别用统一的主题进行的生产与消费,如果做事正常则两端可以互通:
四、LogStash
Logstash是一个开源的、做事真个数据处理pipeline(管道),它可以吸收多个源的数据、然后对它们进行转换、终极将它们发送到指定类型的目的地。Logstash是通过插件机制实现各种功能的,可以在https://github.com/logstash-plugins 下载各种功能的插件,也可以自行编写插件。
Logstash的数据处理过程紧张包括:Inputs, Filters, Outputs 三部分, 其余在Inputs和Outputs中可以利用Codecs对数据格式进行处理。这四个部分均以插件形式存在,在logstash.conf配置文件中设置须要利用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能
Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等[详细参考]Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等[详细参考]Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等[详细参考]Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline本实例中input从kafka中获取日志数据,filter紧张采取grok、date插件,outputs则直接输出到elastic集群中。logstash的配置文件是可以自定义的,在启动运用时须要制订相应的配置文件。
$ vim logstash.conf
input {
kafka {
type => \"大众kafka\公众
bootstrap_servers => \"大众kafka-1:9092,kafka-2:9092,kafka-3:9092\"大众
topics => \"大众app.log\"大众
consumer_threads => 2
codec => \"大众json\"大众
}
}
filter {
grok {
match => [
#涉及多个正则匹配的写法
\"大众message\"大众,\公众%{HTTPDATE:timestamp}\公众,
\公众message\"大众,\公众%{COMBINEDAPACHELOG}\公众
]
}
date {
match => [\公众timestamp\"大众, \"大众dd/MMM/yyyy:HH:mm:ss Z\"大众]
}
}
output {
elasticsearch {
host => [\公众es-1:9300\"大众,\"大众es-2:9300\公众,\公众es-3:9300\"大众]
index => \"大众applogs-%{+YYYY.MM.dd}\公众
}
}
对上述参数进行解释:
input,须要指明是kafka来源,broker的ip和端口,主题,codec模式为json(由于经由filebeat采集而来的数据都json化了)
filter,grok是一个十分强大的logstash filter插件,通过正则解析任意文本,将非构造化日志数据弄成构造化和方便查询的构造。
output,指定了输出到ES集群,host这里写ES集群的客户端节点即可,index则是对应ES里的检索,一样平常以【topic+日期】即可。
但是往往来来往杂的日志系统这些还是不足,须要加一些分外处理如:非常堆栈须要合并行、掌握台调试等。
搜集日志时涉及非常堆栈的合并行处理时,可以加上;如果Filebeat已作合并处理此处则不须要了:input {
stdin {
codec => multiline {
pattern => \"大众^\[\"大众
negate => true
what => \"大众previous\"大众
}
}
}
掌握台调试过滤器。很多时候我们须要调试自己的正则表达式是否可用,官方的在线调试并不好用,那么可以通过自己天生的json数据来校验正则的效果,count指定重复天生的次数,message则是待调试的内容:input {
generator {
count => 1
message => '{\公众key1\"大众:\公众value1\公众,\"大众key2\公众:[1,2],\公众key3\"大众:{\"大众subkey1\公众:\"大众subvalue1\公众}}'
codec => json
}
}
rubydebug指明了输出内容到掌握台:
output {
stdout {
codec => rubydebug
}
}
filter插件由用户自定义填写,启动测试并检讨接口,每次调试都要启动一次做事可能会须要等待几秒钟才输出内容到掌握台。
./logstash -f /wls/logstash/config/logstash-test.conf
关于LogStash的语法详解和实践指南可以参考:《Logstash 最佳实践》
五、Elastic集群搭建在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,搜索查询的要求一样平常是经由Client Node来向Data Node获取数据,而索引查询首先要求Master Node节点,然后Master Node将要求分配到多个Data Node节点完成一次索引查询。
Master Node:紧张用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态。由于数据的存储和查询都不会走主节点,以是主节点的压力相对较小,因此主节点的内存分配也可以相对少些,但是主节点却是最主要的,由于一旦主节点宕机,全体elasticsearch集群将不可用。以是一定要担保主节点的稳定性。
Data Node:数据节点,这些节点上保存了数据分片。它卖力数据干系操作,比如分片的CRUD、搜索和整合等操作。数据节点上面实行的操作都比较花费CPU、内存和I/O资源,数据节点做事器要选择较好的硬件配置。
Client Node:客户端节点。client node存在的好处是可以分担data node的一部分压力,由于elasticsearch的查询是两层汇聚的结果,第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node吸收到data node发来的结果后再做第二次的汇聚,然后把终极的查询结果返回给用户。这样,client node就替data node分担了部分压力。
1.集群配置
第一步即定义修正es集群的配置文件:
$ vim config/elasticsearch.yml
cluster.name: es
node.name: es-node1
node.master: true
node.data: true
network.host: 192.168.0.1
discovery.zen.ping.unicast.hosts: [\公众192.168.0.2\公众,\"大众192.168.0.3\公众]
discovery.zen.minimum_master_nodes: 2
集群主要配置项
node.name 可以配置每个节点的名称node.master 可以配置该节点是否有资格成为主节点。如果配置为 true,则主机有资格成为主节点,配置为 false 则主机就不会成为主节点,可以去当数据节点或负载均衡节点node.data 可以配置该节点是否为数据节点,如果配置为 true,则主机就会作为数据节点,把稳主节点也可以作为数据节点discovery.zen.ping.unicast.hosts 可以配置集群的主机地址,配置之后集群的主机之间可以自动创造,须要剔除自己。discovery.zen.minimum_master_nodes: 为了防止集群发生“脑裂”,常日须要配置集群最少主节点数目,常日为 (主节点数目 / 2) + 12.做事启停
通过 -d 来后台启动
$ ./bin/elasticsearch -d
打开网页 http://192.168.0.1:9200/, 如果涌现下面信息解释配置成功
{
name: \"大众es-node1\"大众,
cluster_name: \"大众es\"大众,
cluster_uuid: \"大众XvoyA_NYTSSV8pJg0Xb23A\"大众,
version: {
number: \"大众6.2.4\公众,
build_hash: \"大众ccec39f\"大众,
build_date: \"大众2018-04-12T20:37:28.497551Z\公众,
build_snapshot: false,
lucene_version: \"大众7.2.1\"大众,
minimum_wire_compatibility_version: \"大众5.6.0\公众,
minimum_index_compatibility_version: \"大众5.0.0\"大众
},
tagline: \"大众You Know, for Search\"大众
}
集群做事康健状况检讨,可以再任意节点通过实行如下命令,如果能创造列表展示的主节点、客户端和数据节点都是逐一对应的,那么解释集群做事都已经正常启动了。
curl \"大众http://ip:port/_cat/nodes\"大众
关于ES的详细事理与实践,推举《Elasticsearch 威信指南》
六、KibanaKibana是一个开源的剖析和可视化平台,设计用于和Elasticsearch一起事情,可以通过Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互。kibana利用JavaScript措辞编写,安装支配十分大略,可以从elastic官网下载所需的版本,这里须要把稳的是Kibana与Elasticsearch的版本必须同等,其余,在安装Kibana时,要确保Elasticsearch、Logstash和kafka已经安装完毕。
1.Kibana的配置
将下载的gz包解压
$ tar -zxvf kibana-6.2.4-darwin-x86_64.tar.gz
$ mv kibana-6.2.4-darwin-x86_64.tar.gz kibana
找到配置文件kibana.yml并修正
$ vim config/kibana.yml
server.port: 5601
server.host: \"大众192.168.0.1\"大众
elasticsearch.url: \"大众http://192.168.0.1:9200\公众
涉及到三个关键参数配置:
server.port: kibana绑定的监听端口,默认是5601
server.host: kibana绑定的IP地址
elasticsearch.url: 如果是ES集群,则推举绑定集群中任意一台ClientNode即可。
本人在项目过程中是通过Nginx配置域名来访问Kibana的,虽然配置了映射,且在Nginx主机上curl能访问到做事,但是域名访问始终报404非常,后来通过添加两项配置即可访问:
server.basePath: \公众/kibana\公众
server.rewriteBasePath: true
2.Kibana运维命令
启动做事:
$ nohup ./bin/kibana &
停滞做事
ps -ef | grep node
kill -9 线程号
做事启动往后可以通过访问:http://192.168.0.1:5601/
3.查询数据
打开discover菜单,这也是kibanan最常用的功能,选择好韶光维度来过滤数据范围:
Kibana语法查询,可以直接在搜索框内输入过滤条件进行查询:
response:200,将匹配response字段的值是200的文档message:\"大众Quick brown fox\"大众,将在message字段中搜索\公众quick brown fox\公众这个短语。如果没有引号,将会匹配到包含这些词的所有文档,而不管它们的顺序如何。response:200 and extension:php or extension:css 将匹配response是200并且extension是php,或者匹配extension是css而response任意,括号可以改变这种优先级>, >=, <, <= 都是有效的操作符response: 将匹配所有存在response字段的文档点开数据行即可查看详细数据,支持table视图和Json文本两种办法,日志数据都存储在message属性中,而前面定义的name可以查看详细的主句,log_topic则指明是来源哪个运用:
source: Kibana(一张图片赛过千万行日志)总结综上,通过上面支配命令来实现 ELK 的整套组件,包含了日志网络、过滤、索引和可视化的全部流程,基于这套系统实现剖析日志功能。同时,通过水平扩展 Kafka、Elasticsearch 集群,可以实现日均亿级的日志实时存储与处理,但是从细节方面来看,这套系统还存着许多可以连续优化和改进的点:
日志格式需优化,每个别系网络的日志格式须要约定一个标准,比如各个业务系统在定义log4j或logback日志partern时可以按照【韶光】【级别】【全局Traceid】【线程号】【方法名】【日志信息】统一输出。Logstash的正则优化,一旦约定了日志模式,编写Logstash的自定义grok正则就能过滤出关键属性存放于ES,那么基于韶光、traceId以及方法名的查询则不在堆积于message,大大优化查询效率。TraceId埋点优化,分布式与微做事架构中,一个Restful要求的发起可能会经由多达十几个别系的处理流程,任何一个环节都有error可能,须要有一个全局ID进行全链路追踪,这里须要结合Java探针把tiraceId埋入日志模板里,现有PinPoint、SkyWalking与ZipKin都能为全局ID供应成熟的办理方案。ES存储优化,按照线上机器的业务量来看,每天TB级的日志数据都写入ES会造成较大的存储压力,韶光越久的日志利用代价则越低,可以按照7天有效期来自动清理ES索引优化存储空间,参考【ES清理脚本】。运维优化,一个繁芜日志平台在运维方面有着巨大的本钱,这里涉及到了Kafka、ZooKeeper、ELK等多个集议论况的掩护,除了供应统一的集群操作指令以外,也须要形成对整套日志平台环境的监控视图。性能优化,多组件、稠浊措辞、分布式环境与集群林立的繁芜系统,性能问题旧调重弹,实践出真知,碰着了再补充!














