
责编 | Carol
来源 | CSDN 博客

封图 | CSDN付费下载于视觉中国
Hadoop先容
Hadoop 是 Lucene 创始人 Doug Cutting,根据 Google 的干系内容山寨出来的分布式文件系统和对海量数据进行剖析打算的根本框架系统,个中包含 MapReduce 程序,hdfs 系统等!
[它受到最先由 Google Lab 开拓的 Map/Reduce 和 Google File System(GFS) 的启示。]
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来支配在低廉的(low-cost)硬件上;而且它供应高吞吐量(high throughput)来访问运用程序的数据,适宜那些有着超大数据集(large data set)的运用程序。HDFS放宽了(relax)POSIX的哀求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计:HDFS 和mapreduce
HDFS:为海量数据供应存储
MapReduce: 为海量数据供应了打算cluster:集群
LB:负载均衡
LVS SLB HAPROXY,nginx
HA:高可用
MHA,keepalived,hearebeat
HPC、Hadoop:大批量的打算赞助存储和运算
什么是分布式:分散的
Hadoop的集群优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop 以一种可靠、高效、可伸缩的办法进行数据处理。
Hadoop 是可靠的,由于它假设打算元素和存储会失落败,因此它掩护多个事情数据副本,确保能够针对失落败的节点重新分布处理。
Hadoop 是高效的,由于它以并行的办法事情,通过并行处理加快处理速率
Hadoop 还是可伸缩的,能够处理 PB 级数据。
PB级别的数据换算成G?
IPB=1024TB
1TB=1024G
Hadoop 依赖于社区做事,因此它的本钱比较低,任何人都可以利用。
Hadoop是一个能够让用户轻松架构和利用的分布式打算平台。用户可以轻松地在Hadoop上开拓和运行处理海量数据的运用程序。它紧张有以下几个优点:
高可靠性:hadoop 按位存储和处理数据的能力值得人们相信
高扩展性:节点比较多,方便打算和分配数据。
什么是节点?
节点是一个术语,代指一类设备.他们可以是主机(pc),做事器,也可以是构成传输网络的交流机,路由器,防火墙等等.
高效性:Hadoop能够在节点之间动态地移动数据,并担保各个节点的动态平衡,因此处理速率非常快。
容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失落败的任务重新分配。
raid 容错性是什么意思,raid几没有容错性?raid 几有容错性。
低本钱:与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市比较,hadoop是开源的,项目的软件本钱因此会大大降落
把稳:hadoop框架开拓措辞:java,在linux上运行效果比较空想。
官网:http://hadoop.apache.org/
关于hadoop的干系观点
1、分布式存储:
linux存储有哪些?
答:NFS, NAS, HDFS,MFS
命名空间
namespace:在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件,为了组织浩瀚的文件,把文件可以放到不同的文件夹中,文件夹可以一级一级的包含。我们把这种组织形式称为命名空间(namespace)。命名空间管理着全体做事器集群中的所有文件。命名空间的职责与存储真实数据的职责是不一样的。卖力命名空间职责的节点称为主节点(master node),卖力存储真实数据职责的节点称为从节点(slave node)。
主从节点:
主节点卖力管理文件系统的文件构造,从节点卖力存储真实的数据,合称为主从式构造(master-slaves)。
用户操作的时候,也该当是先和主节点打交道, 查询数据在那些从节点上, 然后再从从节点读取数据。有的时候为了加快用户的访问速率,会把全体命名空间信息都放在内存当中、当存储文件越多时,我们主节点就须要越多的内存空间。
打开一个文件是先加载到哪里?
答:内存
我们为什么用条记本打不开一个2T大小的文件?
答:内存太小
2、Block
在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不随意马虎管理,那么可以抽象出一个独立的存储文件单位,称为块(block)。
问题:如果我的硬盘有500G,现在还剩200G ,但是我创建文件的时候提示我硬盘空间不敷?
答:一样平常情形是由于inode号不敷
3、容灾
数据存放在集群中,可能由于网络缘故原由或者做事器硬件缘故原由造成访问失落败,最好采取副本(replication)机制,把数据同时备份到多台做事器中,这样数据就安全了,数据丢失或者访问失落败的概率就小了。
4、异地容灾?
答:不同的地域,构建一套或者多套相同的运用或者数据库,起到灾害后急速接管的浸染。
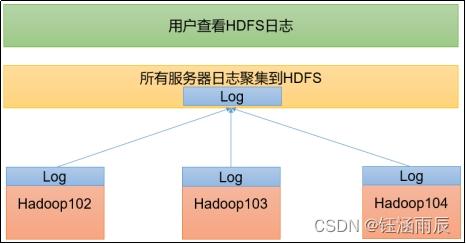
在 hadoop 中,分布式存储系统称为 HDFS(hadoop distributed file system)。个中,主节点称为名字节点(namenode),从节点称为数据节点(datanode)。
流程:
1:首先,客户端要求查看数据,要求先访问namenode
2:nomenode根据你的需求,见告你数据存储在那些datanode上
3:客户端直接和从节点联系,获取数据
分布式打算
对数据进行处理时,我们会把数据读取到内存中进行处理。如果我们对海量数据进行处理,比如数据大小是 100GB,我们要统计文件中一共有多少个单词。要想把数据都加载到内存中险些是不可能的,称为移动数据。
那么是否可以把程序代码放到存放数据的做事器上呢?由于程序代码与原始数据比较,一样平常很小,险些可以忽略的,以是省下了原始数据传输的韶光了。现在,数据是存放在分布式文件系统中,100GB 的数据可能存放在很多的做事器上,那么就可以把程序代码分发到这些做事器上,在这些做事器上同时实行,也便是并行打算,也是分布式打算。这就大大缩短了程序的实行韶光。我们把程序代码移动数据节点的机器上实行的打算办法称为移动打算。
分布式打算须要的是终极的结果,程序代码在很多机器上并行实行后会产生很多的结果,因此须要有一段代码对这些中间结果进行汇总。Hadoop中的分布式打算一样平常是由两阶段完成的。
第一阶段卖力读取各数据节点中的原始数据,进行初步处理,对各个节点中的数据求单词数。然后把处理结果传输到第二个阶段,对个节点结果进行汇总,产生终极结果。
在hadoop中,分布式打算部分称为MapReduce。
MapReduce 是一种编程模型,用于大规模数据集(大于1TB)的并走运算。观点\"大众Map(映射)“和\"大众Reduce(归约)”,和它们的紧张思想,都是从函数式编程措辞里借来的,还有从矢量编程措辞里借来的特性。它极大地方便了编程职员在不会分布式并行编程的情形下,将自己的程序运行在分布式系统上。
分布式打算角色
主节点:作业节点(jobtracker)
从节点:任务节点(tasktracker)
在任务节点当中,运行第一阶段的代码称为map任务(map task ) ,运行第二阶段代码称为 reduce任务(reduce task)
名词阐明:
1)hadoop: apache 开源的分布式框架
2)HDFS:hadoop的分布式文件系统
3)NameNode: Hadoop HDFS 元数据主节点做事器,卖力保存datenode文件存储元数据信息,这个做事器时单点的。
4) obtracker: hadoop的map/reduce调度器,卖力与任务节点通信分配打算任何并跟踪任务进度,这个做事器也是单点的。
5)DataNode: Hadoop的数据节点,卖力存储数据
6)tasktracker: hadoop的调度程度,卖力map和reduce的任务的启动和实行
hadoop集群搭建
1)环境
配好IP,关闭iptables, 关闭selinux,配置hosts
[root@ chenc01 ~]# service iptables stop[root@ chenc01 ~]# setenforce 0[root@ chenc01 ~]# vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain610.0.0.61 chenc0110.0.0.62 chenc0210.0.0.63 chenc03
三台做事器上都要创建普通用户,hadoop,配置密码:123456
[root@ chenc01 ~]# useradd -u 8000 hadoop ; echo 123456 | passwd --stdin hadoop变动用户 hadoop 的密码 。passwd: 所有的身份验证令牌已经成功更新。
设置namenode能够无密钥登录其余两台做事器
[root@ chenc01 ~]# ssh-keygenGenerating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'.Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa.Your public key has been saved in /root/.ssh/id_rsa.pub.The key fingerprint is:f1:7c:f6:6c:81:f5:a6:2a:74:d1:f2:95:50:38:ad:6f root@chenc01.localdomainThe key's randomart image is:+--[ RSA 2048]----+| +. || + . || . .= .|| + o+.o.|| S o ++o.o|| .o.o.E || . . || . o || .. |+-----------------+[root@ chenc01 ~]# ssh-copy-id root@10.0.0.62The authenticity of host '10.0.0.62 (10.0.0.62)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '10.0.0.62' (RSA) to the list of known hosts.root@10.0.0.62's password: Now try logging into the machine, with \"大众ssh 'root@10.0.0.62'\公众, and check in: .ssh/authorized_keysto make sure we haven't added extra keys that you weren't expecting.[root@ chenc01 ~]# ssh-copy-id root@10.0.0.63The authenticity of host '10.0.0.63 (10.0.0.63)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added '10.0.0.63' (RSA) to the list of known hosts.root@10.0.0.63's password: Now try logging into the machine, with \"大众ssh 'root@10.0.0.63'\公众, and check in: .ssh/authorized_keysto make sure we haven't added extra keys that you weren't expecting.# 测试(是否能登录成功[root@ chenc01 ~]# ssh 10.0.0.62Last login: Fri Nov 29 17:15:15 2019 from 10.0.0.1
[root@ chenc01 ~]# rpm -ivh jdk-8u131-linux-x64_.rpm Preparing... ########################################### [100%] 1:jdk1.8.0_131 ########################################### [100%]Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar...# 修正/etc/profileexport JAVA_HOME=/usr/java/jdk1.8.0_131/export JAVA_BIN=/usr/java/jdk1.8.0_131/bin/export PATH=${JAVA_HOME}/bin:$PATHexport CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar# 加载[root@ chenc01 ~]# source /etc/profile# 查看java版本[root@ chenc01 ~]# java -versionjava version \"大众1.8.0_131\"大众Java(TM) SE Runtime Environment (build 1.8.0_131-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
问题:source 在数据库里还可以用来做什么?
答:导入
5)在其余两个节点安装java/jdk
[root@ chenc02 ~]# rpm -ivh jdk-8u131-linux-x64_.rpm Preparing... ########################################### [100%] 1:jdk1.8.0_131 ########################################### [100%]Unpacking JAR files... tools.jar... plugin.jar... javaws.jar... deploy.jar... rt.jar... jsse.jar... charsets.jar... localedata.jar...# 修正/etc/profileexport JAVA_HOME=/usr/java/jdk1.8.0_131/export JAVA_BIN=/usr/java/jdk1.8.0_131/bin/export PATH=${JAVA_HOME}/bin:$PATHexport CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar# 加载[root@ chenc02 ~]# source /etc/profile# 查看java版本[root@ chenc02 ~]# java -versionjava version \"大众1.8.0_131\"大众Java(TM) SE Runtime Environment (build 1.8.0_131-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
Hadoop 安装目录:/home/hadoop/hadoop-3.13 利用 root 帐号将 hadoop-3.1.3.tar.gz 上传到做事器,并且放到/home/hadoop下!
[root@ chenc01 ~]# su - hadoop[hadoop@ chenc01 ~]$ mkdir -p /home/hadoop/dfs/name /home/hadoop/dfs/data /home/hadoop/tmp[hadoop@ chenc01 ~]$ rz[hadoop@ chenc01 ~]$ whoami hadoop[hadoop@ chenc01 ~]$ lsdfs hadoop-3.1.3.tar.gz tmp解压
[hadoop@ chenc01 ~]$ tar xvf hadoop-3.1.3.tar.gz[hadoop@ chenc01 ~]$ cd hadoop-3.1.3[hadoop@ chenc01 hadoop-3.1.3]$ lltotal 200drwxr-xr-x 2 hadoop hadoop 4096 2019-09-12 12:46 bindrwxr-xr-x 3 hadoop hadoop 4096 2019-09-12 10:51 etcdrwxr-xr-x 2 hadoop hadoop 4096 2019-09-12 12:46 includedrwxr-xr-x 3 hadoop hadoop 4096 2019-09-12 12:46 libdrwxr-xr-x 4 hadoop hadoop 4096 2019-09-12 12:46 libexec-rw-rw-r-- 1 hadoop hadoop 147145 2019-09-04 17:31 LICENSE.txt-rw-rw-r-- 1 hadoop hadoop 21867 2019-09-04 17:31 NOTICE.txt-rw-rw-r-- 1 hadoop hadoop 1366 2019-09-04 17:31 README.txtdrwxr-xr-x 3 hadoop hadoop 4096 2019-09-12 10:51 sbindrwxr-xr-x 4 hadoop hadoop 4096 2019-09-12 13:08 share[hadoop@ chenc01 hadoop-3.1.3]$ cd /home/hadoop/hadoop-3.1.3/etc/hadoop/[hadoop@ chenc01 hadoop]$ pwd/home/hadoop/hadoop-3.1.3/etc/hadoop[hadoop@ chenc01 hadoop]$ lshadoop-env.sh # java的环境变量yarn-env.sh # 制订yarn框架的Java运行环境slaves # 指定datanode数据存储做事器core-site.xml # hadoop-web界面路径hdfs-site.xml # 文件系统的配置文件mapred-site.xml # mapreducer 任务配置文件yarn-site.xml # yarn框架配置,紧张一些任务的启动位置修正文件
[hadoop@ chenc01 hadoop]$ vim hadoop-env.shexprot JAVA_HOME=/usr/java/jdk1.8.0_13[hadoop@ chenc01 hadoop]$ vim yarn-env.shJAVA_HOME=/usr/java/jdk1.8.0_131[hadoop@ chenc01 hadoop]$ vim slaveschenc02chenc03
备注:这个是hadoop的核心配置,这里须要配置两属性, fs.default.name 配置hadoop的HDFS系统命令,位置为主机的9000端口, hadoop.tmp.dir 配置haddop的tmp目录的根位置。
[hadoop@ chenc01 hadoop]$ vim core-site.xml<configuration><property> <name>fs.defaultFS</name> <value>hdfs://chenc01:9000</value></property><property> <name>io.file.buffer.size</name> <value>131072</value></property><property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> <description>Abase for other tmporary directries.</description></property></configuration>
备注:HDFS紧张的配置文件, dfs.http.address配置了hdfs的http的访问位置;
dfs.replication 配置文件的副本,一样平常不大于从机个数。
[hadoop@ chenc01 hadoop]$ vim hdfs-site.xml<configuration><property><configuration><property> <name>dfs.namenode.secondary.http-address</name> <value>chenc01:9000</value></property><property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/dfs/name</value></property><property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/dfs/data</value></property><property> <name>dfs.replication</name> <value>2</value></property><property> <name>dfs.webhdfs.enabled</name> <value>true</value></property></configuration>
备注:这个是mapreduce任务配置文件,mapreduce.framework.name 属性下配置yarn,
mapred.map.tasks和mapred.reduce.tasks 分别为map和reduce 的任务数。同时指定hadoop历史做事器hsitoryserver
我们可以通过historyserver查看mapreduce的作业记录,比如用了多少个map,用了多少个reduce,作业启动韶光,作业完成韶光。默认清空下,hadoop历史做事器是没有启动的,我们须要通过命令来启动。
[hadoop@ chenc01 ~]$ /home/hadoop/hadoop-3.1.3/sbin/mr-jobhistory-daemon.sh start historyserver/home/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh: line 39: exprot: command not foundWARNING: Use of this script to start the MR JobHistory daemon is deprecated.WARNING: Attempting to execute replacement \"大众mapred --daemon start\"大众 instead.WARNING: /home/hadoop/hadoop-3.1.3/logs does not exist. Creating.[hadoop@ chenc01 hadoop]$ vim mapred-site.xml<configuration><property> <name>mapreduce.framework.name</name> <value>yarn</value></property><property> <name>mapreduce.jobhistory.address</name> <value>chenc01:10020</value></property><property> <name>mapreduce.jobhistory.webapp.address</name> <value>chenc01:19888</value></property></configuration>
备注:yarn框架的配置,紧张是一些任务的启动位置
[hadoop@ chenc01 hadoop]$ vim yarn-site.xml<configuration><!-- Site specific YARN configuration properties --><proetry> <name>yarn.nodemanager.aux-service</name> <value>mapreduce_shuffle</value></proetry><proetry> <name>yarn.nodemanager.uax-service.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapreduced.ShuffleHandle</value></proetry><proetry> <name>yarn.resoucemanager.address</name> <value>chenc01:8032</value></proetry><proetry> <name>yarn.resourcemanager.shceduler.address</name> <value>chenc01:8030</value></proetry><proetry> <name>yarn.resourcemanager.resource-tracker.address</name> <value>chenc01:8031</value></proetry><proetry> <name>yarn.resourcemanager.admin.address</name> <value>chenc01:8033</value></proetry><proetry> <name>yarn.resourcemanager.webapp.address</name> <value>chenc01:8088</value></proetry></configuration>datanode配置文件天生
[hadoop@ chenc01 hadoop]$ scp -r /home/hadoop/hadoop-3.13 hadoop@chenc02:~/The authenticity of host 'chenc02 (10.0.0.62)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'chenc02,10.0.0.62' (RSA) to the list of known hosts.hadoop@chenc02's password: /home/hadoop/hadoop-3.13: No such file or directory[hadoop@ chenc01 hadoop]$ scp -r /home/hadoop/hadoop-3.13 hadoop@chenc03:~/The authenticity of host 'chenc03 (10.0.0.63)' can't be established.RSA key fingerprint is 9b:57:b9:86:84:90:a4:4b:44:3e:18:9f:8a:29:6f:e5.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'chenc03,10.0.0.63' (RSA) to the list of known hosts.hadoop@chenc03's password: /home/hadoop/hadoop-3.13: No such file or directorynamenode格式化数据:
一样平常第一次的时候须要初始化,之后就不须要了
[hadoop@ chenc01 ~]$ cd /home/hadoop/hadoop-3.1.3/bin/[hadoop@ chenc01 bin]$ ./hdfs namenode -format2020-03-04 16:05:17,247 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 393 bytes saved in 0 seconds .2020-03-04 16:05:17,268 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 02020-03-04 16:05:17,277 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.2020-03-04 16:05:17,278 INFO namenode.NameNode: SHUTDOWN_MSG: /SHUTDOWN_MSG: Shutting down NameNode at xinsz08-1/192.168.1.18/查看是否天生相应的内容
[hadoop@ chenc01 ~]$ cd /home/hadoop/dfs/[hadoop@ chenc01 dfs]$ lsdata name[hadoop@ chenc01 dfs]$ tree.├── data└── name └── current ├── fsimage_0000000000000000000 ├── fsimage_0000000000000000000.md5 ├── seen_txid └── VERSION3 directories, 4 files配置免密要登录
[hadoop@ chenc01 dfs]$ ssh-keygenGenerating public/private rsa key pair.Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa.Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.The key fingerprint is:cf:4f:4e:5e:8a:4f:7e:86:e9:f6:8c:8f:77:b9:69:50 hadoop@chenc01.localdomainThe key's randomart image is:+--[ RSA 2048]----+| || || || E || S . || o . || o +oo .|| X++oo|| .+@=+.|+-----------------+[hadoop@ chenc01 dfs]$ ssh-copy-id chenc02[hadoop@ chenc01 dfs]$ ssh-copy-id chenc01 # 对自己也做一次[hadoop@ chenc01 dfs]$ ssh-copy-id chenc03
备注:方便后期复制文件或者启动做事。由于namenode启动时候,会链接到datanode上启动对应的做事。
启动hdfs[hadoop@ chenc01 dfs]$ /home/hadoop/hadoop-3.1.3/etc/hadoop报错:2020-03-04 16:16:45,394 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable解答:http://dl.bintray.com/sequenceiq/sequenceiq-bin/ 下载对应版本解压,覆盖hadoop下/lib/native/上传之后解压:[hadoop@ chenc01 ~]$ cd hadoop-3.1.3/lib/native/[hadoop@ chenc01 native]$ lsexamples libhadoop.so libhdfs.a libnativetask.alibhadoop.a libhadoop.so.1.0.0 libhdfs.so libnativetask.solibhadooppipes.a libhadooputils.a libhdfs.so.0.0.0 libnativetask.so.1.0.0[hadoop@ chenc01 native]$ rz[hadoop@ chenc01 native]$ tar xf hadoop-native-64.tar [hadoop@ chenc01 native]$ lsexamples libhadoop.so.1.0.0 libnativetask.ahadoop-native-64.tar libhadooputils.a libnativetask.solibhadoop.a libhdfs.a libnativetask.so.1.0.0libhadooppipes.a libhdfs.solibhadoop.so libhdfs.so.0.0.0
覆盖完之后重启
关闭之后在启动
[hadoop@ chenc01 ~]$ cd /home/hadoop/hadoop-3.1.3/etc/hadoop/[hadoop@ chenc01 hadoop]$ ../../sbin/stop-dfs.sh启动yarn
也便是说我们要启动 分布式打算
[hadoop@ chenc01 hadoop]$ ../../sbin/start-yarn.sh[hadoop@ chenc01 hadoop]$ ../../sbin/start-all.sh启动jobhistory
[hadoop@ chenc01 hadoop]$ ../../sbin/mr-jobhistory-daemon.sh start historyserverWeb查看集群状态
浏览器输入http://10.0.0.61:8088/cluster















