
如需转载请附上本文源链接!
词性标注(Part-of-Speech Tagging, POS Tagging)是自然措辞处理(NLP)中的一项根本任务,旨在为文本中的每个单词分配一个词性标签,如名词、动词、形容词等。本文将详细先容如何利用Python实现词性标注,帮助你快速入门并节制基本的开拓技能。

词性标注的紧张任务是通过机器学习模型为文本中的每个单词分配一个词性标签。我们将利用Python进行开拓,并结合NLTK(Natural Language Toolkit)和Scikit-learn等库。
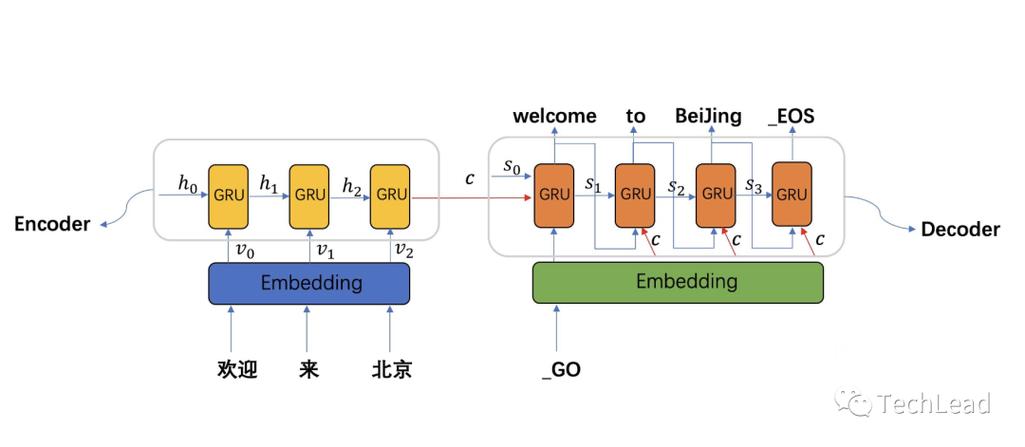
在开始项目之前,我们须要配置开拓环境。以下是所需的紧张工具和库:
Python 3.xNLTKScikit-learnNumPyPandas安装这些库可以利用以下命令:
pip install nltk scikit-learn numpy pandas三、数据准备
为了演习机器学习模型,我们须要准备标注好的文本数据。常用的数据集包括NLTK自带的treebank数据集。本文将以该数据集为例。
下载数据集import nltknltk.download('treebank')nltk.download('universal_tagset')加载数据集
from nltk.corpus import treebank# 加载数据sentences = treebank.tagged_sents(tagset='universal')print(sentences[:2])四、数据预处理
在演习模型之前,我们须要对数据进行预处理,包括特色提取和标签编码。
import numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import LabelEncoder# 提取特色和标签def extract_features_and_labels(sentences): features = [] labels = [] for sentence in sentences: for word, tag in sentence: features.append(word) labels.append(tag) return features, labels# 示例features, labels = extract_features_and_labels(sentences)# 标签编码label_encoder = LabelEncoder()labels_encoded = label_encoder.fit_transform(labels)# 将数据分为演习集和测试集X_train, X_test, y_train, y_test = train_test_split(features, labels_encoded, test_size=0.2, random_state=42)五、构建和演习机器学习模型
我们将利用朴素贝叶斯分类器来进行词性标注。
特色提取from sklearn.feature_extraction.text import CountVectorizer# 利用CountVectorizer将单词转换为特色向量vectorizer = CountVectorizer()X_train_vectorized = vectorizer.fit_transform(X_train)X_test_vectorized = vectorizer.transform(X_test)演习模型
from sklearn.naive_bayes import MultinomialNB# 构建和演习朴素贝叶斯模型model = MultinomialNB()model.fit(X_train_vectorized, y_train)六、模型评估
演习完成后,我们须要评估模型的性能。
from sklearn.metrics import classification_report# 预测测试集y_pred = model.predict(X_test_vectorized)# 评估模型report = classification_report(y_test, y_pred, target_names=label_encoder.classes_)print(report)七、词性标注
利用演习好的模型进行词性标注。
# 词性标注函数def pos_tagging(model, vectorizer, label_encoder, sentence): words = sentence.split() words_vectorized = vectorizer.transform(words) tags_encoded = model.predict(words_vectorized) tags = label_encoder.inverse_transform(tags_encoded) return list(zip(words, tags))# 示例sentence = "The quick brown fox jumps over the lazy dog"tagged_sentence = pos_tagging(model, vectorizer, label_encoder, sentence)print(tagged_sentence)八、项目文件构造
为了更好地组织项目文件,我们建议利用以下构造:
POS_Tagging_Project/│├── main.py # 主程序文件└── data/ # 数据文件夹(如有须要)九、总结
通过本文的先容,我们详细讲解了如何利用Python和机器学习技能实现词性标注。从环境配置、数据准备、模型演习到词性标注,每一步都进行了详细解释。希望这篇教程能帮助你更好地理解和实现词性标注系统。如果你有任何问题或建议,欢迎在评论区留言。
祝你在词性标注的开拓道路上取获胜利!















